大家好!我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人
机器学习 01-1
机器学习 01-2
机器学习 02
机器学习 03-1 如何建立模型 - 选择算法建立模型
机器学习 03-2 如何建立模型 - 训练模型
机器学习 03-3 如何建立模型 - 模型的评估和优化
机器学习 04-1 从数据中找到用户的 RFM 值 - 问题定义与数据预处理
机器学习 04-2 从数据中找到用户的 RFM 值 - 求 RFM 值
在前面我们获得了用户的 RFM 值,从这些值里面我们又能看出什么有价值的信息呢?
我们需要从枯燥且不容易观察的数据中,得到更清晰的用户分组画像。
今天我们通过理解聚类算法的原理和最优化过程,锻炼自己对问题选择算法的直觉。
如何给用户分组?
上节课中得出的用户层级表,表中有每位用户的 R、F、M 值。
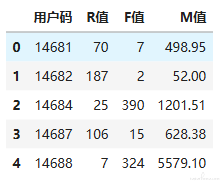
我们看一下 R 值、F 值和 M 值的分布情况,以便为用户分组做出指导。
df_user['R值'].plot(kind='hist', bins=20, title = '新进度分布直方图') #R值直方图
df_user.query('F值 < 800')['F值'].plot(kind='hist', bins=50, title = '消费频率分布直方图') #F值直方图
df_user.query('M值 < 20000')['M值'].plot(kind='hist', bins=50, title = '消费金额分布直方图') #M值直方图
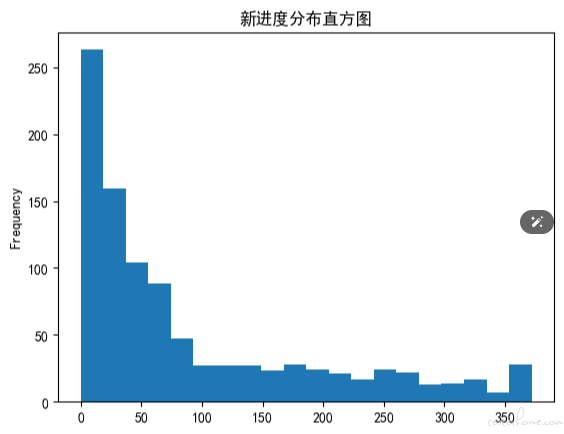
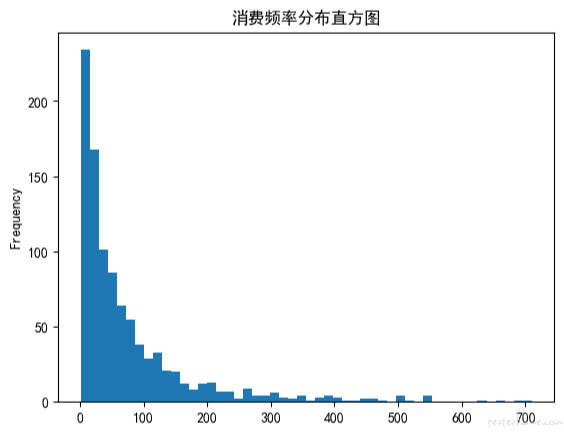
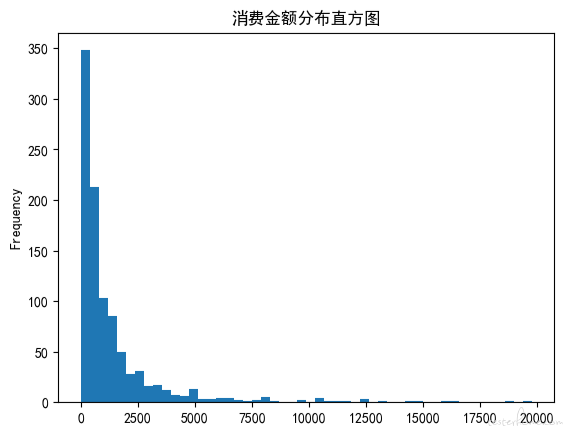
我们求出的 R 值、F 值与 M 值的覆盖区间都很大。
那我们怎么分组比较合适呢?这里有两个子问题
- 分成多少个组比较好?
- 从哪个值到哪个值归为第一组(比如 0-30 天是一组),从哪个值到哪个值归为第二组(比如 30 天 -70 天是一组)?
这里还是采用机器学习算法,根据数据的实际情况来动态地确定分组。
因为只有这样的模型才是动态的,才能长期投入使用。
接下来就要考虑选什么算法来建立模型。
聚类算法中的 K-Means 算法
首先我们可以确定给用户做分组画像属于无监督学习问题
在无监督学习中,聚类和降维是两种最常见的算法,这里不多介绍了
聚类算法是把空间位置相近的特征数据归为一组
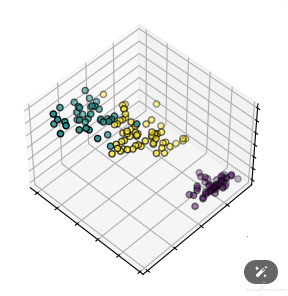
但聚类算法本身并不知道哪一组用户是高价值,哪一组用户是低价值。
分组完后还要根据机器聚类的结果,人为地给这些用户组贴标签,这一动作也被称为 “聚类后概念化”
聚类的算法不止一种,我们需要进一步确定采用哪一个算法。这里我直接选用 K-Means(K-均值)算法了。
这个算法简洁、高效,类似文档归类、欺诈行为检测、用户分组等等这些场景,我们往往都能用到。
K-Means 算法中,“K” 是一个关键。K 代表聚类的簇的个数。
比如我们把 M 值作为特征,将用户分成 3 个簇(即高、中、低三个用户组),那这里的 K 值就是 3,并且需要我们人工指定。
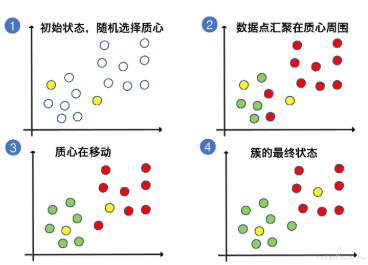
指定 K 的数值后,K-Means 算法会在数据中随机挑选 K 个数据点,作为簇的质心(centroid),这些质心就是未来每一个簇的中心点,
算法会根据其他数据点和它的距离来进行聚类。
挑选出质心后,K-Means 算法会遍历每一个数据点,计算它们与每个质心的距离。
数据点离哪个质心近,就跟哪个质心属于一类。
遍历结束后,每个质心周围都聚集了很多数据点,这时候,算法会在数据簇中选择更靠近中心的质心,如果原来的随机选择的质心不合适,就会让它下岗。
“挑选质心” 和 “遍历数据点与质心的距离” 会不断重复,直到质心的移动变化很小了,或者说固定不变了,那 K-Means 算法就可以停止了。
前面说 K 值需要人工指定,那么怎么在算法的辅助下确定 K 值呢?
手肘法选取 K 值
在事先不确定分成多少比较合适的情况下,“手肘法”(elbow method)可以帮我们决定
在某一批数据点中,数据分为多少组比较合适
R、F、M 的值却可以分成很多组,并不一定都是 3 组
手肘法是通过聚类算法的损失值曲线来直观确定簇的数量。
损失值曲线,就是以图像的方法绘出,取每一个 K 值时,各个数据点距离质心的平均距离。
如图所示,当 K 取值很小的时候,整体损失很大,也就是说各个数据点距离质心的距离特别大
随着 K 的增大,损失函数的值绘在逐渐收敛之前出现一个拐点。此时的 K 值就是一个比较好的值。
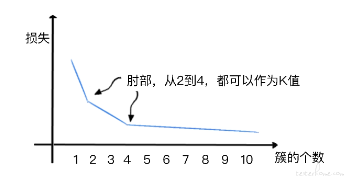
最佳 K 值的点像是一个手肘,这就是为什么我们会叫它 “手肘法” 的原因。
下面我们就用代码找出 R 值的手肘点。请你注意,这里我会先定义一个找手肘点的函数
后面找 R、F、M 值聚类都需要用到这个函数
from sklearn.cluster import KMeans #导入KMeans模块
def show_elbow(df): #定义手肘函数
distance_list = [] #聚质心的距离(损失)
K = range(1,9) #K值范围
for k in K:
kmeans = KMeans(n_clusters=k, max_iter=100) #创建KMeans模型
kmeans = kmeans.fit(df) #拟合模型
distance_list.append(kmeans.inertia_) #创建每个K值的损失
plt.plot(K, distance_list, 'bx-') #绘图
plt.xlabel('k') #X轴
plt.ylabel('距离均方误差') #Y轴
plt.title('k值手肘图') #标题
show_elbow(df_user[['R值']]) #显示R值聚类K值手肘图
show_elbow(df_user[['F值']]) #显示F值聚类K值手肘图
show_elbow(df_user[['M值']]) #显示M值聚类K值手肘图
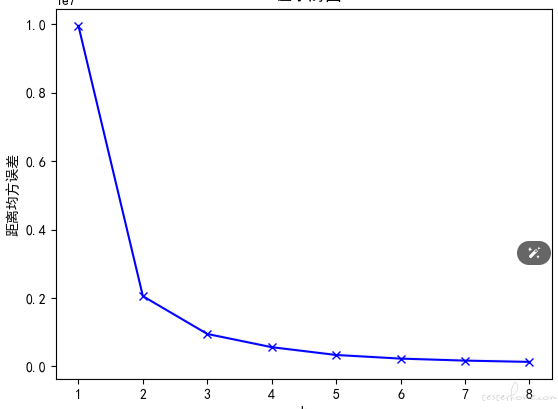
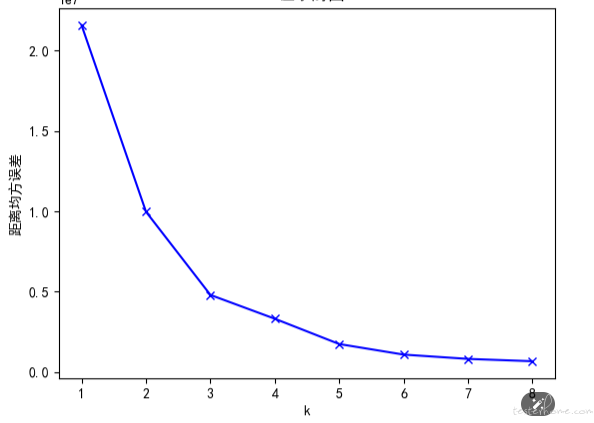
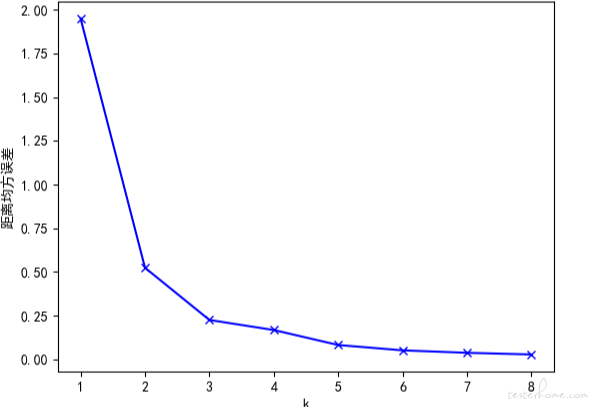
可以看到,R、F、M 值的拐点大概都在 2 到 4 之间附近,这就意味着我们把用户分成 2、3、4 个组都行。
这里 R、F、M 的簇分别为 3、4、3
到这里,我们已经选定了算法,并确定了 R、F、M 每个特征相爱簇的个数,也就是 K 值。
接着我们就可以开始创建聚类模型了。
今天就暂时学习到这里了
我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人,希望我的文章可以给你带来好心情!