AI测试 请教,有没有什么好办法可以将往期数量庞大的需求和测试用例整合到知识库,用于新用例生成
处于棋牌游戏行业
1.当前已经使用 dify 搭建了测试用例生成工作流,现有存在的问题是没有上下文检索生成的测试用例比较空泛
2.将所有游戏赛制特色描述全部集成到关键词中,会导致关键词词库庞大,生成检测内容丢失且持续增加描述,也需要一个长期过程
3.使用 dify 知识库:目前正在逐步往知识库加需求和往期测试用例,但因为是初步接触 AI 且只有我一个人,文档很混乱且工作量巨大
想请教大家,有没有更好的方法可以进行整合自己的个人知识库
目前我这边用起来成本比较低的方式:
git 托管知识库,规范化和评测策划案,编写测试用例,用例输出规范等相关 Skill 和知识库文件;
然后花点钱买 claudecode 的令牌(30 块左右吧,无限额度,偶尔会抽风那种无伤大雅)每次通过多个 Agent 并行执行去批量导入文件(主要是解决上下文限制问题)。
现在的方式就是,策划案有了就导入到这套流程里,然后就去忙别的,然后他自己帮我生成相应的处理路径,但是需要我 review 下关键信息:矛盾的点啊,有分歧的内容,需要我进一步确认,然后就这样生成相应的用例了。
目前我组搭建以后已经用起来了,系统相关的测试收效甚好(写的比系统测试的小伙伴写的好,非常全,个别难以搭建的测试场景,我让他们自己斟酌),战斗需要更详细的 Skill 要求跟依赖关系(我是 ACT 类的写实战斗游戏)效果也能达到个 7788,因为搭建半个月,内容量还没起来,但是只会越来越好。
这是我目前的方式,支持迭代也支持历史批量导入生成。
这个是业界难题了,能解决的人配享太庙
也不是要一次性都解决,主要是想请教下怎么更好的设置父子上下文检索,内容可以一点点加,想先了解多个文档怎么更好的进行索引精准引用
公司都在转型,但我感觉测试转型相比研发难一些,我们可以讨论一下吗,或者请教一下呢
目前我也是自己刚开始搞,现在是借助 dify 工作流进行用例生成,当前能做的用例生成、测试点总结、邮件、图标生成流程是通的, 但是知识库把我卡住了,网上资料只找到基础配置,没有知识库用例的精准度就不会太高,没有上下文索引,现在正在摸索如何清理需求和用例,更好的整理到知识库,还没有头绪
其实现在都在说,看了很多地方,没有落地;或者说没有很好的落地。这个现在有好的解决方案不呢,或者方向
直接用现成,腾讯 IMA 的知识库。只是成本最低,正反馈最快的。
没有什么成熟的落地能直接就用的,现在可以做的就是你觉得什么比较好用,直接用,先用起来再优化,哪怕是直接用 deep 拆解需求生成一份测试用例,当你的关键词能把一份需求拆解详细,80% 可直接利用那就已经很厉害了,先点再面测试思路不也是这样的嘛,我现在的想法就是用 dify 把测试用例直接生成出来
成本最低,正反馈最快的结论是认真的吗?刚试了下,IMA 除了好安装以外,没 openapi,又要联公网,知识库内容还要上传到他司服务器,被信安发现了工作都不保。
个人用户体验一下还可以,无法想象有对于生产资料的外发限制这么宽松的公司
好深噢,我现在还在搞手工测试呢
目前我的方案是用已有的手册或者页面截图(视觉 AI 模型分析字段)分析需求生成需求文档,所有用例、操作手册都基于这个生成的需求文档来生成(生成后的需求文档还可以二次编辑),只需要保证需求文档准确性,那用例等等其他产物的准确性都能得到同步提高
不联网?你们公司有能力自己本地搭建类似 openai 模型?你是不是以为通过 api 访问,数据就不被训练?另外对于文档存储,你要去重,关键词等相关敏感要去掉。至于重要不要资料,心里都清楚。可以先问下你们领导,看从成本的投入来判断。
测试知识库感觉好难搞,尤其像我们这只有 xmind 文件,感觉都不知道用什么载体搞这些
用 openai 是没得选。知识库大把可以选的,大把可以离线部署商用的。
IMA 还要自己去重和脱敏,成本一点都不低,明显就不是面向商用的。真不如装个 Milvus,离线,同时不用人工去重和脱敏
目前我这边用起来成本比较低的方式:
git 托管知识库,规范化和评测策划案,编写测试用例,用例输出规范等相关 Skill 和知识库文件;
然后花点钱买 claudecode 的令牌(30 块左右吧,无限额度,偶尔会抽风那种无伤大雅)每次通过多个 Agent 并行执行去批量导入文件(主要是解决上下文限制问题)。
现在的方式就是,策划案有了就导入到这套流程里,然后就去忙别的,然后他自己帮我生成相应的处理路径,但是需要我 review 下关键信息:矛盾的点啊,有分歧的内容,需要我进一步确认,然后就这样生成相应的用例了。
目前我组搭建以后已经用起来了,系统相关的测试收效甚好(写的比系统测试的小伙伴写的好,非常全,个别难以搭建的测试场景,我让他们自己斟酌),战斗需要更详细的 Skill 要求跟依赖关系(我是 ACT 类的写实战斗游戏)效果也能达到个 7788,因为搭建半个月,内容量还没起来,但是只会越来越好。
这是我目前的方式,支持迭代也支持历史批量导入生成。
这个简直是太难了,现阶段旧版都是 xmind 维护的用例和数据,查找存储都是难办理的一个事情,
这个涉及到历史需求的质量(各种格式的需求文档,当需求有变更的时候是否及时补充到需求文档上,如果是迭代的需求,迭代的需求是否规范),测试用例的质量 等等 ,太难了。
嗯,是的。维护一个目录仓库,本地的知识库是我抽象出来的通用知识框架,产物就是一个 md 文件,但是里面会记录每次生成的 case 的依赖关系,差异化的知识清单,每次生成 case 的时候都通读知识清单里的内容。命中率挺高的。
1.请问本地的话是按照类似这种父子结果的框架产生一个总 md 文件?
├── 01_规范与标准/
│ ├── 测试用例编写规范.md (包含用例格式、优先级定义、字段说明)
│ ├── 术语表.md (例如游戏专有名词:硬直、判定框等)
├── 02_策划案与需求/
│ ├── 系统模块/ (如:背包系统、任务系统)
│ └── 战斗模块/ (你的 ACT 战斗相关策划案)
├── 03_Skill 与经验库
└── 04_模板/
└── 测试用例模板.md
2.然后在 dify 知识库中按照框架生成多个模块化知识库,比如知识库 1.规范和标准 2.策划案与需求,当有新需求生成测试用例时,使用类似 GitHub Action,自动更新 dify 知识库,用关键词调用 LLM,检索多个知识库这样来进行嘛
3..这个规范性文件是公司要求需求方小伙伴必须按照相关规定去做需求文档嘛?大家同时遵守规则嘛?还是自己清洗数据呀
1、目录结构上看起来挺像的,但是我比你的会全一些,我觉得主要你缺了一个评测模块,它的作用是,规范化这个管线模块中的内容,因为系统跟战斗是完全不同的 2 个管线,所以你要约束规范他们的产出路径。上游策划案就需要去约束(我这边会规范化以后去打分策划案,评分太低的不满足我要求的,我会直接跟主策划说,案子质量太低了这种)约束的关键词如:存在未定义的概念;案子之间存在相同名词,但是名词定义不统一;模糊的场景描述;注入此类的关键约束,约束完以后,然后再依赖按照咱自己的测试用例输出格式输出测试用例;另外我的 Skill 跟知识库是分开的,因为我的经验库(知识库)是全局的,Skill 是非全局的(局内,外围,流程,资源)这种细化的检查,模块的话,就是一级目录是模块名,二次目录就是规范化以后的策划案还有归档以后的原始稿;其他的大差不差,我后面计划还有置入自动化动作检查,但是需要有合适的视频解析的大模型;
2、我没用 dify,就是一个单纯的知识库性质的 md 文件,结构简单的,就是我上面描述的那种。我觉得自己通过依赖关系去自查就 OK 了,还有就是要有纠错逻辑,就是差异化的内容要消化在生产过程中;
3、目前非强制,但是设计框架要基本遵循,不然就太扯淡了,我们主策原话:你无法去约束每个人都按照你这样的设计结构去描述,我迄今为止没见过,那都这样说了,那按照设计框架去设计总说得过去吧?所以这边规范化策划案的流程中就是按照设计框架去解析他写的原始稿,通过走这个流程,强制把所有的策划的产出拉齐,这样就解决问题了。缺少的东西会体现出来,比如:我们设计动作的时候,会给对应匹配逻辑,资源池,动作标注的名称,衔接优化的逻辑,最终的表现解决预期这类的描述,这些都是抽象出来的。
直说的话,就是 AI 帮我们清晰数据,给一个最规范的内容。
我个人体验下来,游戏测试的用例产出能达到这个精度的话,软件测试用例就更不用说了,我感觉精度更是高的吓人了。
我们目前也是 dify 搭了 chatflow 来做用例生成,因为完全靠 ai 生成的质量还是很不达标,就先给 ai 做需求分析,然后继续人工纠正继续 prompt,然后生成用例也是,50%Ai 50% 人工吧。
请问你的问题解释了吗?我们正在做这件事,有兴趣可以试用我们的系统
我的目前还好一些,大概能到 70%,希望在我知识库搭建完后能到 80 以上,我目前是先把需求让大模型清洗一遍,然后原版需求 + 清洗完后的需求分别交给 2 个 LLM,分别进行测试点总结和需求拆解,第三个 LLM 根据原需求和测试点总结进行用例生成,感觉会更精准一些
过往需求文档都找不到的怎么解?
辛苦问个问题,我现在有个困扰,我的需求文档有很多的测试点,直接全量查询 01.目录结构(找到比如报名、开赛模块),随后我让大模型再去找第二个知识库中报名的具体内容的时候,我发现他是拿一堆关键词去知识库里匹配,相当于我拿着一本书(测试点总结)去和另一本书(知识库)在匹配相似度,会导致数据丢失很大一部分,这块是怎么处理的呀,用模糊查询,类似 msql 数据库,先搭建格外完整的体系这样嘛
内容不够聚焦,我先按照你说的内容问下我的疑惑哈:
1、你的需求文档有很多的测试点,这个需求文档是什么类型的?如果这个类型有分类的话,理论上就不会出现全量查询的情况;
2、在知识库中的设计中,可以多个,也可以单个,像我这种知识库结构只存差异化(增量迭代)的依赖关系还有编辑状态的内容,量是不大的,我就是单个的,如果是多个的话,只需要结合步骤 1 中对应的让 Skill 按照不同的需求去跳转该知识库即可,知识库的结构基本是一致的;
以上的表现带来得就是,不会出现巨量的全量更新去匹配的情况,并且 Agent 并行执行时,上下文的依赖也会解的比较小,几乎很少出现满载的情况,再不行,就只能分批写入了;
我觉得中间过程数据丢失,很大程度是你在需求文档的输出格式规范上没有做好约束,比如:我们现在需求文档,我会让他按照不同的类别输出(评审策划案)逻辑点,然后逻辑点扩散测试点,然后 review 之后产生一个规范化后(打分之后)的策划案,然后你就能通过这个需求,得到一份儿精炼过内容的一份儿规范化后的策划案(基本不会丢内容的),这样你在导入原始的策划案(prd)之后,实际上 Skill 还有知识库这些基本都是按照分治的思路一致在扩展去读你的需求,最后根据已有的内容产出一份儿还算 OK(基本不漏内容)的文件出来。
对于
1.需求文档的类型,我们是那单个功能迭代的,比如我们新增了一个已活跃分为货币的报名方案,他所涉及的测试点有活跃分报名 - 存档 - 复活 - 结算 - 再来一局 - 强制踢出房间整个流程,整个会有一个功能介绍,有些功能是往期已有的,他就会简写成一句话,新增的会比较详细的描述
我从需求中总结到的这些测试点,拿报名这部分内容举例 1.报名费用还涉及金币报名、参赛券报名、金币不足、条件不足、新增活跃分不足等情况兼容,我从我的关键词调用的时候他不是光拿报名费这一个关键词,而是我需求中多个关键词一起去知识库内进行检索,可能能检测到报名费用这块检索 tab5-10,也可能被其他的关键词所污染就会造成丢失,而我如果拆分了需求,他又不能很好的按一个个的拆分点依次去查询
2.如果是跳多个知识库的话,就比如我的复活模块,我先需要知道需求中有复活这个内容,然后手动勾选复活相关得知识库,可能能很好地调用,但是这样的知识库分的太细了,没办法根据一个工作流来达到自动识别、调用的情况
1、问题一的话,你这边应该是没去做差异化(增量迭代)的流程,导致你这边每次手动识别的时候,会存在你所描述的内容,(增量迭代)时,你需要做的是版本控制,然后去按照要求的内容做差异化内容的确认(会导出差异化内容)给你输出,然后你去从中调整这块的内容,也是可以迭代优化的 Skill,随着每次的 Skill 优化,就会越来越准,大概的样子是这样的。
当你做到这一步以后,再看下; 这个是差异化的内容,你需要 review 之后再生成,有问题即时调整,调整的逻辑可以通用化就加入到 Skill;
这个是差异化的内容,你需要 review 之后再生成,有问题即时调整,调整的逻辑可以通用化就加入到 Skill;
2、对于跳知识库这个,我还是我上面那个观点,感觉你是较多的知识库,这个我不清楚你知识库咋分的,以及知识库存在的都是什么数据,按照我这边之所以去找依赖关系,是因为存依赖关系,结构简单,跳转清晰,这样 Agent 找的时候目的明确,跳转的时候 Skill 也需要去约束;大概这个样子,我的知识库结构: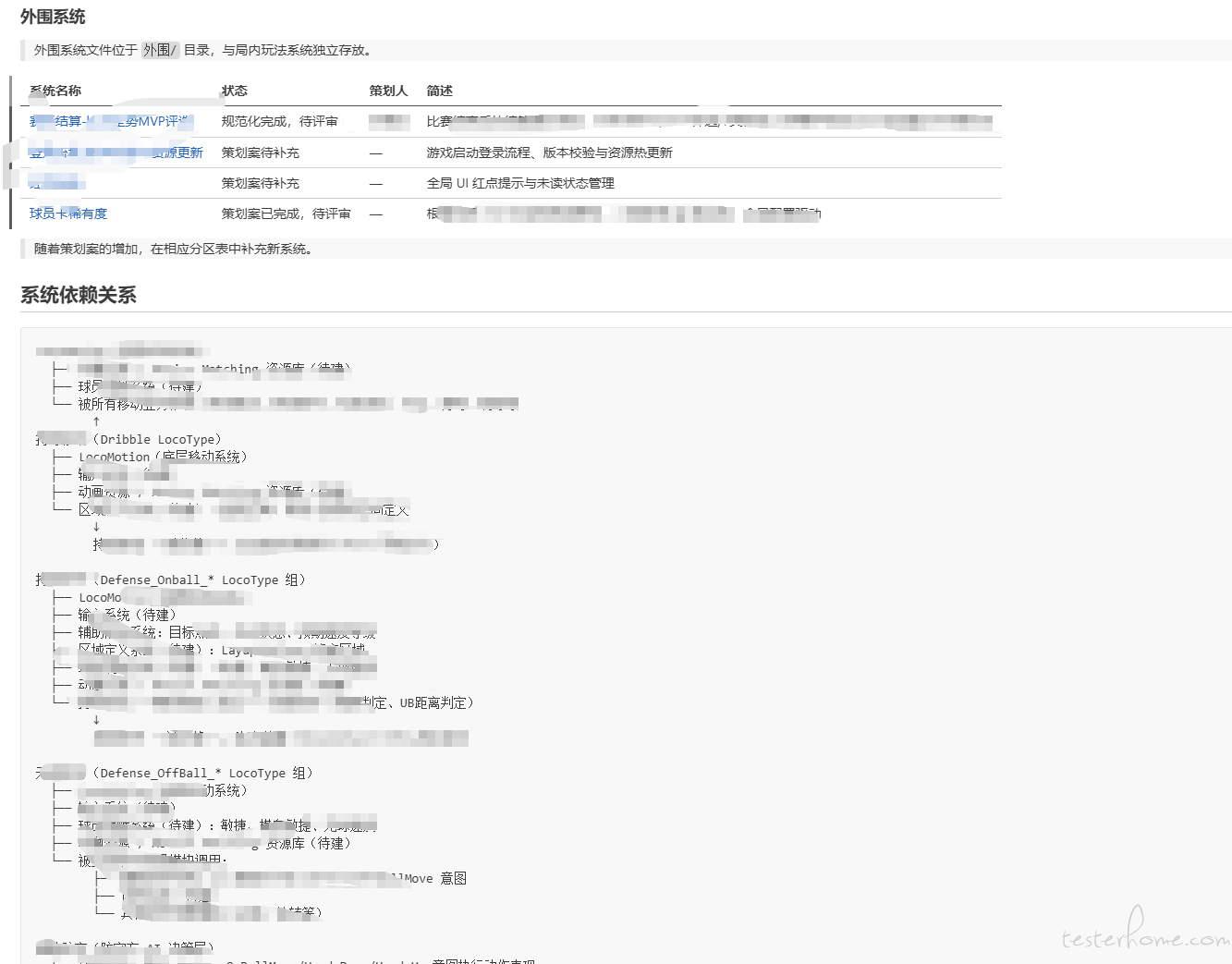 你只需要关注我这边的结构就好。
你只需要关注我这边的结构就好。