这是我写的 web ui 自动化脚本
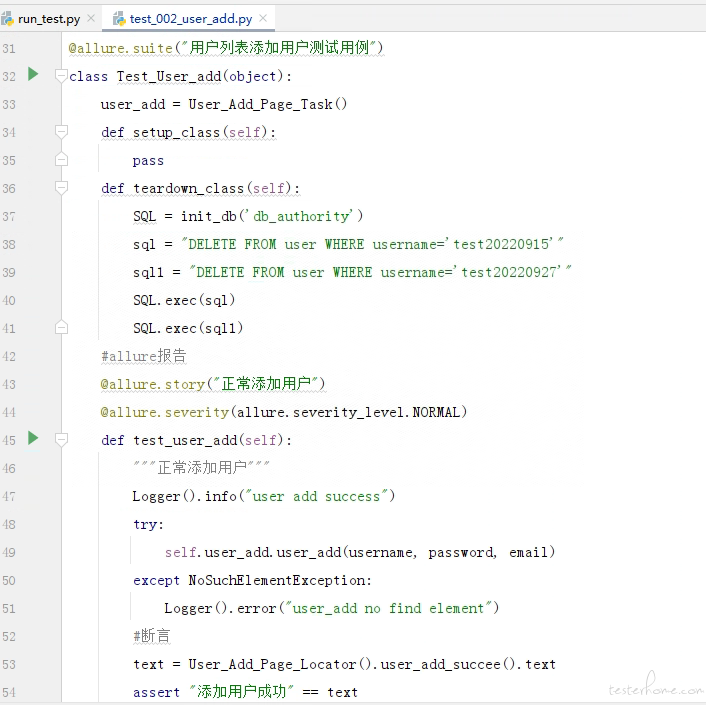
UI 自动化脚本已经部署到了 jenkins
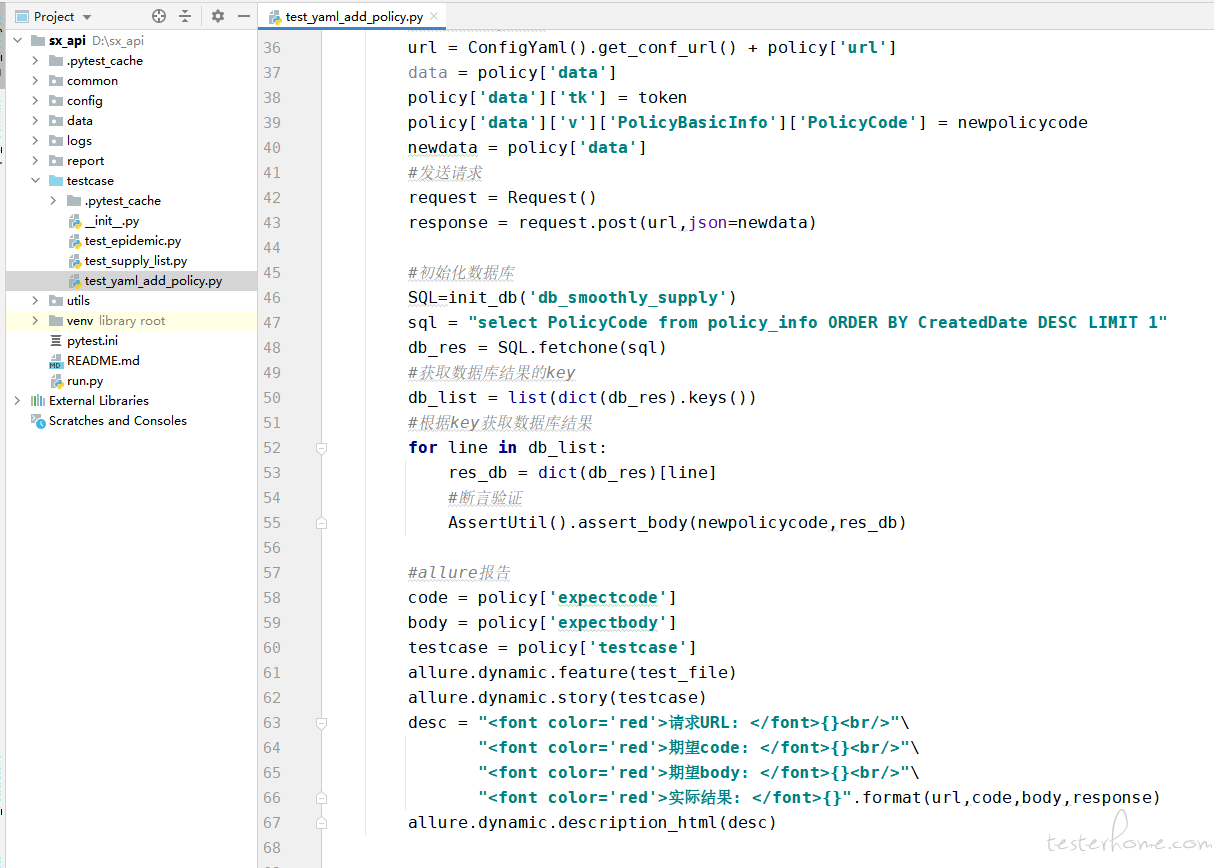
这个是接口自动化的脚本,接口自动化目前还没有往 jenkins 部署
我就是想知道,我这跟公司真实的自动化还缺了那些东西,或者说我写的哪里不对?
以后的计划是把框架进行封装,写自动化测试平台
资料有点少,不好评价反馈,只能留点疑问,楼主可以看下有没有做好:
1、UI 自动化里面,框架是否有提供什么机制便于提高用例稳定性?(如找元素的自动等待等)
2、UI 自动化脚本的写法里,怎么尽可能让代码容易复用?(如 PageObject,从代码看有 Page 的概念,但不确定是不是用了 PO 模式)
3、一旦有报错,框架层是否可以捕获并输出足够清晰的日志等信息,便于使用者基于日志就可以定位并解决问题?
接口自动化:
1、一般接口自动化的特点是数量多,如果每一个都得写不少代码的话,编写维护成本会相对高。针对这块是否有评估过一个接口用例按现在框架写,大概要多久?
2、从这个截图看,有不少代码是为把报告输出到 allure 服务的。不确定这部分是不是用例,如果是,可以考虑下把这部分由框架直接代劳,而不用每个用例自己写?
3、类似 UI 自动化,接口自动化也有流程型的用例的,通过调用多个接口形成一个流程进行测试。不知道是否有考虑过脚本如何分层,让流程型用例和单接口用例,都能尽量复用一些公共代码,降低编写成本?
4、接口测试很多时候会需要测试多个环境,从脚本看像是从一个全局配置文件里直接获取 url 的,建议框架可以提供多环境分开配置的能力(类似 spring 里面可以分别为 dev 和 prod 设定不同的配置项对应值)。
最近在研究这方面的东西,就是想知道,我写的这个跟真实的公司做自动化差别在哪里?
资料有点少,不好评价反馈,只能留点疑问,楼主可以看下有没有做好:
1、UI 自动化里面,框架是否有提供什么机制便于提高用例稳定性?(如找元素的自动等待等)
2、UI 自动化脚本的写法里,怎么尽可能让代码容易复用?(如 PageObject,从代码看有 Page 的概念,但不确定是不是用了 PO 模式)
3、一旦有报错,框架层是否可以捕获并输出足够清晰的日志等信息,便于使用者基于日志就可以定位并解决问题?
接口自动化:
1、一般接口自动化的特点是数量多,如果每一个都得写不少代码的话,编写维护成本会相对高。针对这块是否有评估过一个接口用例按现在框架写,大概要多久?
2、从这个截图看,有不少代码是为把报告输出到 allure 服务的。不确定这部分是不是用例,如果是,可以考虑下把这部分由框架直接代劳,而不用每个用例自己写?
3、类似 UI 自动化,接口自动化也有流程型的用例的,通过调用多个接口形成一个流程进行测试。不知道是否有考虑过脚本如何分层,让流程型用例和单接口用例,都能尽量复用一些公共代码,降低编写成本?
4、接口测试很多时候会需要测试多个环境,从脚本看像是从一个全局配置文件里直接获取 url 的,建议框架可以提供多环境分开配置的能力(类似 spring 里面可以分别为 dev 和 prod 设定不同的配置项对应值)。
去看 poium 和 seldom 项目,github 自己找,那是落地的工程类项目,不是 kpi 项目
脚本距离框架还有很长的路要走,要想做一个团队都能用的框架,至少要解决几个问题:1
1、用例去脚本化,比如 Excel、json 维护用例
2、入参数据解决,比如数据库依赖、接口依赖
3、断言问题与问题 2 类似
4、登录、加解密、验证码等项目非通用性问题
5、报告输出,不能光有简单的执行结果,还要统计接口数、覆盖率等更丰富的数据展示维度
共勉
https://gitee.com/zx660644/uitest
落地了的 ui 自动化项目
看了,你的回复,我先修改下 ui 自动化的测试框架,UI 的问题,你说的 1,2,3, 2 和 3 有做,但是还是有问题,1 我用的隐式等待和强制等待,觉得不太好,打算改


https://blog.csdn.net/dream_back/article/details/118751500
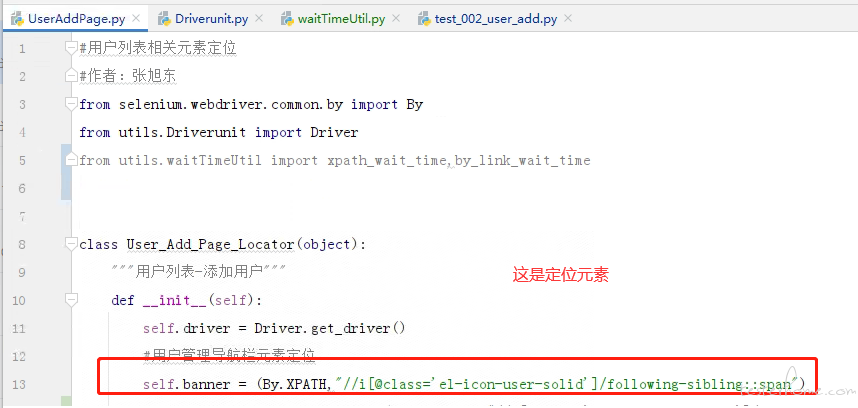
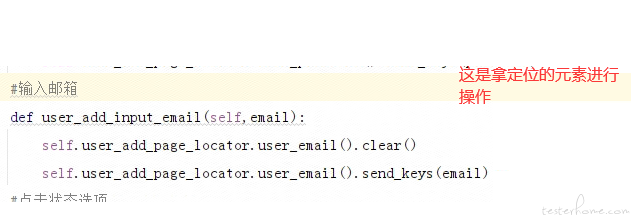
我找了一篇博客,看了别人封装的 po,觉得我现在的 po 有很大问题,定位元素的部分太过繁琐,而且还把业务的测试流程放在 page 里了
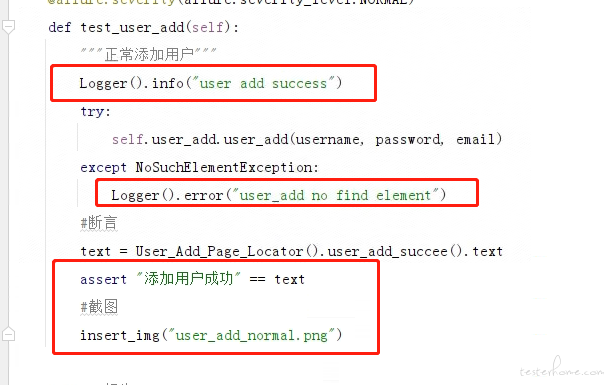
页面就是页面 动作就是动作 页面只维护元素对象 动作单独抽象出来 不建议写在页面对象里
写用例时再把元素和动作组合起来
嗯,我设计的确实这块问题很大,已经在重构了,打算封装一个基类 basepage 把启动浏览器,元素定位的类型,操作等单独封装起来
楼主,代码可以贴代码。markdown 的代码块。别截图。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as ec
class Page():
def __init__(self):
self.driver = webdriver.Chrome()
def open(self):
self.driver.get("https://www.baidu.com")
self.driver.maximize_window()
def __find_element__(self, lc, locator):
"""元素定位"""
if lc == "id":
ele = self.driver.find_element(By.ID, locator)
print(type(ele))
WebDriverWait(self.driver, 10).until(ec.visibility_of_element_located(ele))
a=Page()
a.open()
a.__find_element__('id','kw').send_keys('python')
我打算重构的 basepage 页,简单调试了下,报了这个错
<class 'selenium.webdriver.remote.webelement.WebElement'>
Traceback (most recent call last):
File "D:/demo_123/basic/page.py", line 48, in <module>
a.__find_element__('id','kw').send_keys('python')
File "D:/demo_123/basic/page.py", line 19, in __find_element__
WebDriverWait(self.driver, 10).until(ec.visibility_of_element_located((ele)))
File "D:\demo_123\venv\lib\site-packages\selenium\webdriver\support\wait.py", line 81, in until
value = method(self._driver)
File "D:\demo_123\venv\lib\site-packages\selenium\webdriver\support\expected_conditions.py", line 125, in _predicate
return _element_if_visible(driver.find_element(*locator))
TypeError: find_element() argument after * must be an iterable, not WebElement
可以参考下 RF 的设计 ,动作就是动作 元素就是元素
执行用例时 就是元素 + 动作 来完成一次操作 比如
1、用户名元素 + 输入 (参数)
2、密码元素 + 输入(参数)
3、登录按钮元素 + 左键点击
打个比方
类似于 selenium 本身也封装了 click 方法
你可以再封装一层 把 driver.click + Action 类的 Click + JavaScript 的 Click 封装到一起 做成自定义的动作 myClick 简化脚本开发的操作
元素的定位方式和用例数据可以单独抽离出来,实现脚本与数据分离
def find_element(self, lc, locator,timeout=''):
"""元素定位"""
if lc == "xpath":
ele = WebDriverWait(self.driver, timeout=10)\
.until(EC.visibility_of_element_located((By.XPATH,locator)))
class Login_Page_Locator(BasePage):
"""登录页元素定位"""
username = ('xpath', '//input[@placeholder="请输入用户名"]')
password = ('xpath', '//input[@placeholder="请输入密码"]')
submit = ('xpath','//span[text()="登录"]')
class Test_Login(object):
loginpage = Login_Page_Locator()
base = BasePage()
@allure.story("登录用例")
@allure.severity(allure.severity_level.BLOCKER)
def test_login1_normal(self):
"""username and passwd is normal"""
Logger().info('test_login success')
try:
#输入用户名
self.base.find_element(self.loginpage.username[0],self.loginpage.username[1]).send_keys(username)
except NoSuchElementException:
Logger().error('login no find element')
#assert username == "admin"
#insert_img("login_normal.png")
为什么我这样写,一直在定位元素
好了,已经解决了上面的问题了,但是不知道为什么会启动两次浏览器,我再看看
还有,帮我看下,我这样写有啥问题吗,我现在感觉这样写,测试用例里面,取定位元素的方式,和值,那块有点繁琐,不知道能不能再优化
base.find_element(loginpage.username[0],loginpage.username[1]).send_keys(username)
就这一块
确实比较繁琐 其实现在的前端响应式框架 基本都得靠 xpath 来定位元素了 所以你可以给个默认值为 xpath 可以省一个参数 另外定位元素的方法还需要多扩展几个 至少要覆盖常用的显示等待预定义条件以及自定义条件的场景
其实如果你是想要做框架的话 最好能让脚本能脱离代码环境 能通过编辑配置文件来编写用例脚本
嗯,元素定位的方法我写了很多,什么 id,name,等,粘贴的代码只粘贴了一个 xpath 的,确实,我写的时候好多定位都是 xpath, 你说的让脚本脱离代码环境,是说的数据驱动,关键字驱动吗,这个我有考虑做,后面计划是想做成这样
1、默认为 xpath 如果不是再传可选参数
2、是这个意思 在代码里定义规则和 Api 通过配置文件来实现业务脚本
推荐你看看教程
https://coding.imooc.com/class/592.html
一整套 ui 自动化测试流程落地