测试基础 音频质量评估及音频处理常用功能
背景
最近新上的一款机器人,有视频通话功能,发送端通过音视频 SDK 传输到接收端,需要对音视频做一些质量评估。本篇仅包含:音频处理常用功能,以及音频的质量评估。
各种专业知识和公式,是真心看不懂。只是对 google 结果的一次汇总,作为笔记记录。
1、常用的质量评估算法
(1)python-pesq(PESQ)
2001 年 2 月,ITU-T 推出了 P.862 标准《窄带电话网络端到端语音质量和话音编解码器质量的客观评价方法》,推荐使用语音质量感知评价 PESQ 算法,该建议是基于输入 - 输出方式的典型算法,效果良好。
PESQ 算法需要带噪的衰减信号和一个原始的参考信号。开始时将两个待比较的语音信号经过电平调整、输入滤波器滤波、时间对准和补偿、听觉变换之后, 分别提取两路信号的参数, 综合其时频特性, 得到 PESQ 分数, 最终将这个分数映射到主观平均意见分 (MOS)。PESQ 得分范围在-0.5--4.5 之间。得分越高表示语音质量越好。
代码实现:
def get_pesq(clean_wav, denoised_wav):
"""
计算两个音频的pesq,要求采样率为16000或8000,且8000只支持窄带。
PESQ就是用经过处理后的语音文件(语音压缩、重构等)与原始语音进行比较。PESQ得分范围在-0.5--4.5之间。得分越高表示语音质量越好。
git: https://github.com/vBaiCai/python-pesq
:param clean_wav: 原始文件
:param denoised_wav: 待评估文件
:return: score
"""
ref, sr0 = sf.read(clean_wav)
deg, sr1 = sf.read(denoised_wav)
# 检查采样率是否达标
if sr0 == sr1 and (sr0 == 16000 or sr0 == 8000):
logger.info("ref_audio/deg_audio音频采样率为: %s/%s" % (str(sr0), str(sr1)))
else:
logger.error("音频采样率必须为16000或窄带8000。ref_audio/deg_audio音频采样率为: %s/%s" % (str(sr0), str(sr1)))
return False
# 检查两个音频文件长度,帧数相差不大于10
if abs(len(ref) - len(deg)) > 10:
logger.error("ref_wav/deg_wav两个音频长度不一致: %d/%d" % (len(ref), len(deg)))
return False
score = pesq(ref, deg, sr0)
logger.success("PESQ算法计算的MOS值为:%s" % str(score))
return score
(2)信噪比 (Signal-to-Noise Ratio,SNR)
SNR 一直是衡量针对宽带噪声失真的语音增强算的常规方法。但要计算信噪比必需知道纯净语音信号,但在实际应用中这是不可能的。因此,SNR 主要用于纯净语音信号和噪声信号都是己知的算法的仿真中。 信噪比计算整个时间轴上的语音信号与噪声信号的平均功率之比。
(3)分段信噪比(SegSNR)
由于语音信号是一种缓慢变化的短时平稳信号,因而在不同时间段上的信噪比也应不一样。为了改善信噪比的问题,可以采用分段信噪比。
(4)对数似然比测度(LLR)
坂仓距离测度是通过语音信号的线性预测分析来实现的。ISD 基于两组线性预测参数 (分别从原纯净语音和处理过的语音的同步帧得到) 之间的差异。LLR 可以看成一种坂仓距离(Itakura Distance,IS),但 IS 距离需要考虑模型增益。而 LLR 不考虑模型增益引起的幅度位移,更重视整体谱包络的相似度。
(5)对数谱距离(LSD)
对数谱距离的定义
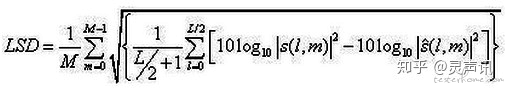
(6)可短时客观可懂(STOI)
0-1 范围,值越大,可懂度越高。
代码实现:
def get_stoi(ref_wav, deg_wav):
"""
计算语音的STOI值,范围0~1,值越大,可懂度越高.
注意:两个音频长度一致,且需要是单声道
:param ref_wav:
:param deg_wav:
:return:
"""
import soundfile as sf
from pystoi import stoi
clean, fs = sf.read(ref_wav)
denoised, fs = sf.read(deg_wav)
# 检查是否为单声道
import wave
with wave.open(ref_wav, 'rb') as reg_wav_obj:
reg_wav_channels = reg_wav_obj.getnchannels()
if reg_wav_channels > 1:
logger.error("音频不是单声道,声道数为:%d,音频: %s" % (reg_wav_channels, ref_wav))
return False
with wave.open(deg_wav, 'rb') as deg_wav_obj:
deg_wav_channels = deg_wav_obj.getnchannels()
if deg_wav_channels > 1:
logger.error("音频不是单声道,声道数为:%d,音频: %s" % (deg_wav_channels, deg_wav))
return False
# 检查两个音频文件长度,帧数相差不大于10
if abs(len(clean) - len(denoised)) > 10:
logger.error("ref_wav/deg_wav两个音频长度不一致: %d/%d" % (len(clean), len(denoised)))
return False
# Clean and den should have the same length, and be 1D
d = stoi(clean, denoised, fs, extended=False)
return d
(7)加权谱倾斜测度(WSS)
WSS 值越小说明扭曲越少,越小越好,范围

(8)感知客观语音质量评估(POLQA)
POLQA (感知客观语音质量评估),是一个技术升级,它能够覆盖最新的语音编码和网络传输技术,对于 3G,4G/LTE 和 VoIP 网络有了更高的准确度。POLQA 是 PESQ 的继承者(ITU-T P.862 建议书)。POLQA 避免了当前 P.862 型号的弱点,并且扩展到处理更高带宽的音频信号。进一步的改进针对具有许多延迟变化的称为信号和信号的时间的处理。与 P.862 类似,POLQA 支持普通电话频段(300-3400 Hz)的测量,但此外它还具有第二种操作模式,用于评估宽带和超宽带语音信号中的 HD-Voice(50-14000)赫兹)。POLQA 还针对由具有嘴和耳模拟器的人造头部在声学上记录的语音信号的评估。
ITU-T 的全系列参考目标语音质量测量系列始于 1997 年的 P.861(PSQM),2001 年被 P.862(PESQ)取代.P.862 后来补充了 P.862.1 的建议。(PESQ 得分到 MOS 量表的映射),P.862.2(宽带测量)和 P.862.3(应用指南)。自 2011 年以来 P.863(POLQA)生效。ITU-T 第 12 研究组于 2011 年 11 月同意了 P.863 的另外两个实施者指南。除了上面列出的完整参考方法外,ITU-T 的客观语音质量测量标准清单还包括 P.563(无参考算法)
POLQA,类似于 P.862 PESQ,是一种全参考(FR)算法,可对与原始信号相关的降级或处理过的语音信号进行评级。它将参考信号(讲话者侧)的每个样本与劣化信号(收听者侧)的每个相应样本进行比较。两个信号之间的感知差异被评为差异。感知心理声学模型基于类似的人类感知模型,如 MP3 或 AAC。基本上,在应用掩蔽函数之后,在频域(在临界频带中)分析信号。两个信号表示之间的未屏蔽差异将被计为失真。最后,语音文件中累积的失真被映射到 MOS 测试中通常的 1 到 5 质量等级。
POLQA 是全参考算法,并且在对应的参考和测试信号的摘录的时间对准之后逐个样本地分析语音信号。POLQA 可用于为网络提供端到端(E2E)质量评估,或表征各个网络组件。
POLQA 结果主要是模型平均意见得分(MOS),涵盖从 1(差)到 5(优秀)的范围。
2、音频处理常用功能
(1)子进程执行 cmd
下面的方法会调用此方法,所以多一个无关方法.
def subprocess_cmd(cmd, method_name):
"""
子进程执行cmd
:param cmd:
:param method_name:
:return:
"""
process = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
start_time = time.time()
while True:
retcode = process.poll()
if retcode is None:
time.sleep(1)
else:
out, err = process.communicate()
if retcode == 1:
logger.error("执行失败,输出:\n %s" % str(err, encoding='utf-8'))
elif retcode == 0:
end_time = time.time()
logger.success("%s执行结束,耗时: %d 秒, cmd: %s" % (method_name, int(end_time - start_time), cmd))
break
(2)视频提取音频
def get_aac_audio(input_file: str, output_file: str):
"""从视频文件中获取音频
:param input_file: 视频文件,如input.mp4
:param output_file: 音频文件,如output.aac
:return:
"""
if not os.path.exists(input_file):
logger.error("文件不存在,请检查文件: %s" % input_file)
if os.path.exists(output_file) and os.path.isfile(output_file):
os.remove(output_file)
cmd = "ffmpeg -i %s -vn -c:a copy %s" % (input_file, output_file)
subprocess_cmd(cmd, "get_audio")
return output_file
(3)降噪处理音频
def optimize_audio(input_file, output_file):
"""
对音频进行降噪处理,隔离可听见的声音。将低通滤波器与高通滤波器结合使用。
过滤掉200hz及以下的内容,然后过滤掉3000hz及以上的内容,可以很好地保持可用的语音音频。
:param input_file: 原始文件
:param output_file: 处理后文件
:return:
"""
if not os.path.exists(input_file):
logger.error("文件不存在,请检查文件: %s" % input_file)
if os.path.isfile(output_file) and os.path.exists(output_file):
os.remove(output_file)
cmd = 'ffmpeg -i %s -af "highpass=f=200, lowpass=f=3000" %s' % (input_file, output_file)
subprocess_cmd(cmd, "handle_audio")
return output_file
(4)各类音频格式转换
def conversions_format_audio(input_file: str, output_file: str):
"""
音频格式转换。
参考:https://linuxconfig.org/ffmpeg-audio-format-conversions
:param input_file:
:param output_file:
:return:
"""
to_mp3_cmd = "ffmpeg -i %s -acodec libmp3lame %s" % (input_file, output_file)
to_ogg_cmd = "ffmpeg -i %s -acodec libvorbis %s" % (input_file, output_file)
to_aac_cmd = "ffmpeg -i %s %s" % (input_file, output_file)
to_ac3_cmd = "ffmpeg -i %s -acodec ac3 %s" % (input_file, output_file)
to_wav_cmd = "ffmpeg -i %s %s" % (input_file, output_file)
cmd = ""
if os.path.exists(output_file) and os.path.isfile(output_file):
os.remove(output_file)
# wav ->
if input_file.endswith(".wav"):
if output_file.endswith(".mp3"):
cmd = to_mp3_cmd
elif output_file.endswith(".ogg"):
cmd = to_ogg_cmd
elif output_file.endswith(".aac"):
cmd = to_aac_cmd
elif output_file.endswith(".ac3"):
cmd = to_ac3_cmd
# ogg ->
elif input_file.endswith(".ogg"):
if output_file.endswith(".mp3"):
cmd = to_mp3_cmd
elif output_file.endswith(".wav"):
cmd = to_wav_cmd
elif output_file.endswith(".aac"):
cmd = to_aac_cmd
elif output_file.endswith(".ac3"):
cmd = to_ac3_cmd
# ac3 ->
elif input_file.endswith(".ac3"):
if output_file.endswith(".mp3"):
cmd = to_mp3_cmd
elif output_file.endswith(".wav"):
cmd = to_wav_cmd
elif output_file.endswith(".aac"):
cmd = to_aac_cmd
elif output_file.endswith(".ogg"):
cmd = to_ogg_cmd
# aac ->
elif input_file.endswith(".aac"):
if output_file.endswith(".mp3"):
cmd = to_mp3_cmd
elif output_file.endswith(".wav"):
cmd = to_wav_cmd
elif output_file.endswith(".ac3"):
cmd = to_ac3_cmd
elif output_file.endswith(".ogg"):
cmd = to_ogg_cmd
if cmd:
logger.info(cmd)
subprocess_cmd(cmd, "conversions_format_audio")
else:
logger.error("input_file文件格式不对: %s" % input_file)
(5)音频原始文件 pcm 转 wav
如果不理解下面的名次,看本文最后的名词解释.
def pcm2wav(pcm_file):
"""
音频原始文件转wav
:param pcm_file:
:return:
"""
import wave
with open(pcm_file, 'rb') as pcmfile:
pcmdata = pcmfile.read()
with wave.open(pcm_file + '.wav', 'wb') as wavfile:
# nchannels(声道数量)
# sampwidth(采样位数, 跟Bit Depth一样)
# framerate(采样率)
# nframes(帧数)
# comptype(压缩类型)
# compname(压缩名)
# wavfile.setparams((1, 2, 16000, 0, 'NONE', 'NONE'))
wavfile.setnchannels(1)
wavfile.setsampwidth(2)
wavfile.setframerate(16000)
wavfile.writeframes(pcmdata)
(6)立体声转单声道
def stereo2mono(input_file, output_file):
"""
立体声 转 单声道。
-ac 1 设置声道数为1
-ar 48000 设置采样率为48000Hz
参考:https://blog.csdn.net/yu540135101/article/details/101025249
:param input_file: 立体声原始音频
:param output_file: 采样率48000Hz的单声道
:return:
"""
cmd = "ffmpeg -i %s -ac 1 -ar 16000 -y %s" % (input_file, output_file)
subprocess_cmd(cmd, "stereo2mono")
return output_file
3、名词解释
采样频率 (Sample Rate):也称采样率, 是指录音设备在单位时间内对声音信号的采样数或样本数, 单位为 Hz(赫兹), 采样频率越高能表现的频率范围就越大。
一些常用音频采样率如下:
8kHz - 电话所用采样率
22.05kHz - 无线电广播所用采样率
44.1kHz - 音频 CD, 也常用于 MPEG-1 音频 (VCD, SVCD, MP3) 所用采样率
48kHz - miniDV、数字电视、DVD、DAT、电影和专业音频所用的数字声音所用采样率采样位数 (Bit Depth, Sample Format, Sample Size, Sample Width), 也称位深度, 是指采集卡在采集和播放声音文件时所使用数字声音信号的二进制位数, 或者说是每个采样样本所包含的位数, 通常有 8 bit、16 bit。
声道数 (Channel), 是指采集卡在采集时使用声道数, 分为单声道 (Mono) 和双声道/立体声 (Stereo)
比特率 (Bit Rate), 也称位率, 指每秒传送的比特 (bit) 数, 单位为 bps(Bit Per Second), 比特率越高, 传送数据速度越快. 声音中的比特率是指将模拟声音信号转换成数字声音信号后, 单位时间内的二进制数据量。
其计算公式为: 比特率 = 采样频率 * 采样位数 * 声道数

 收藏一波
收藏一波