性能测试工具 性能测试工具之的 web 动态请求仿真度对比测评分析报告
1. 概述
在《虚拟用户的 web 静态请求仿真度对比测评分析报告》报告中,我们了解到无论被测对象的请求模型是什么样的,Jmeter 工具的虚拟用户请求的并发模型都是串行的,LoadRunner11 工具的虚拟用户请求模型都两个两个并发的,而对于 LoadRunner12 版本就具有了有很高的是相似度。
本文在《虚拟用户的 web 静态请求仿真度对比测评分析报告》一文本的基本上进一步比较 WEB 动态请求仿真度。WEB 的 http 请求分为静态请求和动态请求,所谓动态请求,就是由浏览器执行相关代码而动态产生的 http 请求,如:javaScript
2. 概述
在《虚拟用户的 web 静态请求仿真度对比测评分析报告》报告中,我们了解到无论被测对象的请求模型是什么样的,Jmeter 工具的虚拟用户请求的并发模型都是串行的,LoadRunner11 工具的虚拟用户请求模型都两个两个并发的,而对于 LoadRunner12 版本就具有了有很高的是相似度。
本文在《虚拟用户的 web 静态请求仿真度对比测评分析报告》一文本的基本上进一步比较 WEB 动态请求仿真度。WEB 的 http 请求分为静态请求和动态请求,所谓动态请求,就是由浏览器执行相关代码而动态产生的 http 请求,如:javaScript
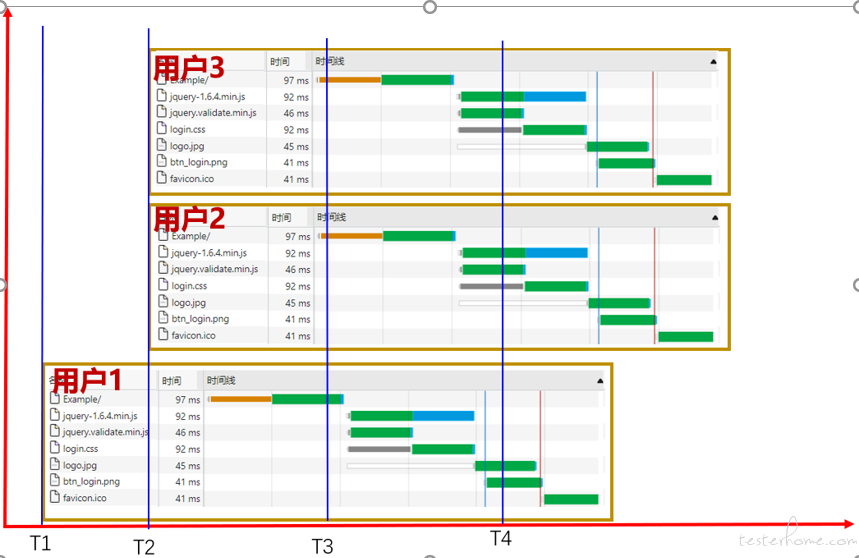

在 T1 时刻,只有虚拟用户 1 在运行,在 T2 时刻有虚拟用户 1-3 在运行。用户 1、用户 2、用户 3 之间的并行关系是虚拟用户并发模型。一般的性能测试工具的场景配置的就是虚拟用户并发模型,即虚拟用户之间的,而虚拟用户请求并发模型是在制作脚本的时候确定的。
虚拟用户请求的并发模型与浏览器的相似程度越高,我们就认为虚拟用户请求仿真度越高。虚拟用户请求仿真度的高低,对性能测试工具的测试结果影响非常的大具大。
3. 浏览器的请示并发模型
打开浏览器,在地址栏输入 URL 地址,浏览器就会显示我们平时看到的图形界面。浏览器与 WEB 服务端之间的交互,如下图所示。

浏览器与 WEB 服务器之间是协议通信交互,而与使用者之间是图形界面,在浏览器内部对协议通信的内容作了相应的图形转换,使普通的使用者能够看懂。如下所示的一个页面,图形界面显示的是一个用户登录界面,要求输入帐号、密码、验证码,还提从了一个登录按钮。对于通信层面,却有 7 个请求。
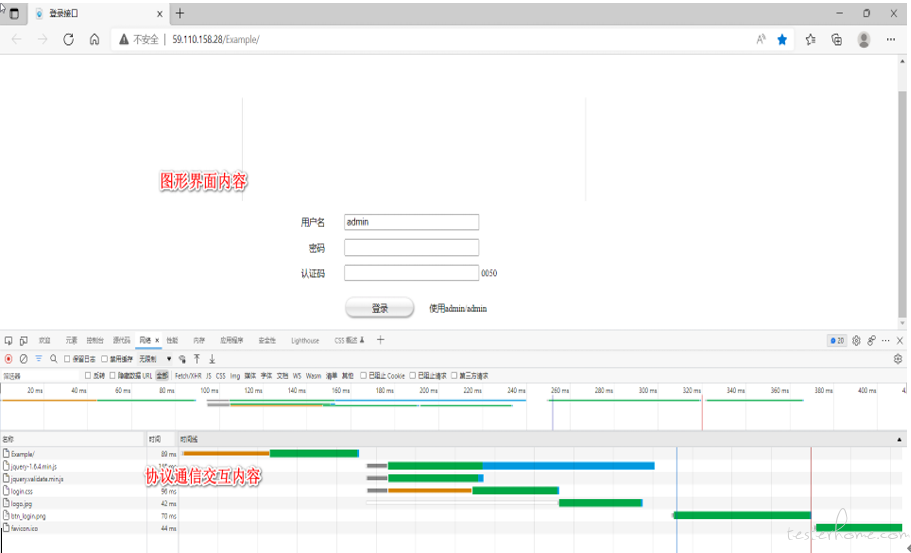
注:打开浏览器按 F12 键,并切换到 Network 或网络 页签,即可看到浏览器与 WEB 服务器之间的交互。上图的时间线,就是浏览器与 web 服务端之间请求的并发模型。对于性能测试工具的虚拟用户请求并发模型要与浏览器相一致。
4. 测试环境
4.1.测试环境配置

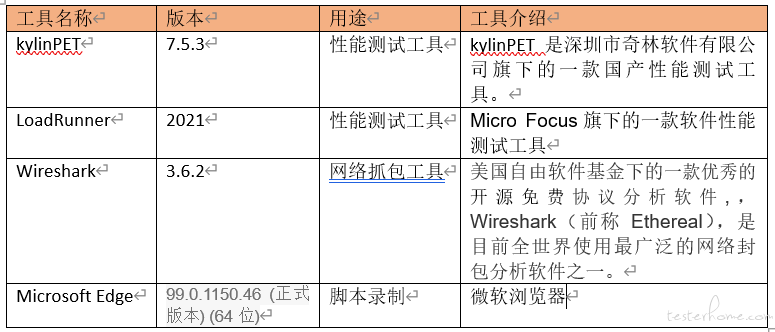
4.2.测试工具
4.3.测试环境组网

图 4-3-01
4.4.被测试对象
http://59.110.158.28/Example/
图 4-4-01
5. HTTP 请求仿真度对比
5.1.测试思路
步骤 1:Loadrunner、kylinPET 具录制同一个网页
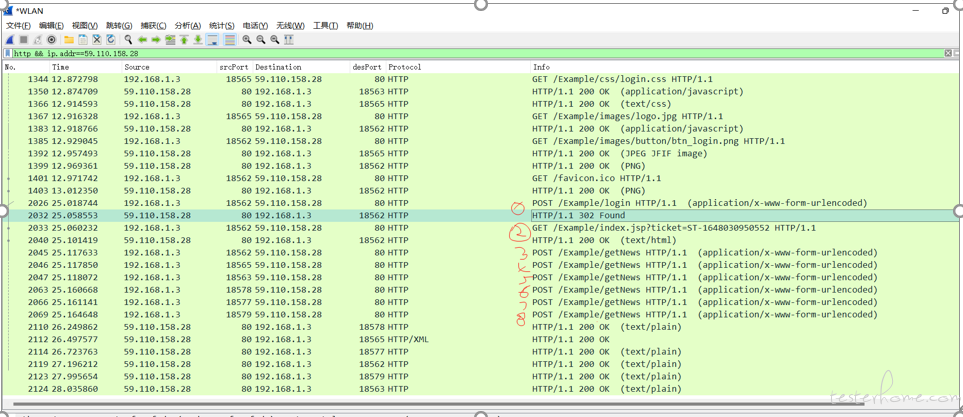
步骤 2:建立测试计划,各自运行脚本一次,运行的过程通过(wireShark 抓包)
步骤 3:通过对 wireShark 网络抓包结果分析 HTTP 请求的顺序,然后和浏览器产生的请求并发模型对比。
注:kylinPET 工具能够记录录制和执行过程中的 HTTP 请求顺序,但 loadrunner 无此功能需要通过抓包分析。
5.2.对比基线
5.3.Microsoft Edge 浏览器的请求并发模型
使用 Edge 浏览器单独方问题 Web 服务器并记录并发请求模型,如下所示,通过打开主页输入用户名称、密码、验证码登录后,浏览器记录的请求并发模型。
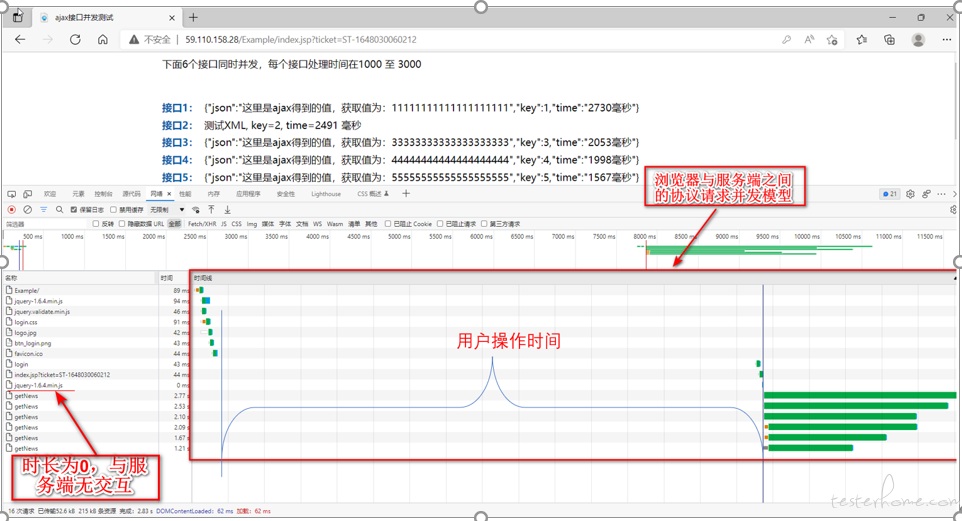
用户操作时间是用户在输入帐号、密码、验证码以及点击登录按钮时花费的界面操作时间。
在以上请求中,最后 6 个请求为动态请求,其余为静态请求。后续的请求并发模型比较,我们重点关注后面的动态请求。
注:上图中时长为 0 的请求,通过 wireshark 抓包看,没有相应的请求包。
5.4.KylinPET 仿真度分析
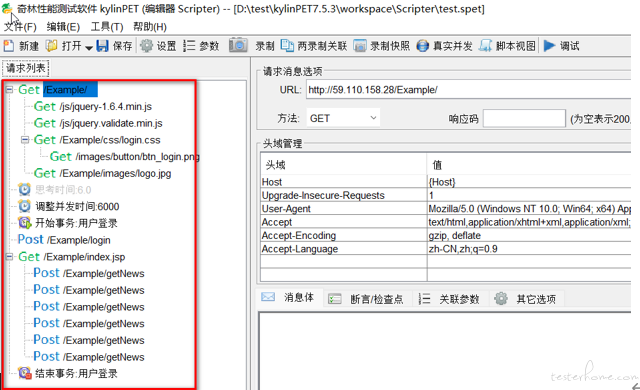
5.4.1.kylinPET 脚本录制:Edge 浏览器代理录制
通过浏览器模型进行脚本录制获得如下的脚本
5.4.2. 执行性能测试任务
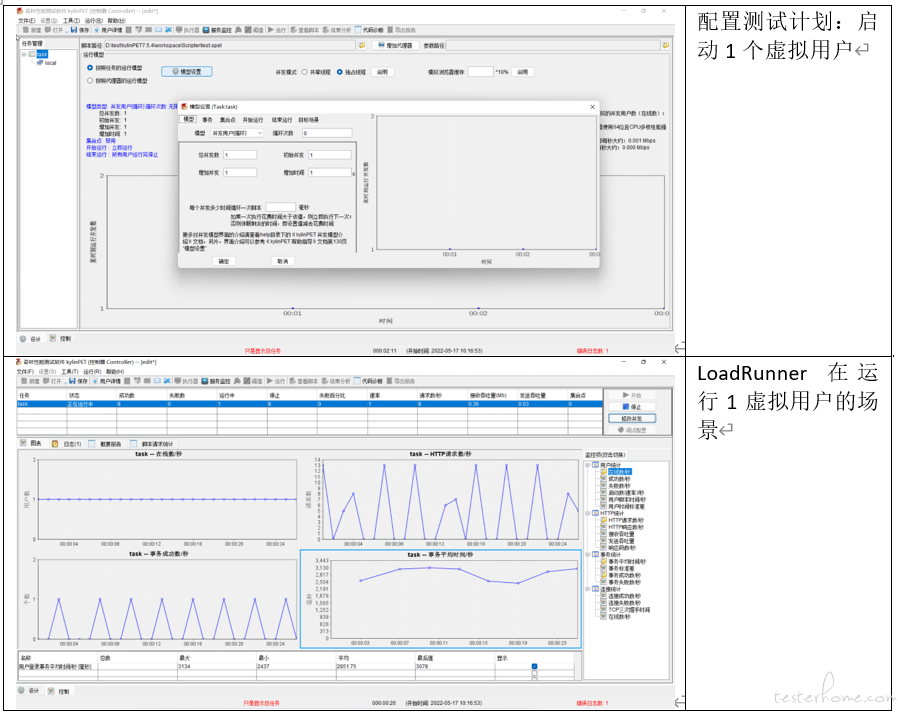
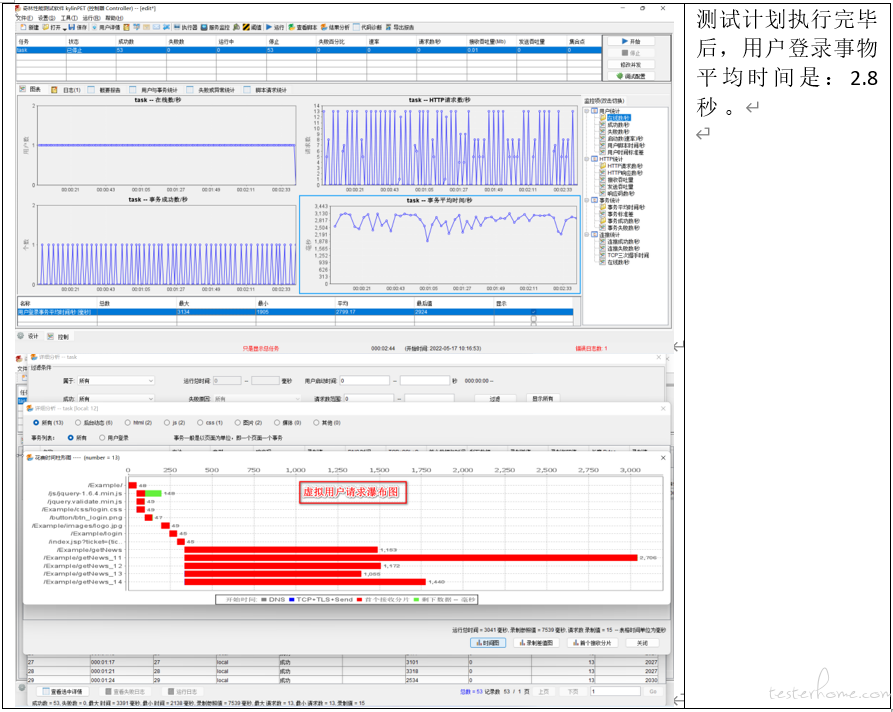
5.4.3. 测试结果分析
kylinPET 的性能测试计划执行获得用户登录事务时间与预期时间相符(预期时间在 2 秒-3 秒之间),同时它的 HTTP 请求瀑布图与浏览器单独访问 URL 得到的请求并发模型相一致。
5.5.LoadRuner12 仿真度分析
5.5.1.脚本录制:基于 HTML 的脚本
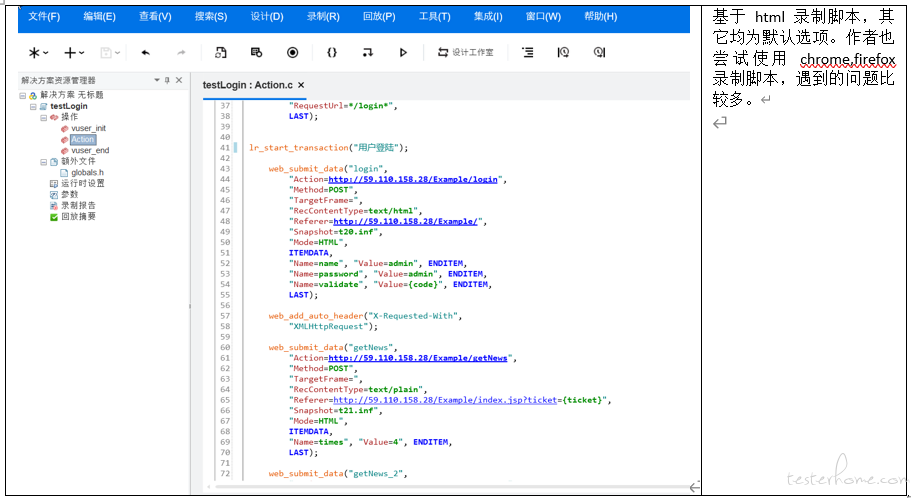
5.5.2.执行测试计划
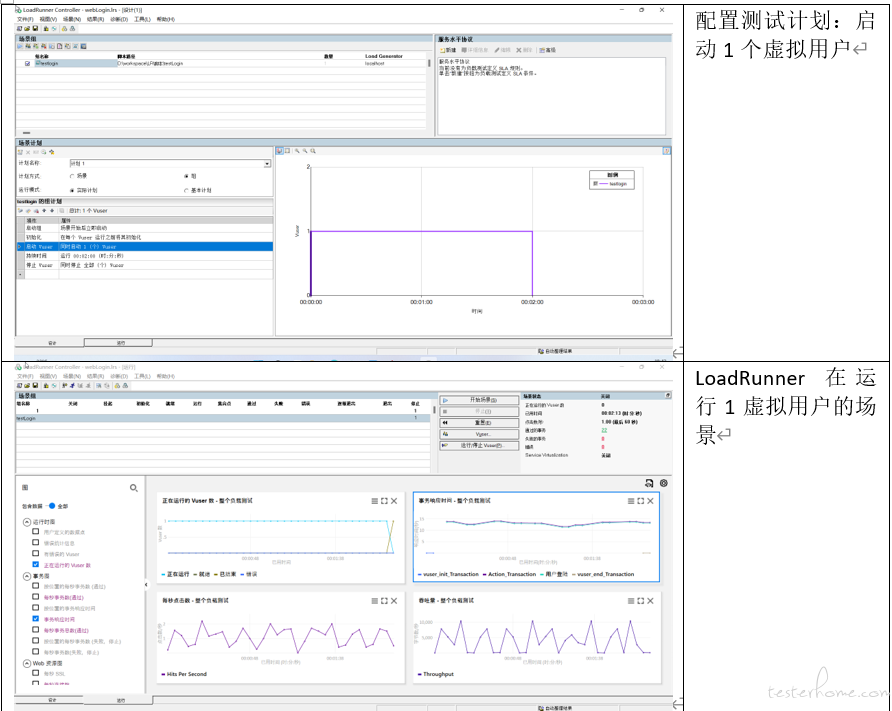
下图是任务执行通过 wireShark 抓包绘制得到请求并发模型图(loadRunner 本身不提供虚拟用户请求并发模型图)
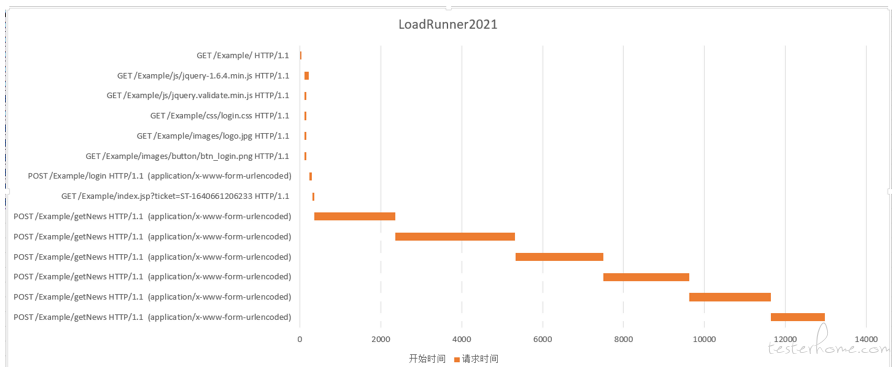
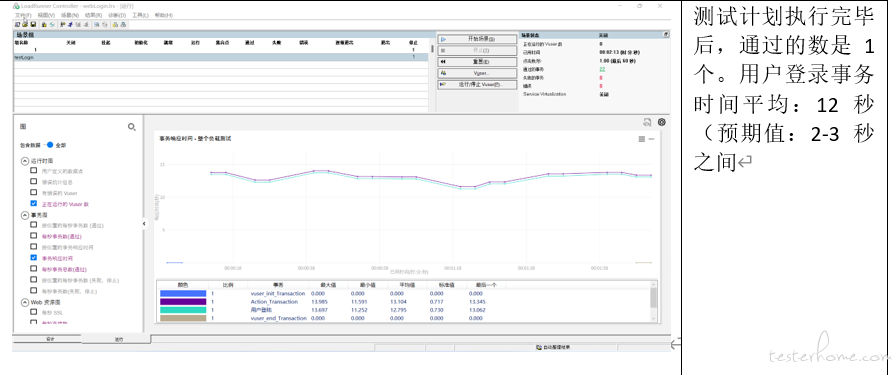
5.5.3.测试结果分析
1、 用户登录事务时间为 12 秒,远超事务的实际时间
2、 通过抓包分并绘制请求瀑布模型分析看,用户登录事务的 6 个动态请求 loadrunner 处理为串行模式(实际为并行),导致事务时间拉长。(并发请求时事务时间取决于最大请求的时间,串行时间事务时间为所有请求时间的累加值)
5.HTTP 请求仿真度对比总结
KylinPET 可以正确处理 web 的动态请求模型,并获得正确的事务时间。LoadRunner 在处理 web 动态请求时,把并行请求错误的处理为串行,导致事务时间拉长,获得错误事务时间,如果同样我们在使用 loadRuner 测试系统的压力测试时,相同样的的在线虚拟用户数,对系统的压力就会小 6 倍,导致测试不准,得出错误的系统允许最大在线用户数。