大家好!我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人
机器学习 01-1
机器学习 01-2
机器学习 02
机器学习 03-1 如何建立模型 - 选择算法建立模型
机器学习 03-2 如何建立模型 - 训练模型
机器学习 03-3 如何建立模型 - 模型的评估和优化
最近忙着结婚的事,好久没水文章了,时间一长也就习惯了,不愿意再敲点东西出来。
有时候写东西是百无聊赖,可能是想和自己对话一下
有时候写东西是为了让自己学习,学了以后输出,记录一下这些东西
自己学可能囫囵吞枣,但写东西出来会考虑到别人看不看得懂,稍微会多想想,自己的印象稍微深一点
所以还是写写吧,老是半途而废也不行
最近也在工作上遇到了一些问题,面对一个业务感觉掀开迷雾后看到了个庞然大物
第一反应是有些沮丧的,感觉自己的能力还不够,没法摸清整个系统的脉搏
第二反应是有些压力和紧迫,要逼自己去做一些自己不擅长的事情
不过最后还是定下心来,毕竟是自己感兴趣的东西,不能老是在自己的舒适区呆着
逼自己去学习还是挺反人性的
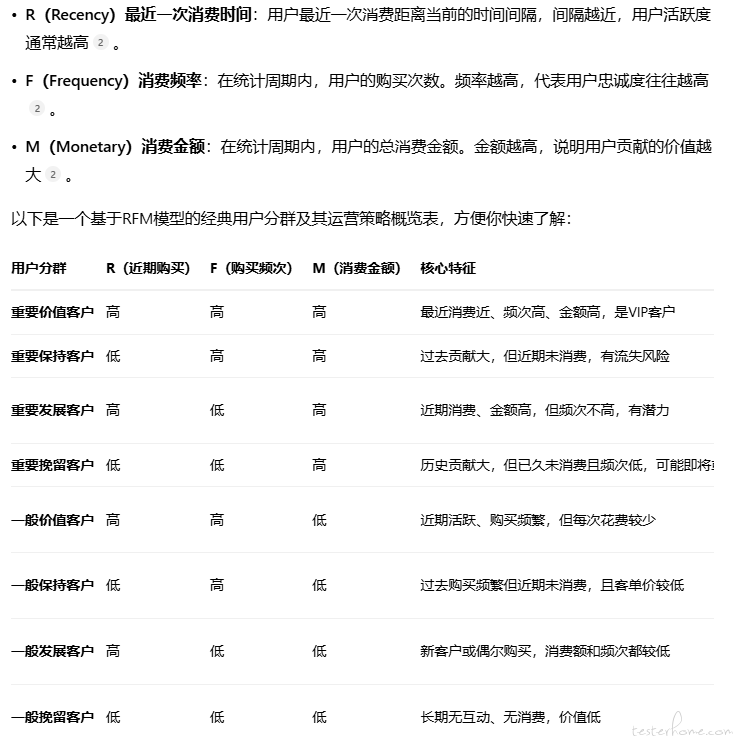
之前学习的是机器学习的基本概念,今天我们结合实际业务聊一下从数据中找到用户的 RFM
看到 RFM 的时候我首先一懵逼,什么是 RFM?我知道 RF 和 FM,RFM 还真不知道
于是直接问 AI 什么是 RFM:
题外话,现在都习惯用 AI 问东西了,搜索引擎已经用得比较少了
由此,我们知道了 RFM 分别表示了用户最近一次消费的时间、消费频率、消费金额
这里 RFM 提出的有点突兀,结合电商场景来说,所有的企业都希望能用更优质的产品和更精确的服务留住用户
这需要制定出合适的获客策略,而做到这一点的前提就是为用户精准画像
也就是根据用户的人口统计信息和消费行为数据,给用户分组,然后推测出用户的消费习惯和价值高低。
所以我们需要按照之前学习的步骤,结合一个具体的电商项目,根据用户的基本信息和消费行为数据,给用户分组画像。
定义问题
我们需要先准备过往用户的基本信息和消费行为数据
它有这些关键信息
| 订单号 | 产品标识 | 消费日期 | 产品说明 | 数量 | 单价 | 用户标识 | 城市 |
|---|---|---|---|---|---|---|---|
| x | x | x | x | x | x | x | x |
我们需要从这份销售订单中为用户分组画像,那我们以什么为依据,给用户做分组?
这就需要我们把用户的行为转化成可量化的指标,让我们对用户有更直观的认识
而且我们可以将这些指标用在数据分析、广告投放、产品推荐系统等其他运营场景,提升产品和服务的精准度。
我们只要从用户的基本信息和消费行为数据中得出 RFM 值,就可以根据它对用户分组画像了。
工作的整体可以分为两个阶段:
第一个阶段是求出 RFM 值
第二个阶段就是利用 RFM 值,给用户分组画像,进而绘制出高价值、中等价值和低价值用户的分布情况。
搞清楚问题后,我们就需要对数据做个初步的预处理
数据预处理
使用 Pandas 中的 read_csv 工具,把原始数据导入 Pandas 的 DataFrame 中
import pandas as pd
df = pd.read_csv("xxx.csv")
df.head()
根据 RFM 定义我们关注下面的几个数据
- 用户标识
- 单价
- 数量
- 消费日期
为了更好的了解数据,我们需要做一个整体数据的可视化,看看这个数据集所覆盖的消费日期跨度是什么样的
1. 数据可视化
import matplotlib.pyplot as plt #导入Matplotlib的pyplot模块
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号('-')显示为方块的问题[2](@ref)
#构建月度的订单数的DataFrame
df_sales['消费日期'] = pd.to_datetime(df_sales['消费日期']) #转化日期格式
df_orders_monthly = df_sales.set_index('消费日期')['订单号'].resample('ME').nunique()
#设定绘图的画布
ax = pd.DataFrame(df_orders_monthly.values).plot(grid=True,figsize=(12,6),legend=False)
ax.set_xlabel('月份') # X轴label
ax.set_ylabel('订单数') # Y轴Label
ax.set_title('月度订单数') # 图题
#设定X轴月份显示格式
plt.xticks(
range(len(df_orders_monthly.index)),
[x.strftime('%m.%Y') for x in df_orders_monthly.index],
rotation=45)
plt.show() # 绘图
这里使用了 Pandas 的 to_datetime 这个 API,把原始消费日期转换成了能处理的格式。
而在 df_orders_monthly 中,则是求出了每一个月的订单数量。
2021 年六月份订单量突然下降,其实是因为只记录了一个星期,但并不影响
2.数据清洗
完成可视化后,需要清洗数据。
我们在前面完成了对消费日期的观察,并没有什么异常。
所以,现在我们重点要处理的事用户码、单价和数量。
使用 pandas 的 drop_duplicates 方法把完全相同的重复数据行删除掉
df_sales = df_sales.drop_duplicates() #删除重复的数据行
使用 describe 方法查看这些字段的统计信息是否有脏数据
df_sales.describe() #df_sales的统计信息
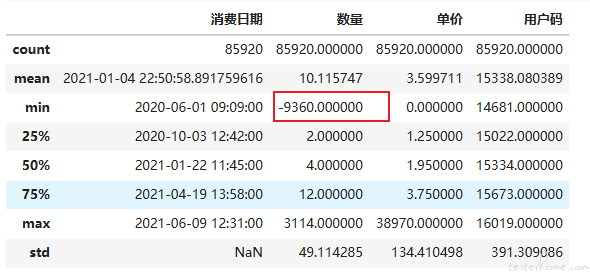
这里发现数量的最小值(min)是个负数,这显然不合理,所以我们要把这种脏数据去掉。
使用 loc 属性通过字段名(列名)访问数据集,同时只保留 “数量” 字段大于 0 的数据行;
df_sales = df_sales.loc[df_sales['数量'] > 0] #清洗掉数量小于等于0的数据
在 DataFrame 对象中,loc 属性是通过行、列的名称来访问数据的,我们做数据预处理时会经常用到;
还有一个常被用到的属性是 iloc,它是通过行列的位置(也就是序号)来访问数据的。
再次使用 describe 方法,就会看到新的最小数量为 1
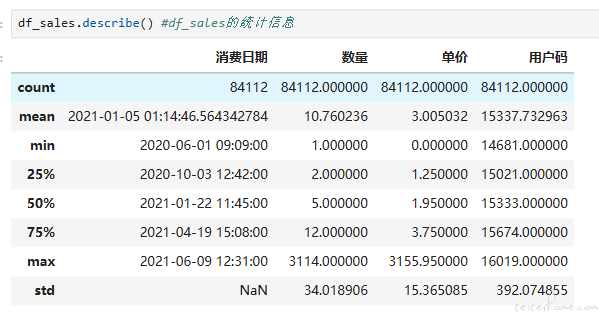
这样我们就完成了数据清洗工作
我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人,希望我的文章可以给你带来好心情!