背景
市面上大部分的 monkey 类测试工具,基本是随机或者在策略下随机的遍历逻辑;典型的例如:原始的 monkey、或者 fastbot 这种基于预训练模型 + 策略配置的 monkey;但无论哪一种,都有固定的缺陷。
- 原始的 monkey,随机性太强,冗余操作太多,遍历度不够
- 类 fastbot 的策略下遍历,策略的配置成本高,需要定制页面映射的动作,才能完成业务逻辑的翻越,典型的场景,登录,你必须配置登录页面映射的登录动作脚本,你能够遍历时越过登录这个页面。
基于随机和动作冗余以及配置成本之间的关系,我们在想,有没有一种方式,可以以最小的成本,作出最符合人类思维的遍历结果,恰逢年初,gpt 横空出世,因此我们决定用 gpt 来做探索性的尝试。
GptTraversal 介绍
GptTraversal 是一个基于大模型的 app 遍历程序,我们使用大模型代替了传统的代码遍历决策系统,如一些典型算法下的策略:深度优先,广度优先,控件的类型和优先级映射,黑白名单设置等;转而让大模型以一个正常的 “人” 的思维,面对 app 的页面,进行遍历的动作决策。
基本原理
由于是公司内的项目,因此暂时不能开源,可以说下大概的原理。
首先,我们将 app 的页面树,做处理后,交给 gpt,让他判断当前的场景,以及下一步如何操作,并记录下历史的决策,下一步的操作会基于遍历目标和历史决策进行,这一步相当于给 gpt 提供视觉,让 gpt“看见” app(当时还没有 gpt4v);
其次,我们会内置相应的动作,例如点击、滑动、输入等等,gpt 会从动作库选择一个,进行相关的动作触发,这一步相当于给 gpt 提供了手,可以对 app 进行直接操作;
最后,我们会记录过程的一切数据,包括覆盖率、截图、内存信息等等,作为最终的报告汇总数据;额外的,为了避免 token 溢出问题带来的 ai 步骤的步数限制,导致遍历度不够,我们增加了传统的 monkey 和 ai 步骤的混编,让随机和有序相结合的进行遍历。
基本架构
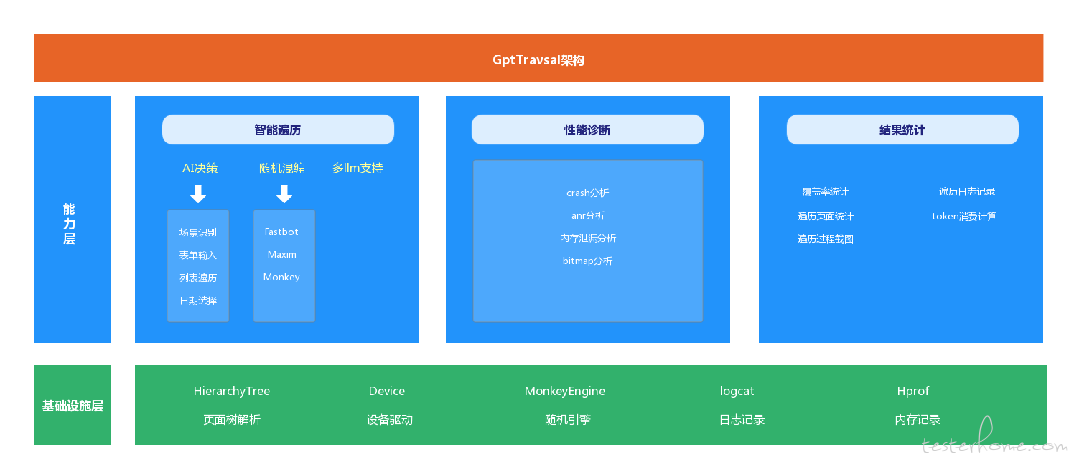
配置列表

项目目录结构
效果
基本上来说,可以代替之前需要定制动作的节点,例如登录、循环翻页、填写表单等等,完全不需要任何的定制化脚本,gpt 可以自主以正常人的思维进行操作。
缺点:
- gpt4 太贵了!太贵了!太贵了!3.5 效果不佳
- 由于 token 限制,给页面树和历史决策,很明显会遇到 token 溢出的问题,可以通过限制历史决策的记录长度解决,但后果是会降智。
展望
谁也没想到,才过了一年,大模型的进化速度如此之快;目前来说,这个工具的问题,大部分都是大模型当下技术的局限性导致,但我相信,未来一定是全智能化的测试方向,也许最终,我们给到工具的测试指令就是一句话:“这里有个 app,你来测一下”
 ,总感觉正文列举的这些场景也挺通用的,不太体现得出来 gpt 的作用,可能多写几个脚本就行,也没太大的维护成本?
,总感觉正文列举的这些场景也挺通用的,不太体现得出来 gpt 的作用,可能多写几个脚本就行,也没太大的维护成本?