往期文章
专栏文章 质量保障系统的落地实践 (一) 概览篇
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 基础信息与缺陷信息设计
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 代码信息设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 基础设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 集成设计
专栏文章 质量保障系统的落地实践 (四) 效能管理设计 - 造数工厂
专栏文章 质量保障系统的落地实践 (五) 可视化设计
专栏文章 质量保障系统的落地实践 (六) 拓展延伸
专栏文章 质量保障系统的落地实践 (七)-AI 落地&指标评估
最终成果
本篇文章将介绍一下几个 AI 赋能的场景的实践:
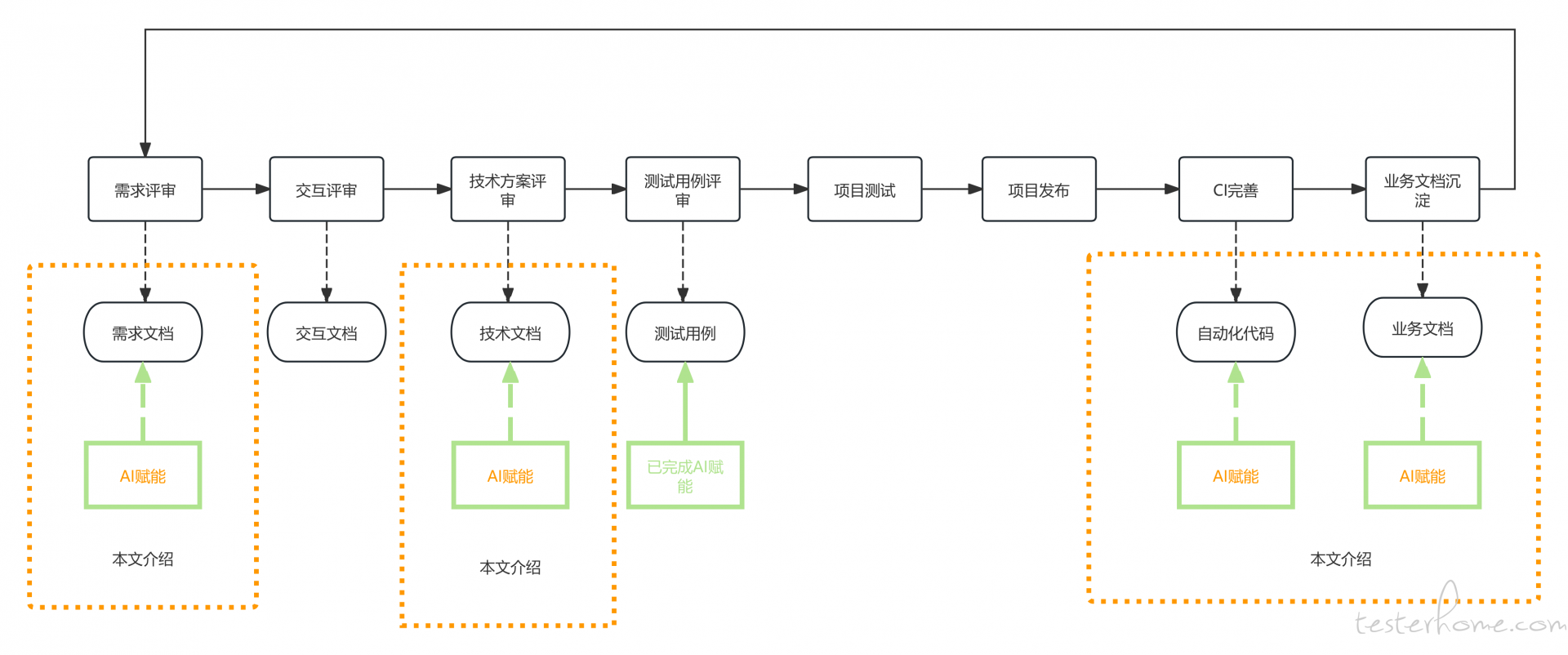
AI 赋能需求文档产生测试用例:
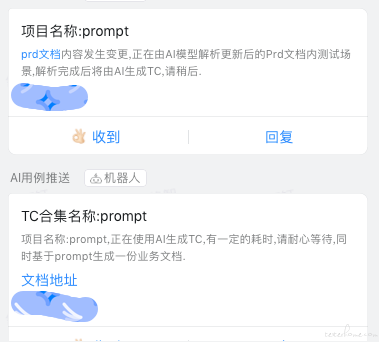

AI 赋能自动化:
前言
大家好,我是困学。很荣幸,上次发出的文章:专栏文章 质量保障系统的落地实践 (七)-AI 落地&指标评估被论坛推荐了,也收到了一些同学们的留言反馈,大家讨论比较集中的点在于:若是需要将测试点一一录入,再生成测试用例,是否真的提效?或者说的更直接一些,AI 编写测试用例是否有用?
就我所在团队使用的 AI 模型所产出的测试用例,占比能达到 30%-40%。并且生成的内容可用性也较高,但是不可避免的是测试人员需要对 AI 生成的测试用例进行润色。这部分手动工作无法被省略的根本原因在于:AI 并不清楚业务的上下文,所以他能做的,只是尽可能丰富你给出的测试场景派生出的测试用例,弥补上下文的不足则是测试人员的核心竞争力,也是测试人员很难被 AI 完全替代的护城河。有了这个基本观点,再回头看 AI 编写测试用例是否有用这个问题,就不难回答了,AI 替代不了测试人员,AI 只能赋能测试人员,一定程度上解放测试人员。
AI 赋能左移与右移的可行性分析
上一篇文章中,介绍了 AI 赋能中的一块内容:编写测试用例。那么 AI 还能在别的环节中赋能测试岗位吗?是有的,还是以我当前的实际项目为例,与大家分享。
我们先回到这张图:
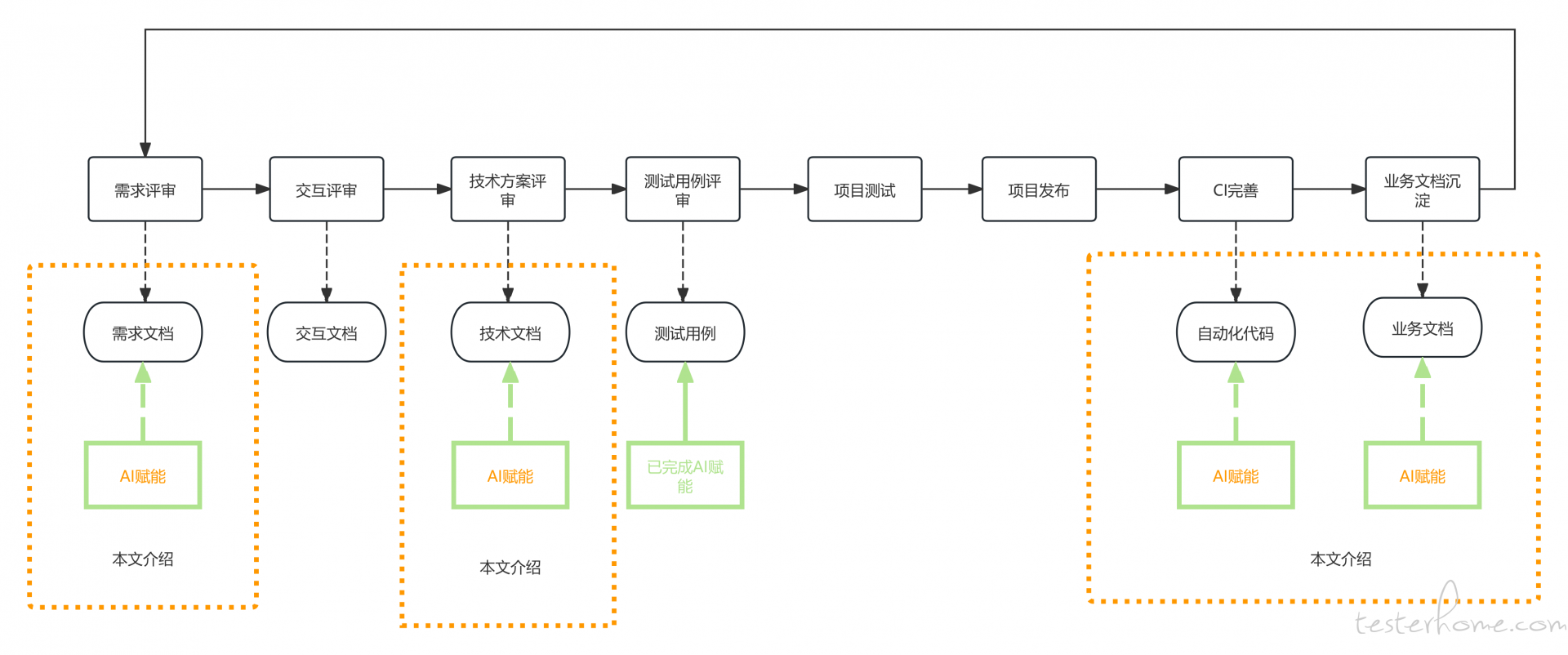
测试人员的工作流程一般可以归为上图的阶段,每个阶段各有各的产出:需求阶段的产出是需求文档,交互阶段的产出是交互文档/设计稿等等。目前已经实现了AI 赋能测试用例的功能,那么比较自然地能考虑到 AI 能否进行左移、右移?答案是可以的。
首先,产品经理产出的需求文档,设计师产出的交互文档/设计稿是为了描述清楚需求的场景以及页面关联,前后端开发产出的技术文档是为了描述需求背后的技术细节。以上的内容到了测试人员这,测试人员要做的就是从这些资料中提取出测试场景,基于提炼后的测试场景,手动编写测试用例。
而现在已经实现了 AI 基于测试场景编写测试用例的功能:
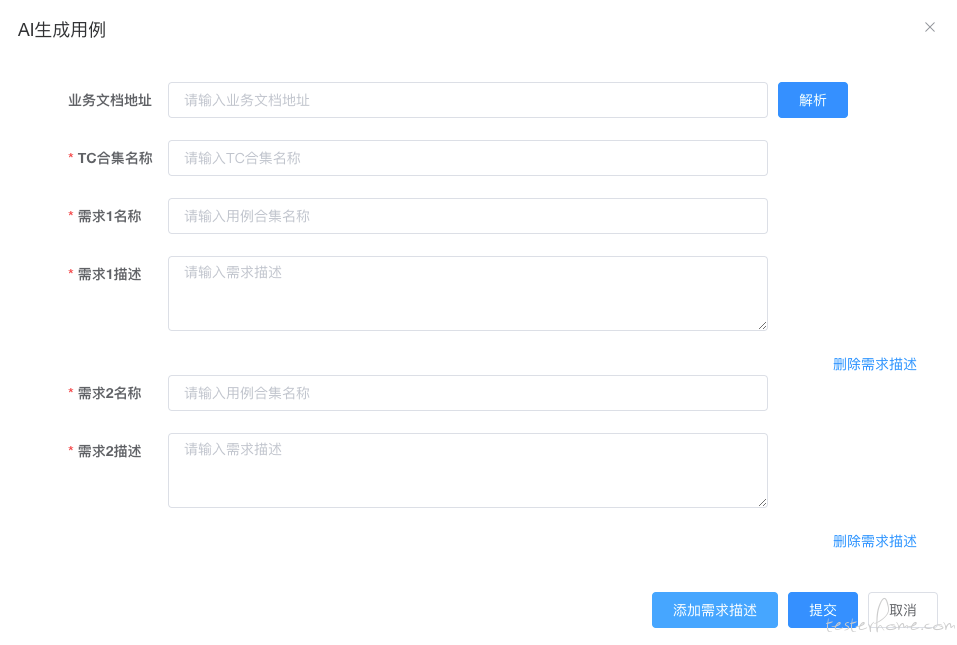
那么只要考虑如何将这几份材料的内容提取成测试场景,是不是就可以实现AI 赋能左移?
等到项目发布后,测试人员需要补充自动化脚本,对于脚本的编写,尽管场景、接口不同,但是大体上编写格式是一致,是可以抽象出一定的规则,以我司的 RobotFramework 为例:
api 层:

关键字层:

TC 层:

以上的每一层都可以抽象成这样的模板,然后动态生成。而这种相对复杂 (可清楚描述),规则明确的部分,就很适合 AI 来执行。
至于最后业务文档的沉淀,基本上是记录需求核心测试点,核心逻辑,而这些内容其实在测试场景的梳理过程中已经输出了,只是在测试过程中没有沉淀下来,需要后期去补充,而这一部分也完全可以通过非手工的方式实现。
至此AI 赋能右移的可行性也分析完成了。
AI 赋能左移 - 需求文档
测试人员在阅读需求文档的过程中,主要做了几件事:1、过滤无效描述,如需求背景、需求目标、版本说明等信息;2、提取有效正文,如功能点的描述、表单描述、附件等信息;3、基于有效正文梳理测试点;4、基于测试点,生成测试场景。
而这个过程是可以交付 AI 执行的,因为这些流程可以通过语言描述,使得 AI 理解我们的目的 (当然,也要选择合适的 AI 模型)。
我司的需求文档以语雀维护,通过语雀的 api,可以拿到整篇文章的 html 结构。接下来我们只需要描述清楚 prompt,就可以交付 AI 帮助我们提炼测试场景:
1. 从HTML文档中,仅提取标题为"需求说明"板块下的所有正文内容。 # 过滤无效描述
2. 排除其他标题下的任何正文内容,不对其进行分析。 # 过滤无效描述
3. 如果在"需求说明"板块内遇到表格:
- 忽略表格的第一行(通常是表头)。 # 过滤无效描述
- 提取表格的第一列和最后一列的内容,作为正文内容的一部分。 # 提取有效正文
4. 基于提取到的正文内容,尽可能详尽地分析出以下信息: # 梳理测试点、生成测试场景
- "需求测试点":根据内容总结出的需求关键点。
- "测试场景":为每个需求测试点设计具体的测试场景,按次序分点列出,格式如下:
1. 测试场景1:......
2. 测试场景2:......
3. 测试场景3:......
多个场景之间换行展示)
5. 将每个"需求测试点"及其对应的"测试场景"按照以下格式组织成一个JSON对象: # 格式化输出
- {"name": "需求测试点", "description": "测试场景"}
6. 将所有生成的JSON对象append至一个数组中。
7. 支持分段输出:如果内容较多,可以分段输出,但每段输出的内容前后不要加任何分割符,确保最终拼接后是一个完整的、标准的JSON数组,内部不包含其他内容。
8. 最终仅返回该数组内容,输出结果不使用```json及```包裹,输出结果需为标准JSON格式。
那么为什么要以这样的格式:{"name": "需求测试点", "description": "测试场景"}输出呢?那是出于体系化的考虑,需求文档中提炼出的测试场景完全可以用于生成初版测试用例,注意,这里说的是初版,结合上已经实现了的测试场景生成测试用例的功能:
只需要 for 循环这个 AI 返回的数组内容,就可以直接渲染出一个测试场景表单:

这样一来,就直接打通了AI 解析需求文档与AI 基于测试场景生成测试用例两个功能之间的壁垒。
AI 赋能右移 - 业务文档
既然 AI 解析需求文档的功能已经实现了,测试点也被梳理了,其实只要在这个阶段,将这些内容保存下来,就可以作为初版业务文档,注意,还是初版。
我司使用语雀维护业务文档,所以使用对应的 api 创建业务文档:
# 封装业务文档信息
document_body = ""
for index, child_description in enumerate(child_descriptions):
try:
name = child_description["name"]
description = child_description["description"]
mark_uuid = child_description.get("mark_uuid", None)
except KeyError:
continue
document_body += f"### {name}\n{description}\n\n\n\n"
document_data = createDocument(group_login, book_slug, root_description, document_body)
doc_slug = document_data["slug"]
document_url = f"{YUQUE_HOST}/{group_login}/{book_slug}/{doc_slug}"
updateDocument(group_login, book_slug, doc_slug, root_description, document_body)
若是手动修改了测试场景,也需要同步至业务文档中:
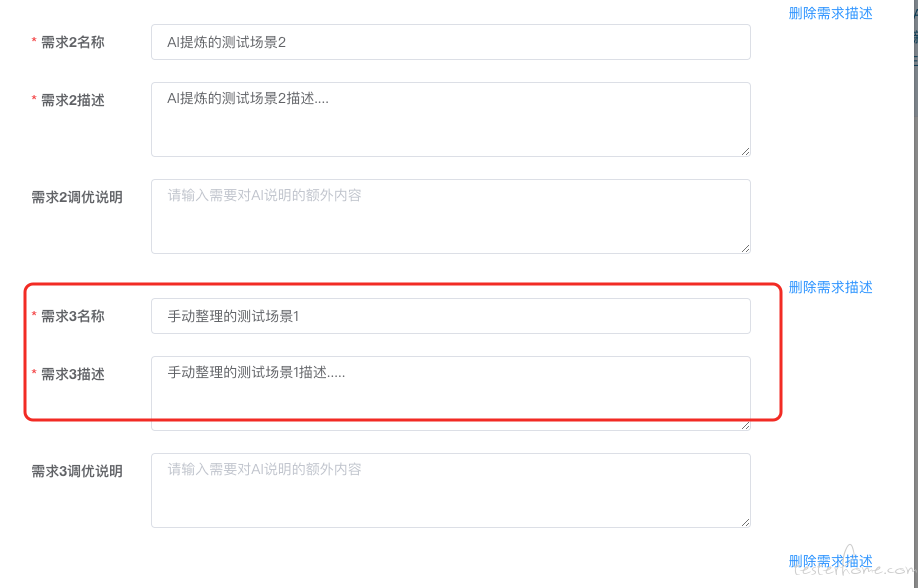

AI 赋能右移 - 自动化
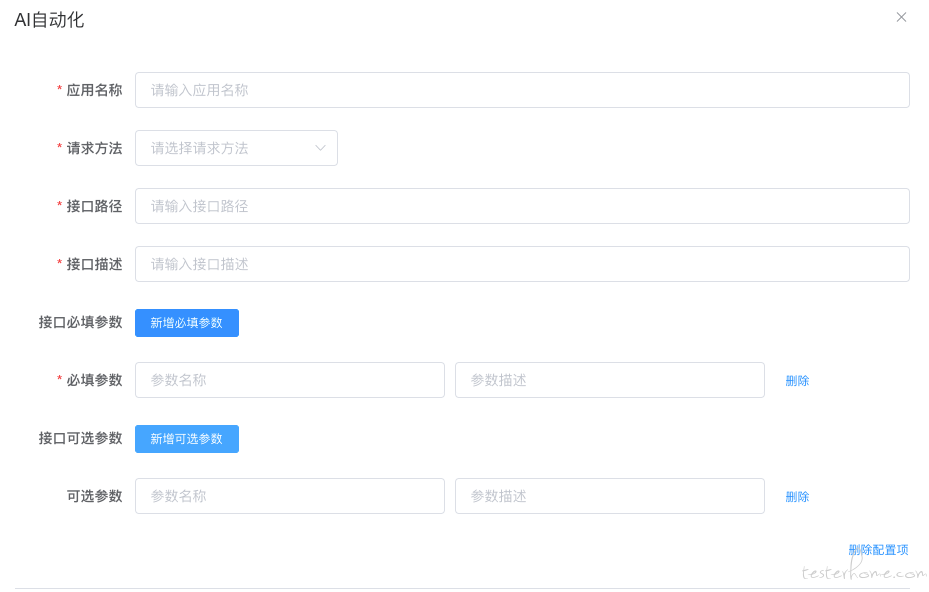
回到这三张图,要实现 AI 赋能自动化,实现的过程也比较简单,主要是 prompt 的描述:
api 层:
关键字层:
TC 层:
prompt:
请根据以下模板和数据,生成完整的 Robot Framework 测试套件,包括 Keywords 和 Test Case 部分。
数据以数组形式传入,动态生成内容,并确保后缀为 -api 的关键字排在最前面,其次是 -keyword 后缀的关键字,最后是 -TC 后缀的测试套件。
要求:
1、去重规则:
- 如果传入的数据中,"session别名"、"domain"、"请求方法" 和 "接口路径" 相同,则只生成一个 -api 后缀的关键字。
- 该 -api 后缀的关键字以 "session别名"、"domain"、"请求方法" 和 "接口路径" 的组合作为唯一标识。
2、复用规则:
- 在生成 -keyword 后缀的关键字时,复用相同的 -api 后缀关键字。
- 根据 "接口描述" 的不同,生成多个 -keyword 后缀的关键字,但调用同一个 -api 后缀的关键字。
3、测试套件规则:
- 每个 -keyword 后缀的关键字都必须有一个对应的 -TC 后缀的测试套件。
- 测试套件的数量与 -keyword 后缀的关键字数量保持一致。
4、动态生成:
- 根据传入的数据,动态生成 -api、-keyword 和 -TC 后缀的关键字。
- 排序规则:
- 所有后缀为 -api 的关键字排在最前面。
- 其次是 -keyword 后缀的关键字。
- 最后是 -TC 后缀的测试套件。
5、模板规则:
- 在 API 请求模板 中:
- 如果 "请求方法" 为 Get 请求(忽略大小写),使用第一套模板。
- 否则,统一使用第二套模板。
- 替换 ${domain}、${接口描述}、${请求方法}、${session别名}、${接口路径} 为实际值。
- 在 Keyword 模板 中:
- 替换 ${api请求关键字} 为对应的 API 请求模板 生成的关键字名称。
- 将数据校验部分的 ${接口变量名} 替换为 "接口参数列表" 中的每个参数,并展开为多条独立的校验语句。
- 在 Test Case 模板 中:
- 替换 ${接口描述} 为实际值。
- 将 ${request_data} 的构造部分展开为平铺的键值对形式(如 name=、age=、gender=)。
- 替换 ${keyword请求关键字} 为对应的 Keyword 模板 生成的关键字名称。
6、输出格式:
- 支持分段输出:如果内容较多,可以分段输出,但每段输出的内容前后不要加任何分割符,确保最终拼接后是完整的可执行的RobotFramework文件,内部不包含其他内容。
- 禁止使用```robot及```包裹输出结果
我们要做的就是整理出交付给 AI 的数据结构:
prompt_data = []
prompt_item = {
"接口描述": description,
"请求方法": method,
"session别名": domain,
"domain": domain,
"接口路径": path,
"接口参数列表": all_params_name_list
}
prompt_data.append(prompt_item)
# 封装最终的prompt
prompt = f"""
{ci_prompt}\n
数据:{prompt_data_}\n
返回最终生成结果
"""
实现效果:
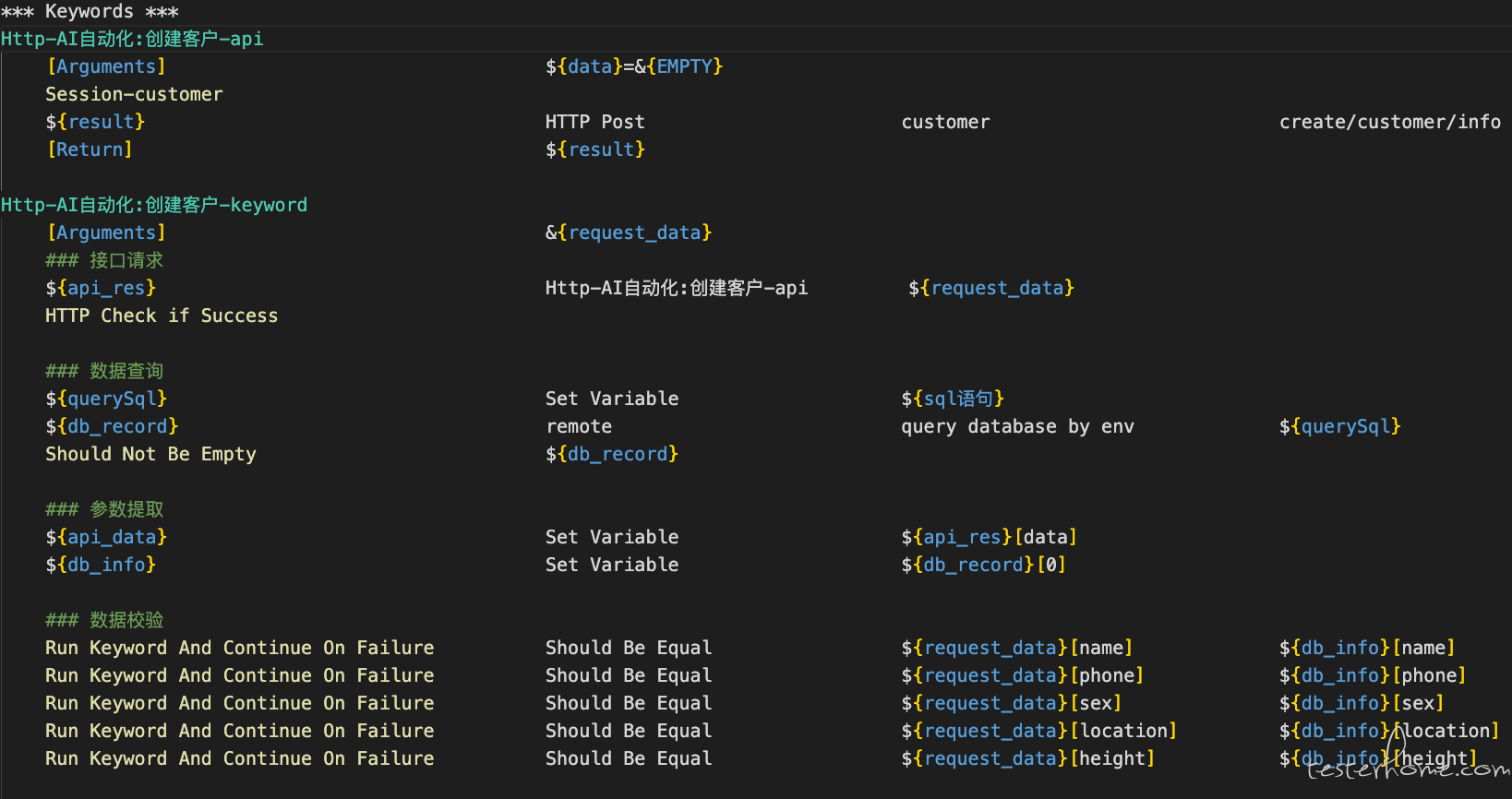

AI 赋能左移 - 技术文档
测试人员阅读技术文档,目的更多的是确定研发的实现方案会不会有风险,如是否使用缓存,使用 ES 等技术手段,基于技术文档编写测试用例的比例不高,所以在我的实践过程中,技术文档更多的是为后续的自动化代码服务。若是写的完善、规范的技术文档 (注意,是完善、规范的技术文档),此次需求中涉及的新增、改造接口均已列明,有了前面处理需求文档的实践,处理技术文档的方式也是类似的,编写对应的 prompt 提取出接口信息和参数信息,交付给 AI 生成自动化脚本的功能即可。
但是更多的时候,技术文档描述并不会那么详尽,那么还有没有别的方式可以获得项目周期内新增的接口呢?
以我司的实际情况为例,我司支持后端的多环境部署,每个环境内部署的代码分支不同,通过比较多环境内服务的 swagger 接口和基准环境内服务的 swagger 接口的差集,就可以获得本次需求涉及的新增接口。
这种方式也还是有一定缺陷的,比如修改的接口无法直接比对出来,需要人工介入。
总结
本篇文章主要讲解了 AI 赋能的实现思路,很多代码无法直接分享出来。但每个公司的基础能力不同,即便给出了代码,大概率也是不能复用的。所以本篇文章更多的是分享实现思路,想要AI 赋能,本质上要做的就两件事:1、这件事可以被语言清晰描述,规则明确,prompt 可以高质量的输出;2、找到合适的模型。
这两件事中,更重要的是第一点,就拿我当前正在尝试的使用交互稿生成测试用例的功能来说,prompt 清晰描述的难度较大,原因在于交互稿的逻辑往往比较复杂,内部的元素众多,页面之间的跳转逻辑判断较多,很难通过一个比较合适的 prompt 适配各种情况的交互稿,目前还在探索。插一句题外话,能处理交互稿生成测试用例功能的视觉模型,要求比较高,目前 Qwen2.5Max 效果相对较好一些,如果各位同学有好的模型,也欢迎留言告诉我,谢谢。
最后我想说,很多同学的实践效果可能不理想,不符合自己的期望,或许只是因为没有找到合适的模型 (因为我也是在不断尝试使用不同的模型过程中,慢慢找到效果比较好的模型来实现功能的),不断尝试新的模型或许能够带来不少惊喜。
如果觉得这篇文章对你有用,请一键三连,受累了。