大家好!我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人
机器学习 01-1
机器学习 01-2
机器学习 02
机器学习 03-1 如何建立模型 - 选择算法建立模型
机器学习 03-2 如何建立模型 - 训练模型
今天我们继续说模型的评估和优化
众所周知,梯度下降是在用训练集拟合模型时最小化误差,这时候算法调整的是模型的内部参数。
而在验证集或者测试集进行模型效果评估的过程中,我们则是通过最小化误差来实现超参数(模型外部参数)的优化。
对此,机器学习工具包(如 cikit-learn)中都会提供常用的工具和指标,对验证集和测试集进行评估,进而计算当前的误差。
比如 R2 或者 MSE 均方差指标,就可以用于评估回归分析模型的优劣。
这里将 “使用模型预测浏览量” 包含在 “模型性能的评估和优化” 中
当我们预测完测试集的浏览量后,我们要再拿这个预测结果去和测试集已有的真值去比较,这样才能够求出模型的性能。
而这整个过程也同样是一个循环迭代的过程
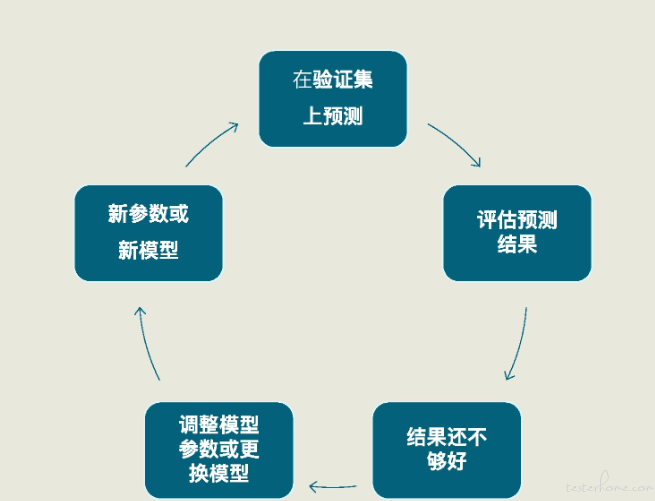
对于项目来说,预测测试集的浏览量,只需要用训练好的模型 linereg_model 中的 predict 方法,在 X_test(特征测试集) 上进行预测,这个方法就会返回对测试集的预测结果。
y_pred = linereg_model.predict(X_test) #预测测试集的Y值
在几乎所有的机器学习项目中,你都可以用 predict 方法来进行预测,它就是用模型在任意的同类型数据集上预测真值的
可以应用于验证集、测试集,当然也可以应用于训练集本身。
为了简化流程,这里没有真正进行验证和测试的多重循环。
因此这里 X_test 既充当了测试集,也充当了验证集。
拿到预测结果后,我们再通过下面的代码,把测试数据集的原始特征数据、原始标签真值,以及模型对标签的预测值组合在一起进行显示、比较。
df_ads_pred = X_test.copy() # 测试集特征数据
df_ads_pred[''浏览量真值] = y_test #测试集标签真值
df_ads_pred[''浏览量预测值] = y_pred # 测试集标签预测值
df_ads_pred # 显示数据
正常跑出来,可以看出浏览量预测值是比较接近于真值的
你可以通过 LinearRegression 的 coef_和 intercept_属性打印出各个特征的权重和模型的偏置来。
它们也就是模型的内部参数。
print('当前模型的4个特征的权重分别是: ', linereg_model.coef_)
print('当前模型的截距(偏置)是: ', linereg_model.intercept_)
输出
当前模型的4个特征的权重分别是: [ 48.08395224 34.73062229 29730.13312489 2949.62196343]
当前模型的截距(偏置)是: -127493.90606857178
这表示模型的线性回归公式是:
yy=48.08x1(点赞)+34.73x2(转发)+29730.13x3(热度)+2949.62x4(评级)−127493.91
评估分数
最后我们还要给出当前这个模型的评估分数
print("线性回归预测评分:", linereg_model.score(X_test, y_test)) # 评估模型
在机器学习中,常用于评估回归分析模型的指标有两种:R2 分数和 MSE 指标,并且大多数机器学习工具包中都会提供相关的工具。
我们只要知道这里的 score 这个 API 中,选用的是 R2 分数来评估模型的就可以了。
最后得到的 R2 值大概为 0.708
R2 的取值在 0 到之间,R2 越大,说明所拟合的回归模型越优。
在没有和其他模型相比时,我们实际上也没法确定它是否能令人满意。
分数的高低,与数据集预测的难易程度、模型的类型和参数都有关系。
R2 分数也不是线性回归模型唯一的评估标准。
评估不理想
如果模型评估的分数不理想,我们可以需要回到调整模型的外部参数,重新训练模型。
要是依然不理想,我们就要考虑选择其他算法,创建全新的模型了。
如果新模型的效果还是不好,可以就需要回到第二步,去看看数据是不是出问题了。
从这里可以看出,机器学习项目是一个循环迭代的过程,优秀的模型都是一次次迭代的产物。
结束
当模型通过了评估,就可以去解决实际问题了,机器学习项目也算是基本结束。
上线和部署一般不是机器学习工程师去负责了
总结
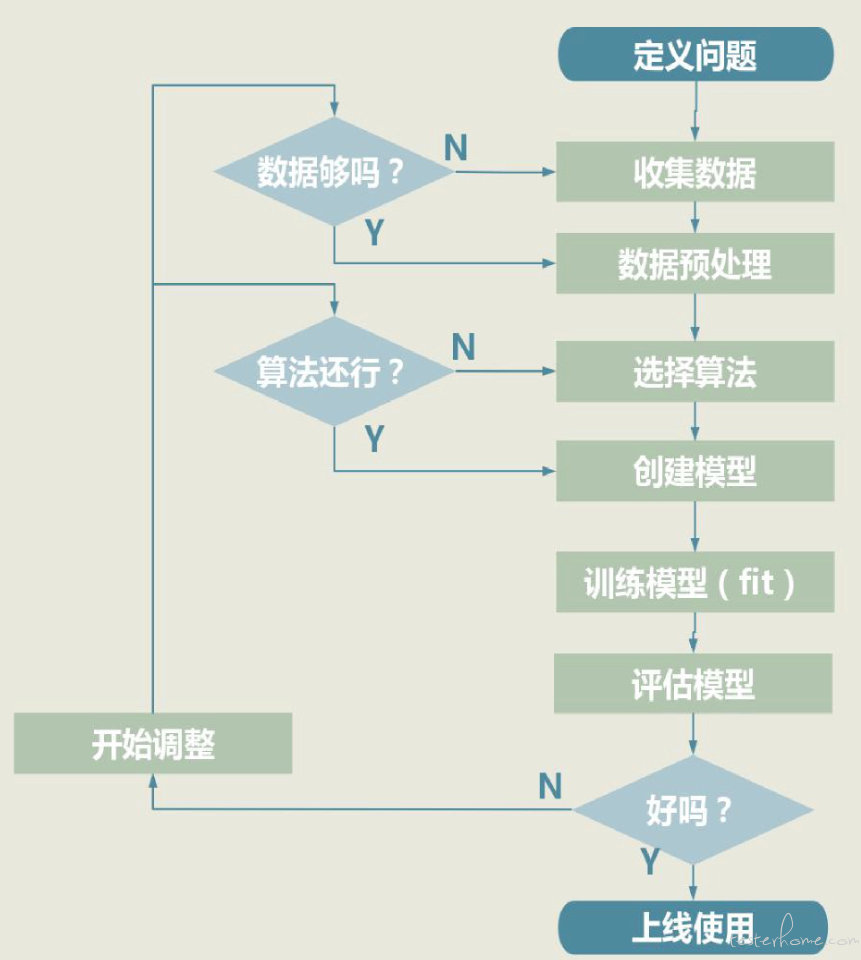
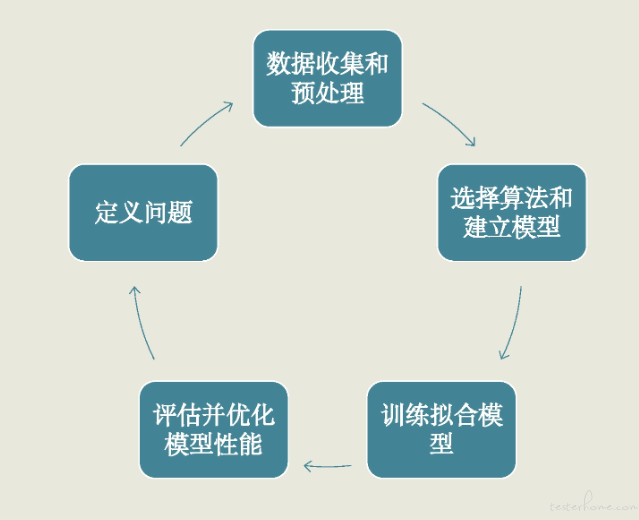
模型建立大概为五个步骤:
- 通过定义问题来明确项目的目标
- 数据的收集和预处理,重点是把数据转换成机器学习可处理的格式
- 针对问题选定适宜的算法,来建立模型
- 训练模型、拟合函数
- 对训练好的模型进行评估和优化,重点是反复测评,找到最优的超参数,确定最终模型。
好了,今天就到这里了,晚安!
我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人,希望我的文章可以给你带来好心情!