AI测试 你们的 AI 赋能测试,成功没?
整理|TesterHome 社区
作者|恒温
4 个月前,TesterHome 社区有同学分享了一篇《史上最全,细数 AIGC 在测试领域落地的困难点》,TesterHome 公众号也进行了转发,当时很多人都觉得这是 chatGPT 写的文案,甚至有人觉得很虚:写这么多陈述的内容,有实际应用了吗?有实践效果了吗?

4 个月前,测试圈几乎人手一个大模型,朋友圈里天天都有人晒如何调试 chatGPT。一晃,4 个月就过去了,忍不住想问问大家你们的 AI 赋能测试,成功没?我估计大多数都不了了之了吧,现在再回头看看《史上最全,细数 AIGC 在测试领域落地的困难点》这篇文章,是不是会有点共鸣?你遇到的问题,早有人替你预判了。
但是我认为,AI 赋能测试这个事情,它可以慢,但是它不能停。技术的前进,总是跌宕起伏,伴随着各种问题,最后慢慢沉寂,变成少数人的坚持,而这少数人的坚持突然有一天有了结果,就会又带来一波高潮。
我现在能看见的是很多大厂仍旧在坚持做这一块的投入。比如 11 月 25 日即将在【深圳登喜路国际大酒店】举办的 MTSC 中国互联网测试大会上,我们就会看到蚂蚁集团、贝壳、去哪儿、字节跳动等公司来分享他们在大模型赋能测试以及如何测试 AIGC 的实践和落地。(P.S 除 25 日正式会议大时段外,11 月 24 日会议前一天,也额外设置了 “AIGC 落地实践” 闭门研讨会(需另外报名),面向对于 AI 落地实践方面感兴趣的同学,组队针对特定议题进行讨论、提出解决方案,最后由讲师评审讨论投票选出优秀方案。
作为评委,我(作者)有幸提前研读了这些议题的 PPT,下面给大家简单介绍下:
AI 赋能测试
自动化的未来:探索基于 LLM 的测试生成技术 -- 字节跳动
利用菜单树让 LLM 理解被测 App 的操作,设计易生成维护的菜单树,并基于此建立低代码平台,再利用低代码平台收集 LLM 所需的自然语言标注数据,巧妙设计 Prompt,利用 LLM 实现文本用例转 DSL 语言,生成自动化用例。对于如何减少 LLM 生成的虚假错误信息,如何提升 LLM 生成自动化用例的有效性,也进行调研和优化。听众通过该议题可以了解如何结合 LLM 实现测试自动化效率提升。
基于大模型 AI 应用在测试域提效难题及解决方案 -- 贝壳
针对现有技术的问题和痛点,基于 AIGC 和开源大模型的新一代测试应用实践,主要介绍了如何利用 langchain 和 llama2 等开源大模型、AI 应用基建的能力去构建垂直领域大模型和实践落地,帮助提高测试人员执行和协助效率,llm 下测试创新。通过该议题,测试同学可以知道利用不同类型的 AI agent 实现测试提效。

AI 自动生成测试用例 -- 去哪儿网
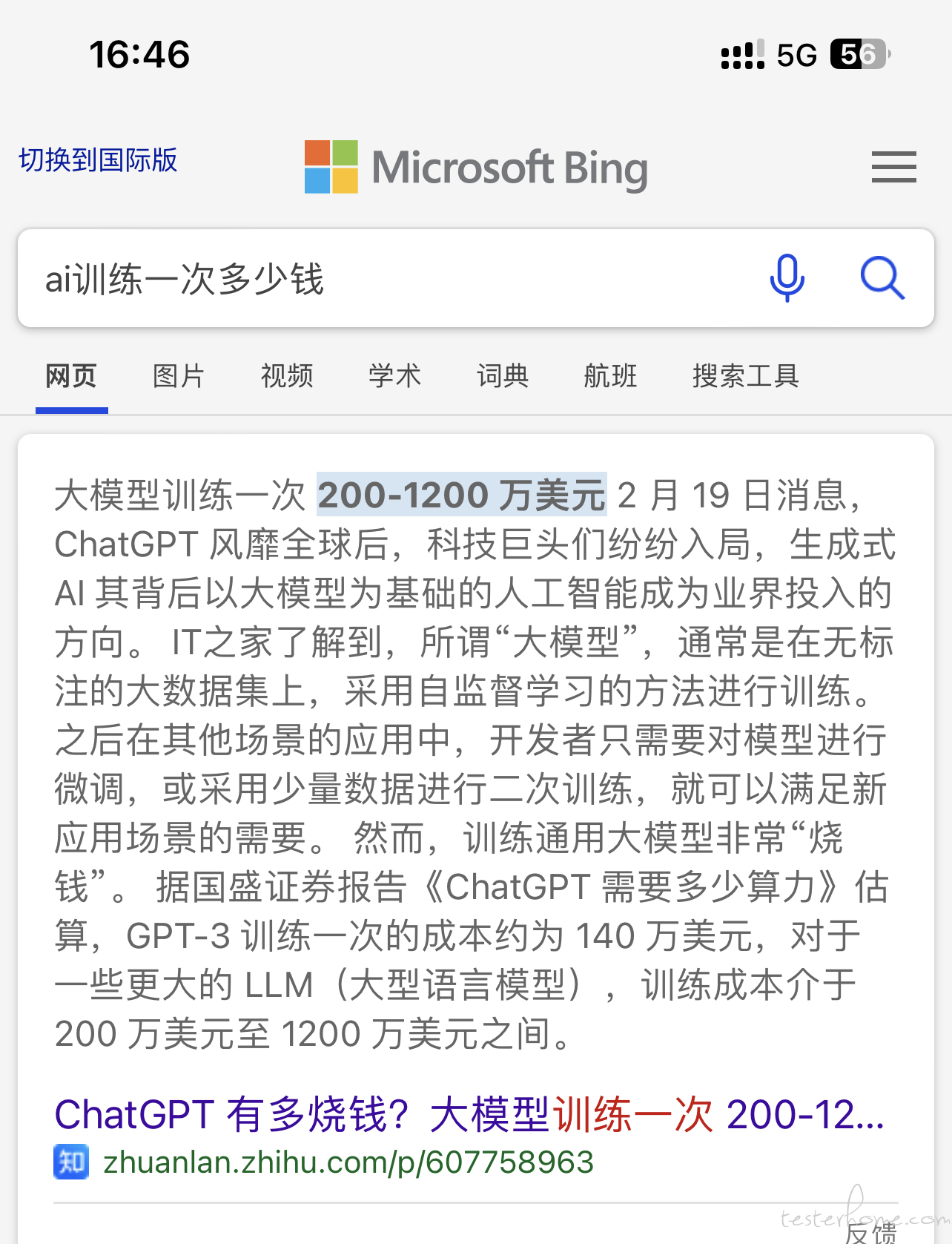
需求沟通效率低,PM、DEV、QA 三方沟通平均耗时 30min-1h、人工写测试用例耗时,平均耗时 1-5h、自测自发需求测试用例覆盖不充分、需文档质量参差不齐。这是去哪儿网的痛点,基于以上痛点,去哪儿网的同学研究基于 AI 自动生成测试用例,包含需求文档解析和预处理、prompt 构建、测试用例自动生成、自动生成脑图可以真实执行。通过这个议题,大家可以看到一个非常完整,可以借鉴并且在自己公司落地的产品。
大模型专场的 AI 赋能测试的议题就这三个,思路比较一致,其实和几个月前也没有发生变化,依旧是在 prompt、agent 上下大功夫,而在垂类模型训练上略微尝试。我想之所以这样,很大部分原因是因为语料质量不高和没有算力吧。
在当今中国互联网的研发模式下,包括需求分析、系统设计、测试分析、测试执行和发布上线等阶段,不同的阶段产生不同的文档,文档的结构、撰写者水平的高地都据定了这些文档的质量。同时,需求、设计、开发和测试之间错综复杂的文档、需求关系也给数据准备带来了一些困难。
计算资源需求:大模型的训练和微调通常需要大量的计算资源,包括高性能的硬件设备和大规模的数据集。众所周知现在 A100 一卡难求,各大公司均在疯狂采购。而各类大模型底座训练所面临的显存墙又真实的拦在大家的面前。
---《史上最全,细数 AIGC 在测试领域落地的困难点》
这些困难当下其实几乎绕不过去了,所以对于测试领域来说,非常优质的针对某个业务的测试垂类模型遥不可及,也就是说 pass@key 实在太低,不能用啊。这样的通用大模型对我们来说,就好比一个不下基层的老专家,他不深入研究系统,但是可以给到我们建议(注:来自复旦计算机学院副院长彭鑫)。而建议好不好用,就看你怎么问,怎么理解,信不信。所以这里就又有一个思路,在现阶段大模型无法达到百分百准确的情况下,在模型结果中进行择优,把最终的选择权交给用户,我们把这个择优的过程自动化掉,其实也一样能达到效果。
AIGC 评测
AI 赋能测试其实是比较小众的事情,目前 AI 领域最火的还是 AIGC,而对 AIGC 的评测的课题其实要大很多。这一块就更难,也更加专业了。本质上来说,我们一直以来做的都是穷举测试,业务功能的测试用例集是有限集。而 AIGC 的理论测试用例集则是无限集。如何有效、高效、并具有一定泛化能力地对 AIGC 进行质量评估,这是一个解决可测性问题的难题。这次 AIGC 评测的两个议题都是来自蚂蚁集团。
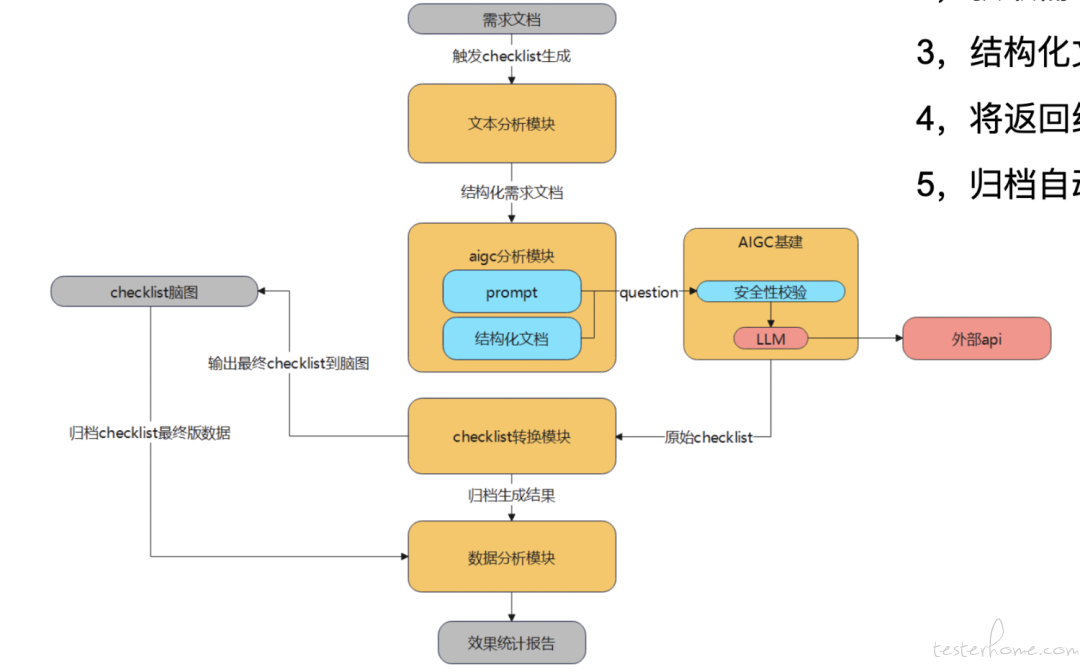
画质革命:VQAGPT 大模型引领支付宝直播和 AIGC 评测新时代 —— 蚂蚁集团
目前,在传统或 AIGC 视觉评测领域,都存在过度依赖主观评测的一个现象,但主观评测相对人力成本较高,特别是在 AIGC 新时代。随着新场景的不断涌现,自动化地评测通用的视觉效果并使其更符合人类审美的需求已迫不及待。传统视觉评测任务依赖主观方法,如何降低传统场景下的人力标注成本?支付宝有大量 AIGC 应用场景,怎么能高效利用无标注数据,降低标注成本?传统场景和 AIGC 场景存在一些共同的评测问题,怎么让大模型解决一些共性问题?支付宝在这一方面有着非常多的沉淀,听众通过该议题可以了解传统直播场景和 AIGC 场景的视觉效果评测难点和支付宝在该领域上的一些解决方案,方法论和思路都值得借鉴。
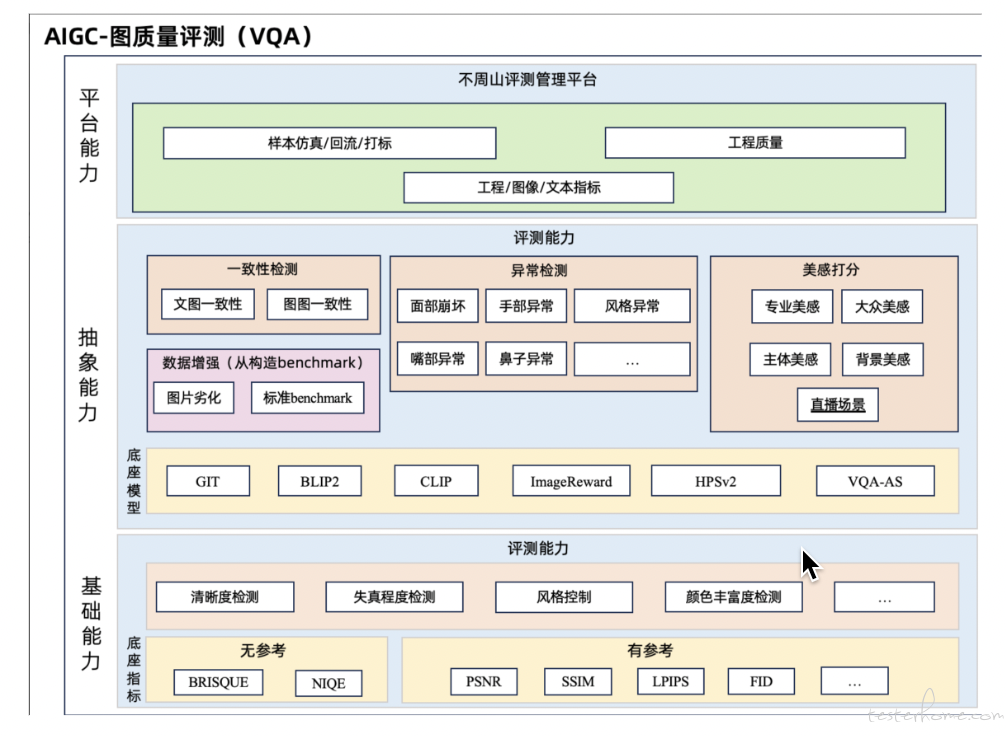
AIGC 图像生成的质量保证:测试难题与解决方案的深度剖析 -- 蚂蚁集团
鲸探是蚂蚁数科的一款数字藏品售卖平台,有兴趣的朋友可以应用市场下载玩玩。在 2023 年 5 月上线了 AIGC 在线生图的功能,在 AIGC 业务测试中,最核心的一项工作是评估 AIGC 图像生成算法的实际效果,但面临的挑战有:AIGC 图像生成质量问题如何定义?如何构建 AIGC 图像生成质量算法模型?如何能够检测 AIGC 生成图像中的一些问题?如何构建 AIGC 图像生成质量体系?蚂蚁数科质量团队通过各种调研,参考借鉴,初步攻克了这些问题,取得了不错的结果。听众通过该议题,可以了解 AIGC 图像生成算法测试中遇到的难题以及从蚂蚁数科质量团队的解决方案中获取一些启示。
总结
通过各位讲师的 ppt,我们是可以看到微小但是可喜的进步的。对于 AI 赋能测试这块,我们一直是两条腿走路,一条就是垂类模型的微调,致力于打造出一个真正的测试专家模型,另外一条就是我们现在在走的,既然底子不够好,那就在外面多包几圈,我有个同事说这叫螺蛳壳里做道场。但是我们其实坚信,一个和测试专家能力不相上下的大模型才是未来,这条路任重而道远,或者用句时髦的话,也许突然就涌现了。
最后,囿于篇幅问题,不能详细介绍,也给大家留个念想,真正有志于此的同学,不要错过这次专场了。
测试开发圈年度技术交流大会
MTSC2023 深圳站,报名从速|MTSC2023 深圳大会 11 月 25 日举行,议题总揽、大会亮点(点击查看)
扫码购票
▼

MTSC 2023 第 12 届中国互联网测试开发大会(深圳站)即将于2023年11月25日,在『深圳登喜路国际大酒店】举办,大会将以 “1 个主会场 +4 个平行分会场” 的形式呈现,聚集一众顶尖技术专家和行业领袖。他们将围绕如今备受关注的行业热点话题以及最前沿的实践经验,进行深入探讨和分享。
其中,将有众多业界大咖,分享 AI 在软件测试和质量保量领域的洞察和实践。
比如在 11 月 25 日上午的主会场,来自中国信息通信研究院的刘硕老师,将为大家分享《人工智能生成内容(AIGC)发展趋势及评估体系探索》。
此外,在 11 月 25 日下午的【LLM 下测试创新】专场,来自蚂蚁数科的李挺老师、字节跳动的龙吕老师、蚂蚁集团的罗军老师和毕健旗老师、贝壳的原玉娇老师、去哪儿网的刘子涵老师,都将分享 AI、大模型在软件质量保障领域的创新探索。

此外,大会前一天,11 月 24 日,社区还组织了【AIGC 主题 闭门研讨会】,面向对于 Al 软件测试应用、降本增效等技术管理等方向,组队针对特定议题进行讨论、提出解决方案,最后由讲师评审讨论投票选出优秀方案。感兴趣的同学,可以联系票务同学进行咨询报名。
联系方式
票务联系
静静:hahalovesj(微信)
敏敏:18210285475
(团体参会:联系上面人员可享更多优惠)
商务合作
联系人:徐士钊
邮箱:bd@testerhome.com
电话:15910532052(微信同号)
报名通道:报名购票戳这里