往期文章
专栏文章 质量保障系统的落地实践 (一) 概览篇
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 基础信息与缺陷信息设计
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 代码信息设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 基础设计
专栏文章 质量保障系统的落地实践 (三) CI 管理设计 - 集成设计
专栏文章 质量保障系统的落地实践 (四) 效能管理设计 - 造数工厂
专栏文章 质量保障系统的落地实践 (五) 可视化设计
专栏文章 质量保障系统的落地实践 (六) 拓展延伸
专栏文章 质量保障系统的落地实践 (七)-AI 落地&指标评估
专栏文章 质量保障系统的落地实践 (八)-AI 赋能测试岗位
最终成果
测试报告 (核心设计点):
控制台输出:

异常输出:

前言
大家好,我是困学。许久未见,祝顺遂。距离上一篇文章的输出已有些时日,这次动笔写的是"自动化框架"的主题,乍一看会比较多余。市面上的现成产品也好,大家自己手写也好,其实自动化框架的实现并不复杂,故此落笔前也有些踌躇,犹豫是否班门弄斧。借用太平年电视剧中冯道赵匡胤论做事的表达:这篇文章和之前的专栏文章一样,写出来也许有用,也许没用,有用的,没用的,终归要有人去做。能不能做成是一回事,做不做却是另一回事。事前应思是否当做,当做则做。所以就有了这篇文章。
背景
看过之前关于 CI 的文章的朋友,应该知道我司之前的自动化框架为基于 RF 二次开发的框架。它的执行依赖 VSCode 内的许多自定义插件,但是随着人员迭代,目前处于
无法维护的状态,语法相对僵硬编写方式不友好,日志冗长定位成本高,并且对于我所在事业部的统计诉求无法满足。经过讨论后,决定废弃该框架自行开发。
而开发过程则由于之前已经构建了 CI 体系,所以整体的设计思路与常规的自动化框架规划不同,最大的区别会体现在测试报告中。
自动化框架的目的
自动化框架是手段,不是目的。那么自动化的目的是什么?如果只是为了将一些接口请求场景串联起来,使用一些工具如 postman 或者直接 python 的 requests 库足以。框架只是在此之上做了更丰富的内容,更优雅的封装,但是本质上的核心依然是:1、发起请求,2、数据查询,3、数据校验,4、异常定位。
我们测试岗位写自动化脚本,不是为了做单纯的接口请求堆砌,需要借助自动化脚本来减轻我们的回归成本以及完成代码巡检保证核心功能正常流转等工作。所以最关键的因素是:数据校验,有完善的业务逻辑的数据校验,这样的脚本才是值得测试信赖的。那么在设计自动化框架时,这块功能就要当做核心点去设计。
另外,在调试、执行过程中,会遇到执行异常,校验不通过等情况,是否需要输出大量的日志来辅助定位?能否降低调试代码的成本?那就需要在异常定位的设计中考虑得更多一些。
举个实例 (数据校验&异常定位)
拿 pytest 举个例子,用 pytest 进行脚本编写时,到了数据校验环节可以使用 assert 进行比对,可以使用 pytest-assume 插件进行比对,这些都是现成的校验方法。缺点也比较明显,无法在里面嵌套上自己的逻辑,碰上这种情况,需要我们自定义校验语句。
举一个自行定义的校验语句例子:SHOULD_BE_EQUAL
def should_be_equal(self, pre_variable: Any, aft_variable: Any):
"""元素值对比相同"""
caller_name, source_line, caller_source = self._get_caller_info()
success = pre_variable == aft_variable
if not success:
logger.error(f"{caller_name}校验语句失败,{source_line},{pre_variable},{aft_variable}.")
item_keyword_result = {
"source_line": source_line,
"pre_variable": pre_variable,
"aft_variable": aft_variable,
"success": success
}
should_be_equal_item = {
"SHOULD_BE_EQUAL": item_keyword_result
}
self._update_keyword_results(caller_name, caller_source, "SHOULD_BE_EQUAL", should_be_equal_item)
SHOULD_BE_EQUAL = custom_global_functions_handler.should_be_equal
SHOULD_BE_EQUAL 校验语句中,除了做数据对比:success = pre_variable == aft_variable,增加了执行异常时的 error 日志标红输出,并且打印了实际数据,这样一来,定位异常的成本将会降低。:
其次,做了校验过程记录:item_keyword_result,这个字典里存储了 source_line-源码,success-校验语句执行是否通过,以及具体参数 pre_variable、aft_variable。
那么怎么获得源码?python 已经提供了对应的属性让我们获得源码信息:
def _get_caller_info(self) -> tuple:
"""获取调用者信息"""
caller_frame = inspect.currentframe().f_back.f_back
caller_name = caller_frame.f_code.co_name
source_line = inspect.getframeinfo(caller_frame).code_context[0].strip()
caller_source = inspect.getsource(caller_frame.f_code)
return caller_name, source_line, caller_source
最后,需要将单次的数据校验执行过程保存下来。
def _update_keyword_results(self, caller_name: str, caller_source: str, keyword_name: str, result_item: dict):
"""更新关键字结果"""
if caller_name not in KEYWORD_RESULTS:
KEYWORD_RESULTS[caller_name] = {"apis": [], "start_at": int(time.time() * 1000), "results": {"correct": [], "error": []}}
# 统计出keyword内含的apis
if not KEYWORD_RESULTS[caller_name]["apis"]:
all_http_apis = self.find_all_http_api_in_source(caller_source)
KEYWORD_RESULTS[caller_name]["apis"] = all_http_apis
# logger.info(f"{caller_name}关键字内含的apis已被记录.")
# 统计处keyword内含的校验语句
if result_item[keyword_name]["success"]:
KEYWORD_RESULTS[caller_name]["results"]["correct"].append(result_item)
else:
KEYWORD_RESULTS[caller_name]["results"]["error"].append(result_item)
以上就是一个自定义校验语句做的事。
使用以上代码生成的 KEYWORD_RESULTS 结果如下:
{
"Http_账号密码登录_keyword": {
"apis": ["Http_账号密码登录_api"],
"start_at": 1770703557251,
"results": {
"correct": [{
"HTTP_CHECK_IF_SUCCESS": {
"source_line": "HTTP_CHECK_IF_SUCCESS(api_res)",
"success": true
}
}],
"error": []
}
},
"Http_获取用户信息_keyword": {
"apis": ["Http_获取用户信息_api"],
"start_at": 1770703557365,
"inner_keywords": [],
"results": {
"correct": [{
"SHOULD_NOT_BE_EMPTY": {
"source_line": "SHOULD_NOT_BE_EMPTY(user_record)",
"variable": [{
"id": "***",
}],
"success": true
}
}],
"error": []
}
}
}
设计原因
看完上面的实现,再来谈谈为什么要这么做。目的是为了引入CI 体系设计,这需要我们稍稍站的远一点看,自动化框架的编写是多人协作共同完成的,如果作为脚本的管理者或者是 TL,需要了解的是每个人的具体情况,比如负责了多少接口,执行覆盖了多少接口,这些接口里做了多少数据校验以及整体情况,如整体执行覆盖了多少接口,做了多少数据校验。
那么该如何做呢?首先得知道接口的负责人是谁,这需要独立维护一张关系表。实际框架运行中,suite 层调用 keyword 层,keyword 层调用 api 层,这些代码内部是嵌套调用的。
还是举个例子,A 接口的请求代码封装在了 api 层的函数中。A 接口响应的校验代码封装在了 keyword 层的函数中,里面调用 api,请求了数据库,做了数据校验。A 接口调用的业务场景函数封装在了 suite 层。那么在这次执行中,通过 keyword 层的函数,可以拿到 A 接口的信息以及数据库信息,校验语句信息。而通过 A 接口可以嫁接关系表来获得对应负责人的信息:
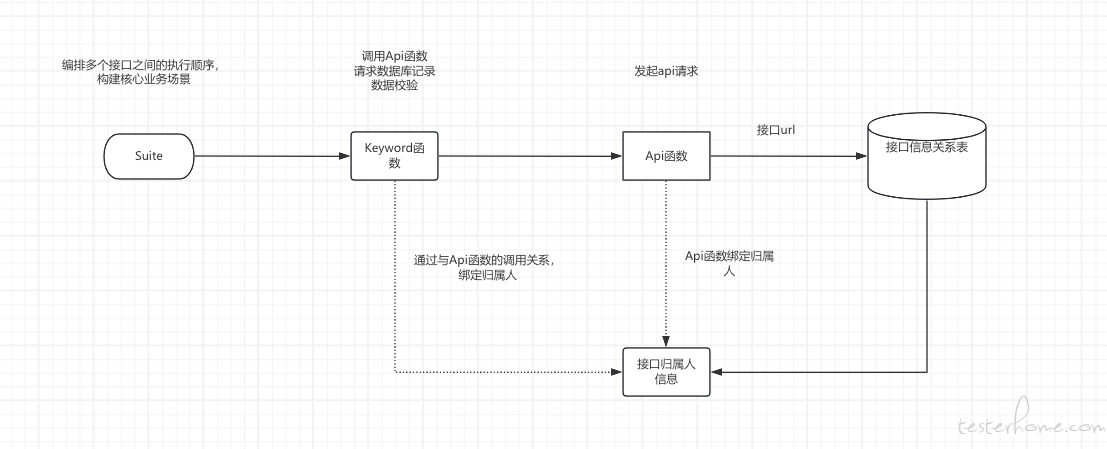
按照以上图中所示的设计思路,有了满足以上条件的数据,就可以在一次完整的自动化脚本生命周期内,统计出以个人为维度的执行数据,进而统计出整次过程的执行数据。
所以在 api 请求的时候,也需要做一定的工作:
def http_get(self, session_name: str, endpoint: str, params: Optional[Dict[str, Any]] = None) -> Dict[str, Any]:
"""发送GET请求"""
return self._make_request(session_name, "GET", endpoint, request_params=params)
def _make_request(self, session_name: str, method: str, endpoint: str,
request_params: Optional[Dict[str, Any]] = None,
request_data: Optional[Dict[str, Any]] = None,
json_data: Optional[Dict[str, Any]] = None) -> Dict[str, Any]:
"""公共方法:执行HTTP请求"""
if session_name not in self.sessions:
raise ValueError(f"Session '{session_name}' not found")
session_info = self.sessions[session_name]
url = f"{session_info['host']}{endpoint}"
# 打印请求日志
param_type = "参数" if request_params else "数据"
param_value = request_params if request_params else (request_data if request_data else json_data)
logger.info(f"正在发起对于:{url}的{method}请求,请求{param_type}为:{param_value}.")
# 执行请求
try:
if method == "GET":
response = session_info["session"].get(url, params=request_params or {})
elif method == "POST":
if json_data is not None:
response = session_info["session"].post(url, json=json_data or {})
else:
response = session_info["session"].post(url, data=request_data or {})
elif method == "DELETE":
response = session_info["session"].delete(url, params=request_params or {}, data=request_data or {})
else:
raise ValueError(f"不支持的HTTP方法: {method}")
# 解析响应
response_data = response.json()
logger.info(f"{url}的{method}请求,接口响应为:{response_data}.")
# 记录结果
self._record_api_result(url, method, response_data, request_params, request_data, json_data)
return response_data
def _record_api_result(self, url: str, method: str, response_data: Dict[str, Any],
request_params: Optional[Dict[str, Any]] = None,
request_data: Optional[Dict[str, Any]] = None,
json_data: Optional[Dict[str, Any]] = None):
"""公共方法:记录API调用结果"""
# 获取api函数的名称
caller_name, source_line, caller_source = self._get_caller_info()
api_result = {
"url": url,
"method": method,
"response": response_data,
"success": response_data["success"],
"start_at": int(time.time() * 1000)
}
# 根据请求类型添加相应参数
if request_params is not None:
api_result["params"] = request_params
if request_data is not None:
api_result["data"] = request_data
if json_data is not None:
api_result["data"] = json_data
if caller_name not in API_RESULTS:
API_RESULTS[caller_name] = []
API_RESULTS[caller_name].append(api_result)
使用以上代码最终获得的 API_RESULTS 结果如下:
{
"Http_账户密码登录_api": [{
"url": "http://***/account/login.json",
"method": "GET",
"response": {
"code": "200",
"data": "***",
"msg": "success",
"success": true,
},
"success": true,
"start_at": 1770703557250,
"params": {
"username": "****",
"password": "****"
}
}],
"Http_获取用户信息_api": [{
"url": "http://*****/account/info.json",
"method": "GET",
"response": {
"code": "200",
"data": "****",
"msg": "success",
"success": true,
},
"success": true,
"start_at": 1770703557250
}]
}
数据整合&测试报告
通过将 KEYWORD_RESULTS、API_RESULTS 两个执行过程的结果整合起来,这里需要用到 start_at 的时间戳字段了,之所以在执行过程中嵌入 start_at,就是为了在整合数据过程,通过时间戳的差值来进行执行记录匹配:
for api_name in api_names:
results_for_api = api_results.get(api_name, None)
if not results_for_api:
continue
# 找到最接近 keyword_start_at 的结果
closest_result = None
min_diff = float('inf')
for result in results_for_api:
diff = abs(result["start_at"] - keyword_start_at)
if diff < min_diff:
min_diff = diff
closest_result = result
if closest_result:
nearest_results[api_name] = closest_result
# keyword内的apis和api执行记录内按照最接近执行时间的算法聚合在一起
if nearest_results:
for api_name, api_result in nearest_results.items():
api_url = api_result["url"]
api_urls.append(api_url)
# 分离URL的域名和路径
parsed_url = urlparse(api_url)
domain = parsed_url.scheme + "://" + parsed_url.netloc
path = parsed_url.path
# 寻找接口负责人信息
interface_record = CIInterfaceInfo.objects.filter(
department_id=department_id, domain=domain, path=path, env=env, date_delete=None).order_by("-date_update")
if not interface_record:
owner_name="暂无归属"
interface_info = interface_record[0]
owner_name = interface_info.owner_name
最后标记出异常的代码及数据源:
keyword_results = json.loads(keyword_results)
for keyword_name, keyword_data in keyword_results.items():
results = keyword_data["results"]
error_list = results["error"]
for error_info in error_list:
for sentence_name, value in error_info.items():
value.pop("success")
sentence_failure_list_item = {
"keyword_name": keyword_name,
"api_names": api_names,
"api_urls": api_urls,
"api_owners": api_owners,
"sentence_name": sentence_name,
"source_line": value.pop("source_line"),
"error": value
}
sentence_failure_list.append(sentence_failure_list_item)
# 封装图表信息
temporary_interface_list = [
{"name": "调用成功", "value": api_success},
{"name": "调用失败", "value": api_failure}
]
temporary_sentence_list = [
{"name": "校验通过", "value": sentence_success},
{"name": "校验失败", "value": sentence_failure}
]
data = {
"temporary_interface_list": temporary_interface_list,
"temporary_sentence_list": temporary_sentence_list,
# 执行异常表格数据
"sentence_failure_list": sentence_failure_list
}
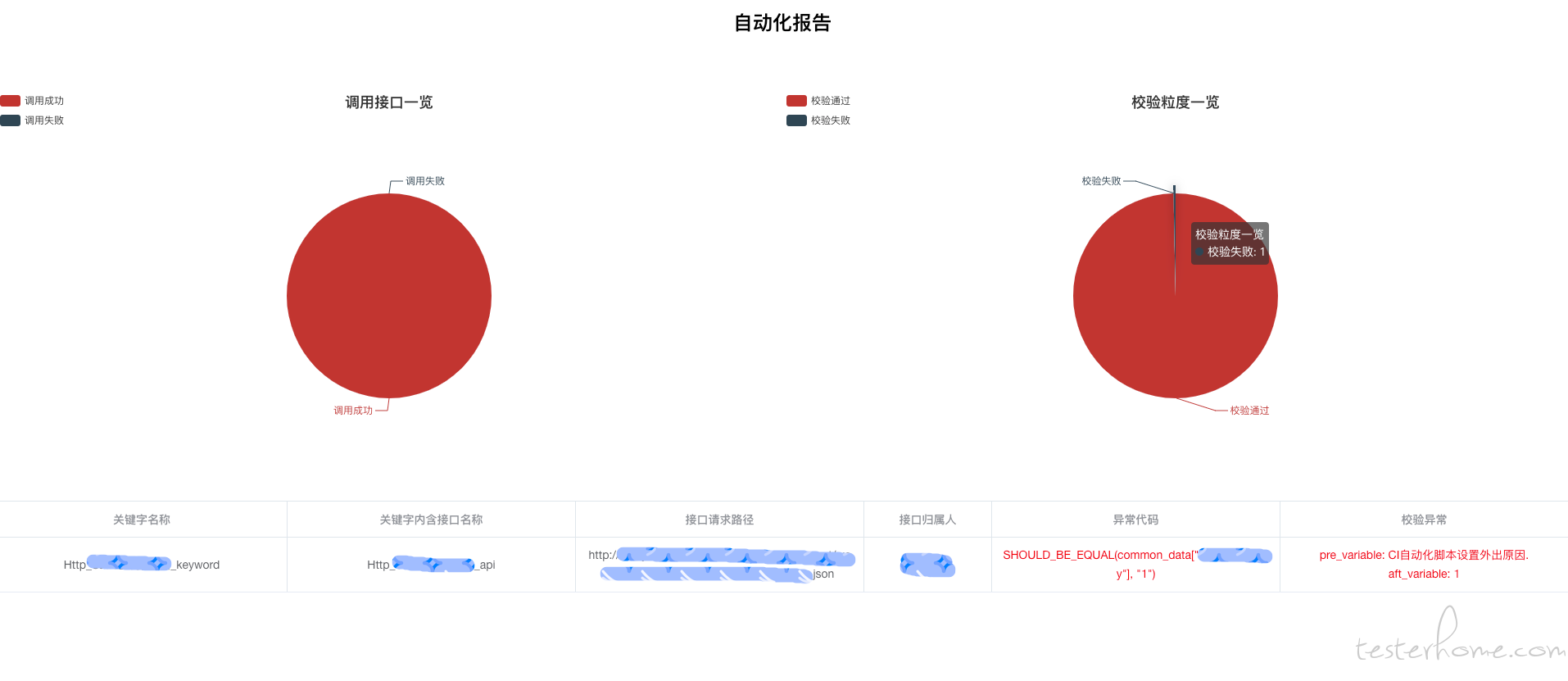
转换为图表报告:
以上图表使用 echarts 开发,需要封装成对应的数据格式。
报告解读
这份报告,省去了冗长的日志打印,直截了当的表明哪个 Keyword 函数异常,Keyword 函数内调用的 Api 函数信息,Api 函数内调用的 api 信息,报错的校验语句,以及错误的具体数据。除此之外,还记录了本次执行调用的接口总数,成功、失败的比例。本次执行过程中校验语句使用的数量,成功、失败的比例。
有了这些数据,测试可以快速跟进异常,降低脚本修正、迭代成本。便于数据沉淀,后续可生成可视化图表,观察一段时间内的个人及整体自动化编写进度。
结尾
文章内容较长,辛苦看到结尾。在此处,回到我们的主题:自动化框架只是工具,它的开发和使用,并不复杂,关键在于能够有一个机制去推动测试成员构建值得信赖的自动化脚本,能够真正为测试减少回归成本、提供线上核心场景的运行保障。
以上只是一家之言,若能对浏览这篇文章的朋友有所启发,自然欣喜。若是觉得味同嚼蜡,也可弃之不顾。
感谢愿意看到此处的朋友,祝顺遂。