大家好!我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人
机器学习 01-1
机器学习 01-2
机器学习 02
机器学习 03-1 如何建立模型 - 选择算法建立模型
机器学习 03-2 如何建立模型 - 训练模型
机器学习 03-3 如何建立模型 - 模型的评估和优化
机器学习 04-1 从数据中找到用户的 RFM 值 - 问题定义与数据预处理
求 RFM 值
书接上回,我们的目标就是建立一个机器学习模型,给用户做价值分组。
RFM 实际上就是我们构建模型所需的关键特征数据。
实际上,我们是在完成机器学习项目中的 “特征工程” 环节
也就是对原始数据集中的信息进行选择、提取、合并、加工、转换,甚至是基于原始信息构建出新的、对于模型的训练更具有意义的特征。
数据中的 R 值(最近一次消费的天数)和 F 值(消费频率),
我们通过数据集中的消费日期就能得到,但是对于 M 值(消费金额),
你会发现数据集中有采购数量,有单价,但是还没有每一笔消费的总价。
因此,我们通过一个语句对原有的数据集进行一个小小的扩展。
在 df_sales 这个 DataFrame 对象中增加一个数据列计算总价,总价等于由单价乘以数量:
df_sales['总价'] = df_sales['数量'] * df_sales['单价'] #计算每单的总价
df_sales.head() #显示头几行数据

在这个数据集中,用户码、总价和消费日期这三个字段,给我们带来了每一个用户的 R、F、M 信息。其中:
- 一个用户上一次购物的日期,也就是最新的消费日期,就可以转化成这个用户的 R 值;
- 一个用户下的所有订单次数之和,就是消费频率值,也就是该用户的 F 值;
- 把一个用户所有订单的总价加起来,就是消费金额值,也就是该用户的 M 值
R、F、M 信息是和用户相关的,每一个用户都拥有一个独立的 R 值、F 值和 M 值,
所以,在计算 RFM 值之前,我们需要先构建一个用户层级表。
1.构建用户层级表
我们需要生成一个以用户码为关键字段的 Dataframe 对象 df_user,然后在这个 Dataframe 对象中,
逐步加入每一个用户的新近度(R)、消费频率(F)、消费金额(M),以及最终总的分组信息。
在代码实现上,我们用 Dataframe 的 unique() 这个 API,就能创建出以用户码为关键字段的用户层级表 df_user,
然后我们再设定字段名,并根据用户码进行排序
df_user = pd.DataFrame(df_sales['用户码'].unique()) #生成以用户码为主键的结构df_user
df_user.columns = ['用户码'] #设定字段名
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #按用户码排序 # reset_index(drop=True) 的意思是重置索引,生成新的默认数值类型索引,并且不保留原来的索引
df_user #显示df_user

一共有 980 个用户的数据。有了用户层级表,现在我们依次求出 RFM,让这个用户层级表的结构越来越完整。
2.求出 R 值
R 值代表自用户上次消费以来的天数,它与最近一次消费的日期相关。
所以,用表中最新订单的日期(拉出来这张表的日期)减去上一次消费的日期,就可以确定对应用户的 R 值。
df_sales['消费日期'] = pd.to_datetime(df_sales['消费日期']) #转化日期格式
df_recent_buy = df_sales.groupby('用户码').消费日期.max().reset_index() #构建消费日期信息
df_recent_buy.columns = ['用户码','最近日期'] #设定字段名
df_recent_buy['R值'] = (df_recent_buy['最近日期'].max() - df_recent_buy['最近日期']).dt.days #计算最新日期与上次消费日期的天数
df_user = pd.merge(df_user, df_recent_buy[['用户码','R值']], on='用户码') #把上次消费距最新日期的天数(R值)合并至df_user结构
df_user.head() #显示df_user头几行数据
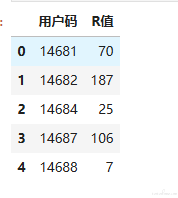
R 值越大,说明该用户最近一次购物日距离当前日期越久,那么这样的用户就越是处于休眠状态。
从表中可以看出来,编号为 14682 的用户已经有 187 天没有购物了。
所以我们就可以判断这个用户呈现休眠态,很可能已经被别的购物平台所吸引了,也就是流失了。
3.求出 F 值
类似地,我们还可以求出 F 值,并把 F 值添加至用户层级表:
df_frequency = df_sales.groupby('用户码').消费日期.count().reset_index() #计算每个用户消费次数,构建df_frequency对象
df_frequency.columns = ['用户码','F值'] #设定字段名称
df_user = pd.merge(df_user, df_frequency, on='用户码') #把消费频率整合至df_user结构
df_user.head() #显示头几行数据
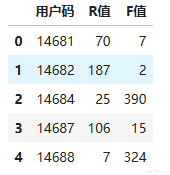
4.求出 M 值
M 值很容易求出,它就是用户消费的总和:
df_revenue = df_sales.groupby('用户码').总价.sum().reset_index() #根据消费总额,构建df_revenue对象
df_revenue.columns = ['用户码','M值'] #设定字段名称
df_user = pd.merge(df_user, df_revenue, on='用户码') #把消费金额整合至df_user结构
df_user.head() #显示头几行数据
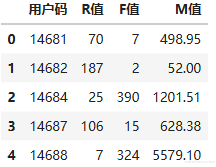
这段代码的核心是通过给用户每张订单的总价字段做 sum() 计数,来求出每一个用户的消费总和。
到这里,我们就求出了每一个用户的 R、F、M 值,完成了特征工程
这只是完成了特征工程环节,在后面根据这三个维度的值给用户分组,这就需要聚类算法
我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人,希望我的文章可以给你带来好心情!