在项目上使用自动化测试,是为了跑主流程的回归测试,提高测试效率,在每个测试版本中把主要的精力放在发版内容新增的需求中;
根据项目的功能模块,把业务主流程和使用频率高的功能抽取出来进行自动化测试,作为发版前的主流程回归测试辅助作用;
大致的流程是:
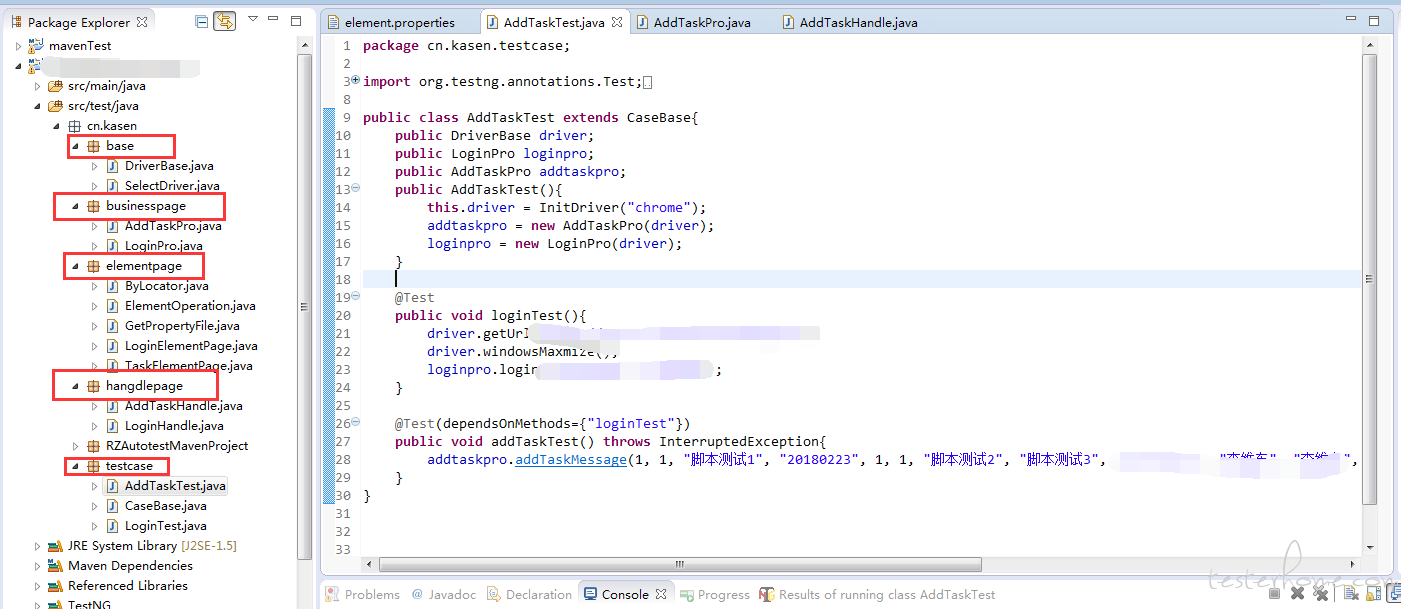
1、先做 po 设计,把最原始的脚本重构封装并参数化,初步设想,base 层,element 定位层,handle 层,business 层,最后是 testcase 层;
base 层,用于传入 browser(浏览器的选择,便于以后扩展兼容性测试)和 driver 的基本方法(findElement,url 的获取,frame 的切换,窗口放大);
element 定位层,用于各业务 page 中元素的获取封装、By 元素定位方式的封装、从配置文件根据 key-value 的形式读取元素定位方式和定位值的封装;
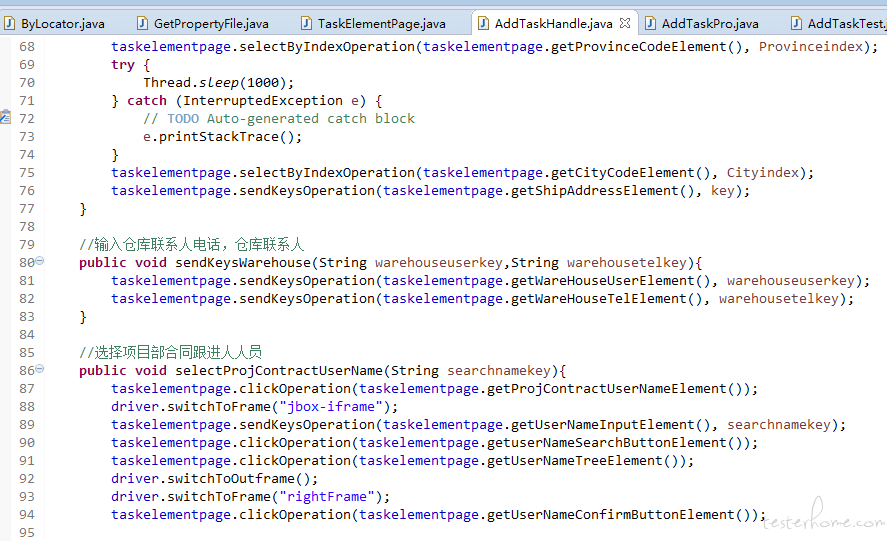
handle 操作层,用于根据页面模块 page 中的元素的操作封装;
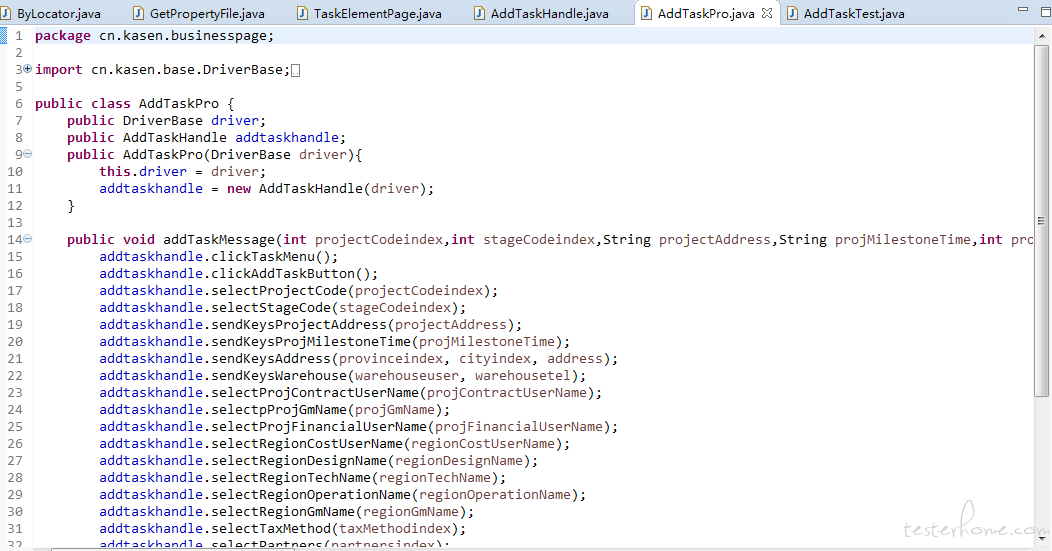
business 业务层,用于业务逻辑操作;
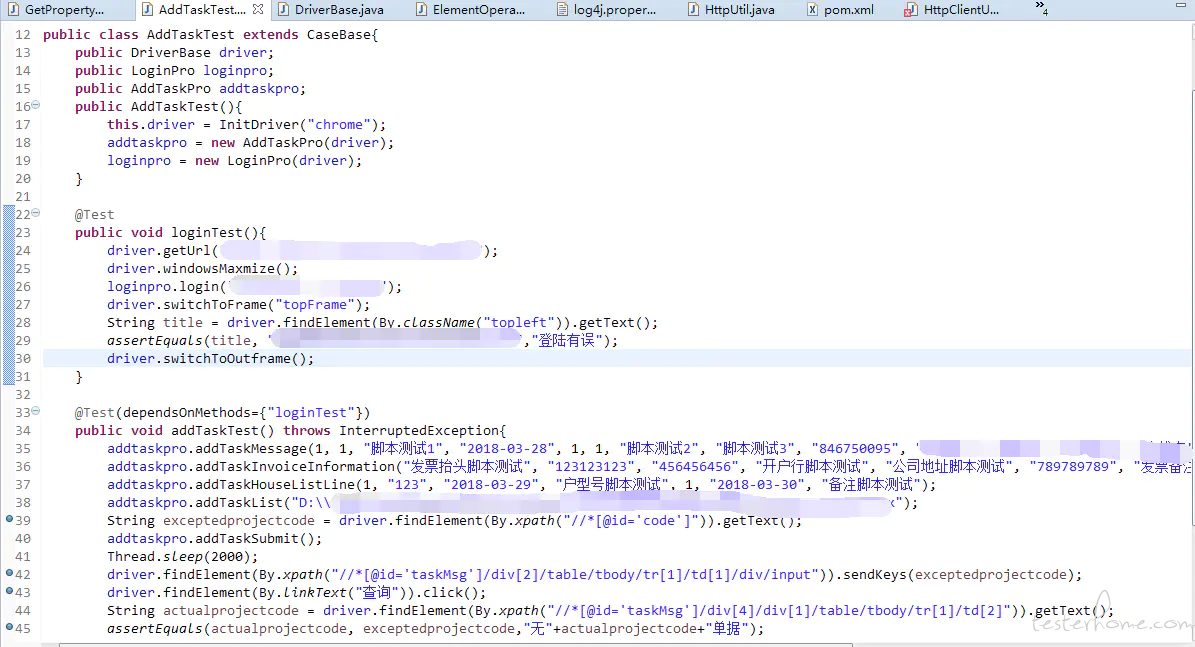
testcase 层,用于组装 case,输入测试数据和断言判断;
2、建成 maven 工程,调用第三方的 jar 优化,实现日志收集,TestNG 的使用,测试报告的生成以及 jenkins 的配置;
下面每层贴部分的典型代码展示:
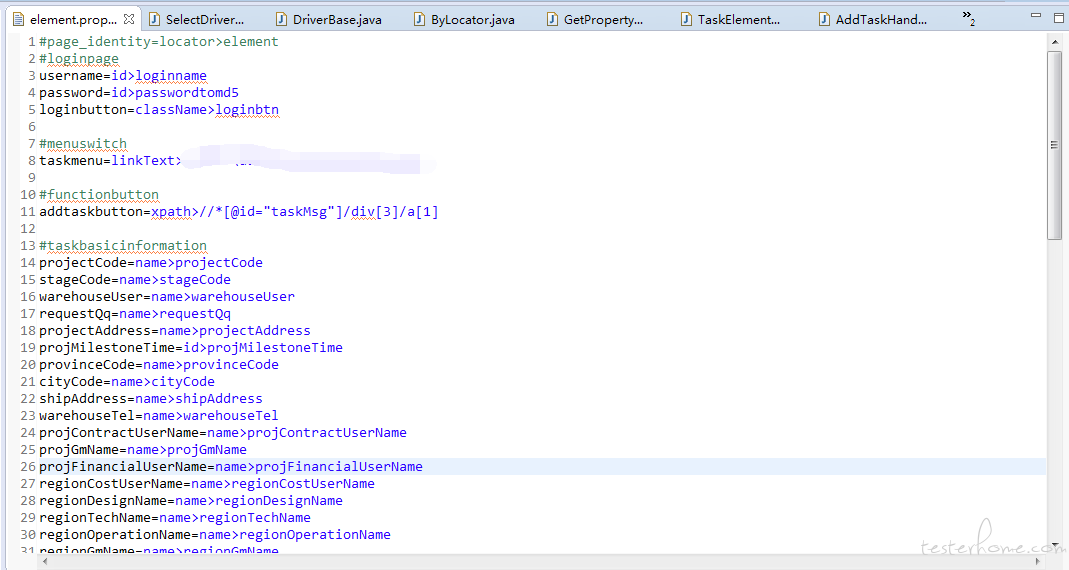
配置文件内容:
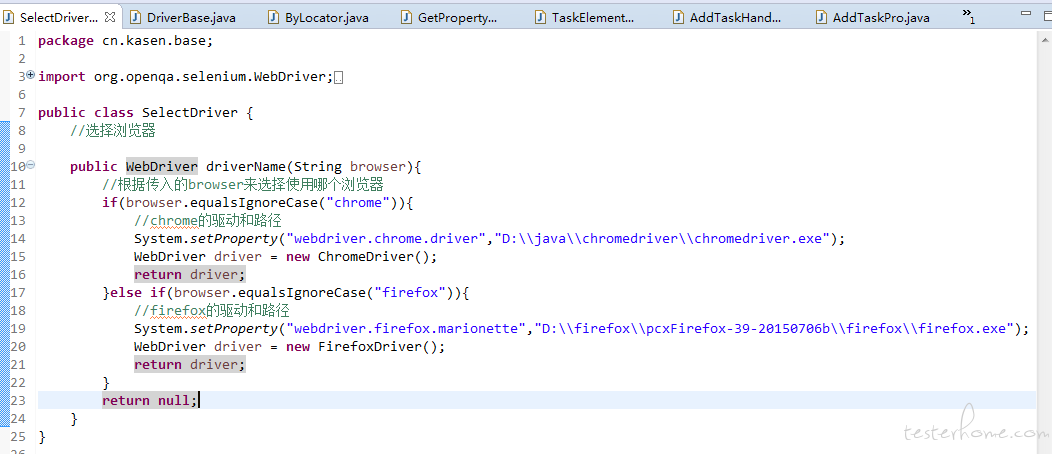
浏览器选择:
driver 基本方法重新封装:

读取配置文件内容,By 封装
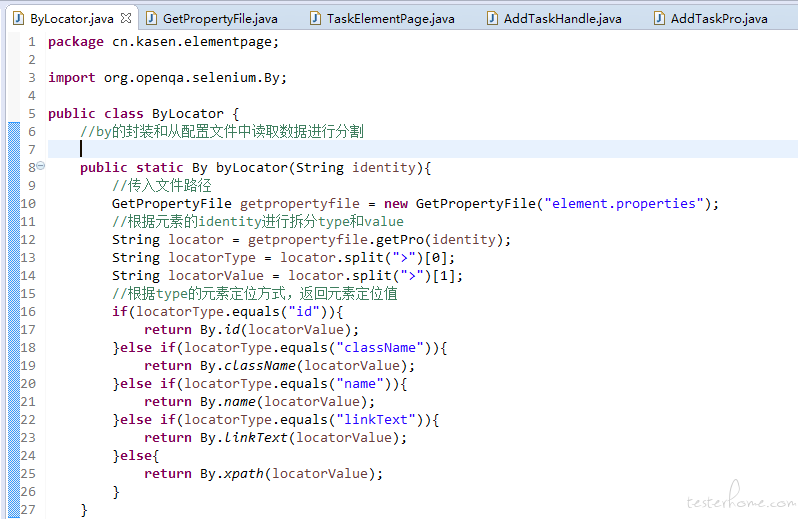
element 定位层:
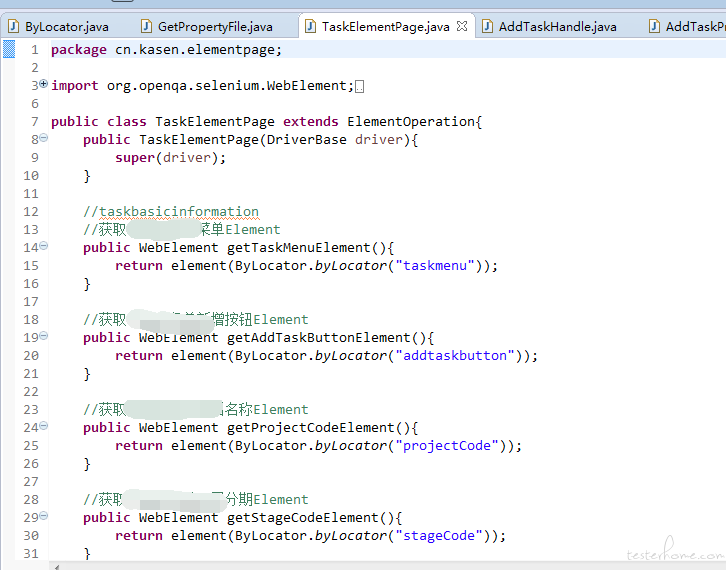
handle 操作层:
business 业务操作层:
testcase 层:
「原创声明:保留所有权利,禁止转载」
