大家好!我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人
机器学习 01-1
机器学习 01-2
机器学习 02
机器学习 03-1 如何建立模型 - 选择算法建立模型
第四步 训练模型
训练模型就是用训练集中的特征变量和已知标签,根据当前样本的损失大小来逐渐拟合函数,确定最优的内部参数,最后完成模型。
虽然看起来挺复杂,但这些步骤,我们都通过调用 fit 方法来完成。
fit 方法是机器学习的核心环节,里面封装了很多具体的机器学习核心算法,
我们只需要把特征训练数据集和标签训练数据集,同时作为参数传进 fit 方法就行了。
linereg_model.fit(X_train, y_train) #用训练集数据,训练机器,拟合函数,确定内部参数
运行该语句后的输出如下:
LinearRegression()
这样,我们就完成了对模型的训练。
训练模型是机器学习的核心环节,怎么只有一句代码?
其实是因为优秀的机器学习库的存在,我们可以用一两行语句实现很强大的功能。
所以,不要小看上面那个简单的 fit 语句,这是模型进行自我学习的关键过程。
损失
在上面这个过程里,fit 的核心就是减少损失,是函数对特征到标签的模拟越来越贴切。
那么它具体是怎么减少损失呢?这里看一个模型从不靠谱到比较靠谱的过程。
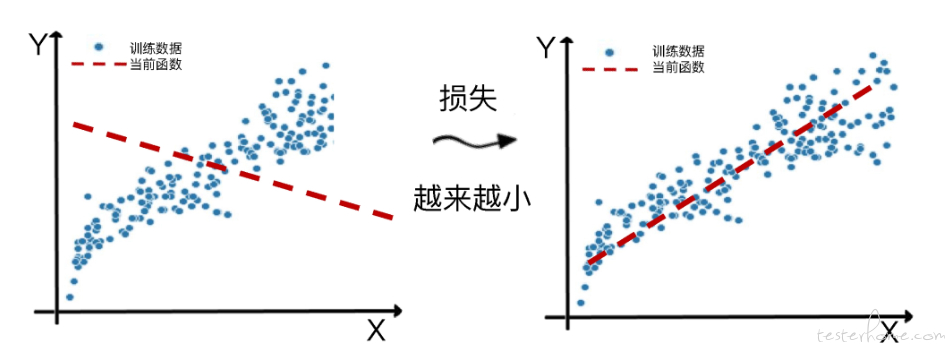
这个拟合的过程,同时也是机器学习算法优化其内部参数的过程。
而优化参数的关键就是减小损失。
那什么是损失呢?它其实是对糟糕预测惩罚,同时也是对模型好坏的度量。
损失也就是模型的误差,也称为成本或代价。就是当前预测值和真实之间的差距的体现。
它是一个数值,表示对于单个样本而言模型预测的准确程度。
如果模型的预测完全准确,则损失为 0;如果不准确,就有损失。
在机器学习中,我们追求的当然是比较小的损失。
不过,模型好不好,还不能仅看单个样本,还要针对所有数据样本,找到一组平均损失 “较小” 的函数模型。
样本的损失大小,从几何意义上基本可以理解为预测值和真值之间的几何距离。
平均距离越大,说明误差越大,模型越离谱。
在下面这个图中,左边是平均损失较大的模型,右边是平均损失较小的模型,模型所有数据点的平均损失很明显大过右边模型。
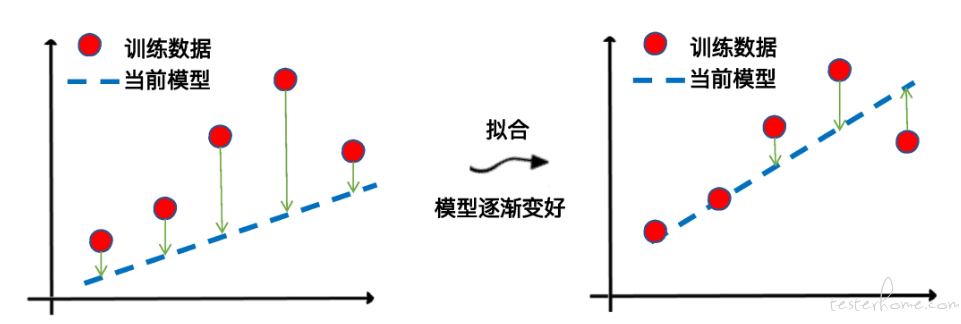
因此,针对每一组不同的参数,机器都会基于样本数据集,用损失函数算一次平均损失。
而机器学习的最优化过程,就是逐步减少训练集上损失的过程。
具体到这个回归模型的拟合,它的关键环节就是通过梯度下降,逐步优化模型的参数,使训练集误差值达到最小。
这也就是我们刚才讲的那个 fit 语句所要实现的最优化过程。
梯度下降
线性回归中计算误差的方法很好理解,就是数据集中真值与预测值之间的残差平方和。
那梯度下降是什么呢?梯度下降描述的是怎么一步一步地走到损失曲线中的最小损失点
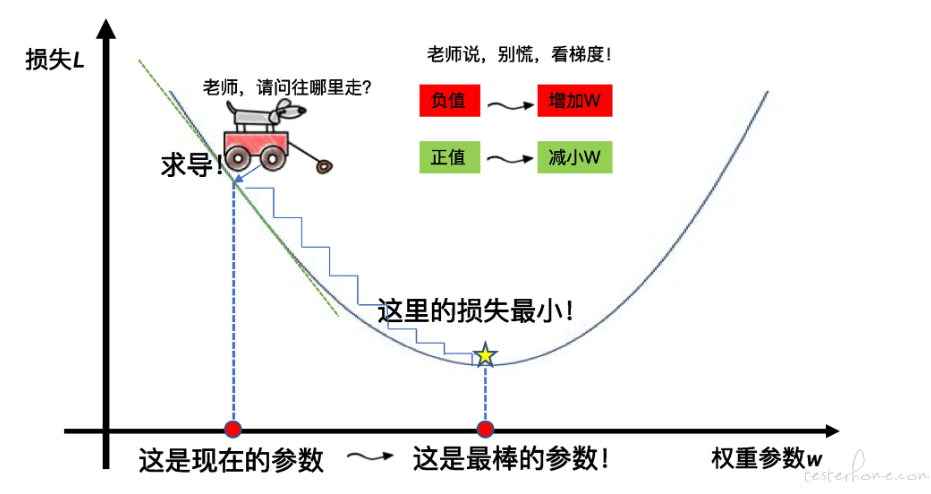
梯度下降其实和下山一样。当你站在高处,你的目标就是找到一系列的参数,让训练数据集上的损失值最小。
那么该往哪里走才能保证损失值最小呢?
关键就是通过求导的方法,找到每一步的方向,确保总是往更小的损失方向前进。
这里,你可以看出方向是有多么的重要。机器学习最优化之所以能够拟合出最佳的模型,就是因为能够找到前进方向。
梯度下降,理解到这里就可以了。
到这里我们完成了模型的建立和训练,后面就需要对训练好的模型进行评估和优化了
今天就到这里了,晚安!
我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人,希望我的文章可以给你带来好心情!