大家好!我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人
机器学习 01-1
机器学习 01-2
机器学习 02
机器学习 03-1 如何建立模型 - 选择算法建立模型
机器学习 03-2 如何建立模型 - 训练模型
机器学习 03-3 如何建立模型 - 模型的评估和优化
机器学习 04-1 从数据中找到用户的 RFM 值 - 问题定义与数据预处理
机器学习 04-2 从数据中找到用户的 RFM 值 - 求 RFM 值
机器学习 05-1 聚类分析 - 聚类算法 K-Means
机器学习确实学习起来很难,我对此也没啥兴趣,但难顶是工作中要使用,也就逼着自己来学习完
现在算过来继续填坑
之前我们使用聚类算法 K-Means 获取了特征,现在我们就需要创建和训练模型了
然后发现两个学习机器学习算法的网站,大家有兴趣可以去学习一下
https://developers.google.com/machine-learning?hl=zh-cn
创建和训练模型
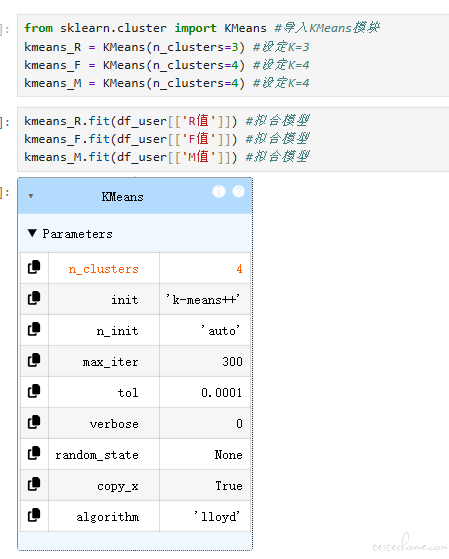
之前我们选择了 R、F、M 的 K 值,分别是 3、4、4
所以我们分别制定 n_clusters 的参数
from sklearn.cluster import KMeans #导入KMeans模块
kmeans_R = KMeans(n_clusters=3) #设定K=3
kmeans_F = KMeans(n_clusters=4) #设定K=4
kmeans_M = KMeans(n_clusters=4) #设定K=4
这样我们在程序中创建了一个 K-Means 聚类模型。
创建好模型后,我们借助 fit 方法,用 R 值的数据,训练模型
kmeans_R.fit(df_user[['R值']]) #拟合模型
kmeans_F.fit(df_user[['F值']]) #拟合模型
kmeans_M.fit(df_user[['M值']]) #拟合模型
fit,翻译成中文就叫做拟合模型。基本上所有的机器学习模型都是用 fit 语句来进行模型训练的。
使用模型进行类聚,并给用户分组
- 1.给 R、F、M 值聚类
kmeans 模型中的 predict 方法给 R 值聚类,作为无监督学习,就是使用模型进行聚类,也不需要评估。
df_user['R值层级'] = kmeans_R.predict(df_user[['R值']]) #通过聚类模型求出R值的层级
df_user.head() #显示头几行数据
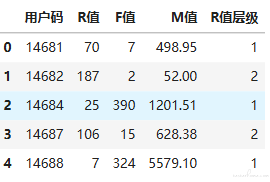
输出显示,这个聚类结果被附加到了用户层级表中
下面使用 groupby 语句来看看 0、1、2 这几个簇的用户基本统计数据
df_user.groupby('R值层级')['R值'].describe() #R值层级分组统计信息
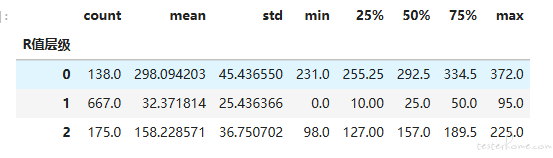
聚类,作为一种无监督学习算法,是不知道顺序的重要性的,它只是盲目地把用户分群(按照其空间距离的临近性),而不管每个群的具体意义,因此也就没有排序的功能。
- 2.为聚类的层级做排序
#定义一个order_cluster函数为聚类排序
def order_cluster(cluster_name, target_name,df,ascending=False):
df_new = df.groupby(cluster_name)[target_name].mean().reset_index() #按聚类结果分组,创建df_new对象
df_new = df_new.sort_values(by=target_name,ascending=ascending).reset_index(drop=True) #排序
df_new['index'] = df_new.index #创建索引字段
df_new = pd.merge(df,df_new[[cluster_name,'index']], on=cluster_name) #基于聚类名称把df_new还原为df对象,并添加索引字段
df_new = df_new.drop([cluster_name],axis=1) #删除聚类名称
df_new = df_new.rename(columns={"index":cluster_name}) #将索引字段重命名为聚类名称字段
return df_new #返回排序后的df_new对象
消费天数间隔的均值越小,用户的价值就越高,所以我们在这里采用降序,也就是把 ascending 参数设为 False
df_user = order_cluster('R值层级', 'R值', df_user, False) #调用簇排序函数
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
df_user.head() #显示头几行数据
上面的代码中,我们并没有改变用户的分组,而只是改变了每一个簇的编号,这样层级关系就能体现出来了
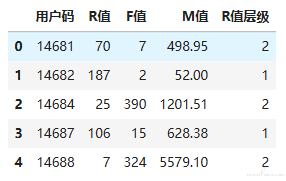
重新显示各个层级
df_user.groupby('R值层级')['R值'].describe() #R值层级分组统计信息
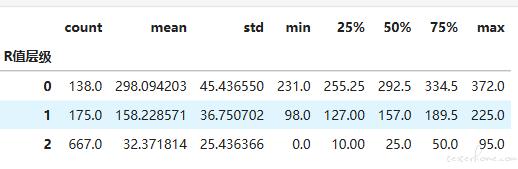
R 值聚类做好后,我们按照同样的方法可以根据用户购买频率给 F 值做聚类,并用刚才定义的 order_cluster 函数为聚类之后的簇进行排序,确定层级。
因为消费次数越多,价值越高,所以我们把 order_cluster 函数的 ascending 参数设定为 True,也就是升序
然后再照着做 M 值聚类的,并获取最终结果
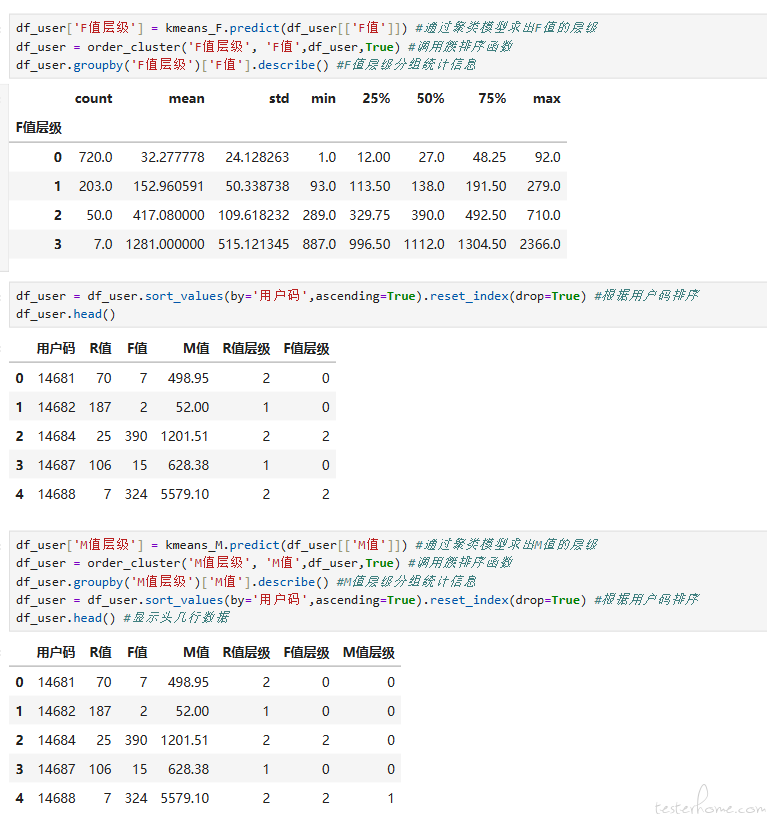
为用户整体分组画像
采用简单叠加的方法把 R、F、M 三个层级的值相加,用相加后得到的值,作为总体价值,来给用户进行最终的分层
因为 R 值有 3 个层级(0,1,2),F 值有 4 个层级(0,1,2,3),M 值有 4 个层级(0,1,2,3),我们把三个维度的值相加,那每一个用户的得分有可能是 0 到 8 当中的某一个值,也就是说出现了 9 个层次。
我这里就按照下面的规则,来确定用户最终的价值分层。当然了,你也可以尝试用其它的阈值来确定你的价值分层。
0-2 分,低价值用户 3-4 分,中价值用户 5-8 分,高价值用户
什么意思呢?举例来说,就是如果一个用户在 R 值拿到了 2 分,在新近度这个维度为高价值用户,但是在消费频率和消费金额这两个维度都只拿到 0 分,那么最后得分就为 2,总体只能评为低价值用户。
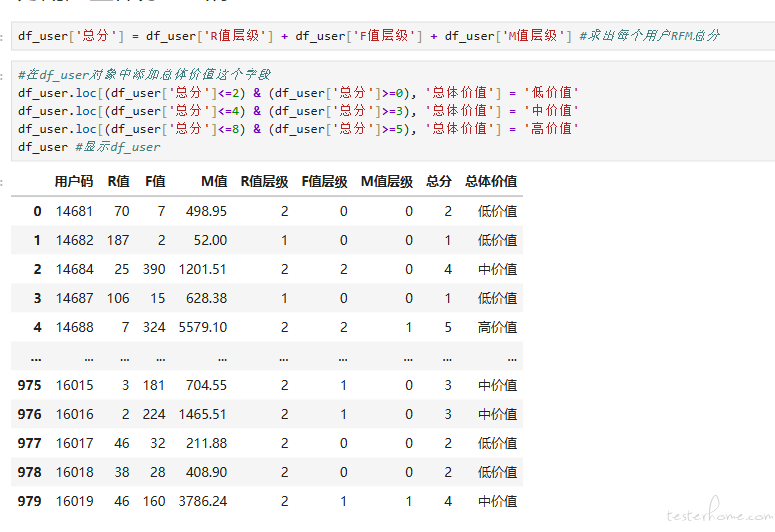
此时,980 个用户的 R、F、M 层级,还有总体价值的层级都非常清楚了。对于每一个用户,我们都可以迅速定位到他的价值
现在,有了用户的价值分组标签,我们就可以做很多进一步的分析,比如说选取 R、F、M 中任意两个维度,并把高、中、低价值用户的散点图进行呈现:
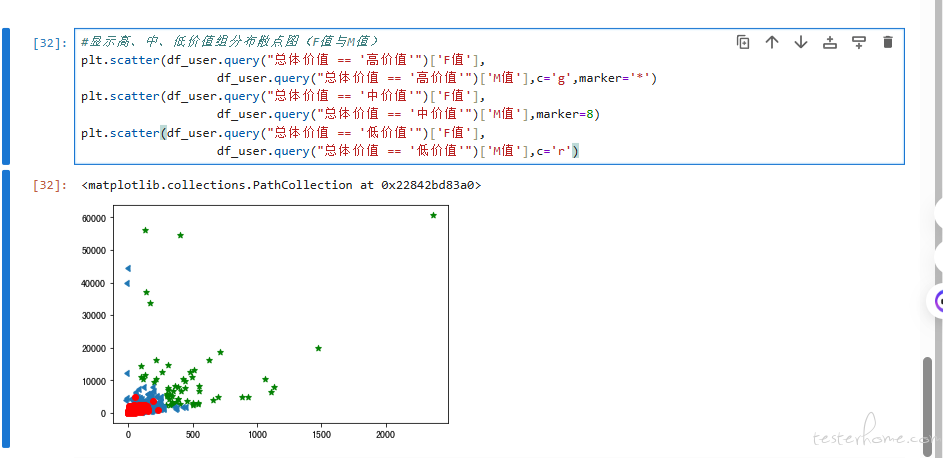
借此,我们可以发现,高价值用户(绿色五星)覆盖在消费频率较高的区域,和 F 值相关度高。而在总消费金额大于 5000 元的用户中,中高价值的用户(绿色五星和红色圆点)都有。
作为运营部门的一员,你还可以通过对新老用户的价值分组,制定出更有针对性的获客、营销、推广等运营方案
到这里我们的聚类分析就结束了,囫囵吞枣,希望对你有帮助。
我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人,希望我的文章可以给你带来好心情!