测试基础 实时音视频质量评估方案
原文见:在路上的博客
全文参考:
1. 音视频测试建议(腾讯音视频实验室质量平台组)
2. Android 端音视频测试(网易云信)
3. 腾讯会议如何进行视频质量评估与优化?
4. 关于 UGC、PGC、OGC 三者详细区别
5. 音视频质量评估绿皮书
6. 语音质量评估
7. 语音增强及质量评估的论文
8. VIPKID 音视频质量评估与感知系统
恭喜自己,因为做该方案,完成了自己的第一次知名开源项目的 pull request。
1、背景
视频电话功能,涉及实时音视频的质量评估。
音视频传输流程如下:
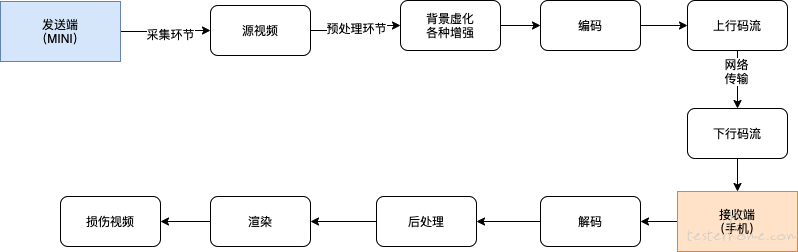
如图所示,影响音视频质量的因素有:
- 源视频的采集质量(硬件决定);
- 音视频 SDK 的服务质量(SDK 服务商决定);
- 网络情况;
实时传输视频质量专项有:(不同网络环境下)
- 性能、码率、抗性、时延、音画同步(由 SDK 服务保障并提供技术指标)
- 卡顿(流畅度):手机终端测试
- 视频质量(人工):通过开源算法进行评估
图片质量不能完全代表视频质量,这个一定注意。有疑问的,看下图(来源:腾讯会议)

2、音视频质量评估方案
2.1 视频评估方案
视频质量评估致力于评估视频的人眼感知质量,总的来说有两种评估方式:
- 主观质量评估:依赖人眼观看并打分,这种得到的分数比较精确,但是很耗时间,而且不方便大规模部署。
- 客观质量评估:主要是计算损伤视频的质量分数。评价一个算法的好坏就是衡量主观分数和客观分数的相关系数,一般来说系数越高越好。
客观质量评估算法大概分三类,主要取决于是否使用无损的源视频作为参考。
- 全参考:比如 PSNR 就是典型的全参考算法,通过与源视频进行各种层面比对,来衡量损伤视频的质量。
- 无参考:有的算法不使用源视频,只使用接收端的视频,来衡量它自己本身的质量。
- 部分参考: 比如从源视频中提取一个特征向量,特征向量随着损伤视频一块发送到用户端用来计算质量。视频会议这种场景要做全参考本来是不现实的,因为不可能把本地无损的源视频送到用户端或者其他地方计算质量,我们这次所做的工作就是把会议这种典型的实时场景转化成一个可以使用全参考算法离线优化的场景。
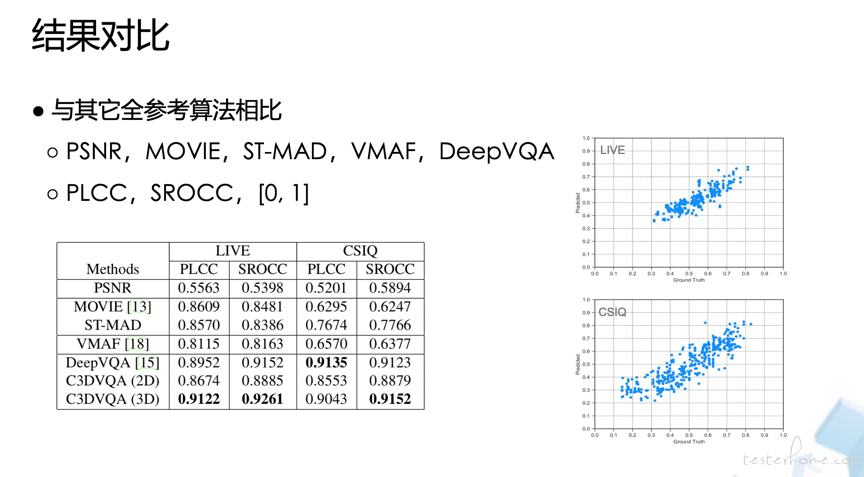
不同视频算法在视频数据库上的表现:
通过调研发现,视频质量评估开源算法,暂时以 netflix 的 VMAF 的为准,后期会增加腾讯开源的 DVQA 评估(DVQA 的模型以 PGC 视频的,不适合 UGC 的用户场景)。
DVQA 开源版当前适用场景:

(1)netflix VMAF
- 官方介绍 / 源码地址
- VMAF 官方安装指南/实际安装有很多坑,建议看 mac 安装指南
- 原理:Video Multimethod Assessment Fusion,简称 VMAF,通过结合多种基本质量指标来预测主观质量。其基本原理是,每个基本度量在源内容特征、工件类型和扭曲程度方面都可能有自己的优点和缺点。通过使用机器学习算法将基本度量 “融合” 成最终的度量标准ーー在我们的例子中是一个支持向量机回归子ーー它为每个基本度量标准赋予权重,最终的度量标准可以保留每个度量标准的所有优点,并提供一个更准确的最终得分。s
- 开发技术说明:VDK 内核中的特征提取 (包括初等度量计算) 是计算密集型的,为了提高效率,采用 c 语言编写。控制代码是用 Python 编写的,用于快速原型化。
- 参考的基本指标:
- 视觉信息逼真度 (VIF):VIF 是一种被广泛采用的图像质量度量方法,它的前提是图像质量与信息保真度损失的度量相辅相成。在其原始形式,VIF 分数是衡量为一个失去保真度结合四个尺度。在 VMAF 中,我们采用了一个修正版的 VIF,其中每个尺度的保真度损失是作为一个基本的度量。
- 详细损失度量 (DLM):DLM 是一种图像质量度量方法,它的基本原理是分别测量影响内容可见性的细节损失,以及分散观众注意力的冗余损失。最初的度量结合了 DLM 和加性损害测量 (AIM) ,以产生最终的得分。在 VMAF 中,我们只采用 DLM 作为一个基本的度量。特别注意特殊情况,如黑框,其中数值计算的原始公式打破。
- Motion:测量相邻帧之间时间差的简单方法。这是通过计算亮度分量的平均绝对像素差来实现的。
- 使用:
shell PYTHONPATH=python ./python/vmaf/script/run_vmaf.py \ yuv420p 576 324 \ python/test/resource/yuv/src01_hrc00_576x324.yuv \ python/test/resource/yuv/src01_hrc01_576x324.yuv \ --out-fmt json - 结果解析:
这将生成如下 JSON 输出:

- VMAF_score 得分是最终得分,得分范围 0(最差)to 1(最好)
- adm2, vif_scalex 得分范围 0 (最差) to 1 (最好)
- motion2 得分范围 0 (静止的) to 20 (高速运动的)
2.2 音频评估方案
音频质量评估算法较多,从稳定性和评估纬度考虑,选择 PESQ 和 STOI 进行音频评估。
音频质量评估相关介绍及代码见:https://testerhome.com/topics/25054
(1)PESQ
- git:https://github.com/vBaiCai/python-pesq
- 功能:通过输入原始文件和待评估文件,输出 PESQ 得分,得分范围在-0.5--4.5 之间,得分越高表示语音质量越好。
- 说明:PESQ 算法需要带噪的衰减信号和一个原始的参考信号。开始时将两个待比较的语音信号经过电平调整、输入滤波器滤波、时间对准和补偿、听觉变换之后, 分别提取两路信号的参数, 综合其时频特性, 得到 PESQ 分数, 最终将这个分数映射到主观平均意见分 (MOS)。PESQ 得分范围在-0.5--4.5 之间。得分越高表示语音质量越好。
(2)可短时客观可懂(STOI)
STOI:可短时客观可懂,是用来评估在时域上经过掩蔽或经过短时傅里叶变换且频域上加权的带噪语音的可懂性。计算 STOI 时,用时间对其的纯净与混合语音信号来计算每个音频通道 kk K ( =1, , ) 与 400ms 短时分段 mm M ( =1, , ) 的中间值 d km ( , ) 。首先,对纯净和带噪语音信号进行短时傅里叶变换,得到第 j 个频段第 n 个时间侦的短时能量谱 ( ) 2 X jn, 和 ( ) 2 Y jn, 。 将 j 个跨越 1/3 倍频带间隔的 ( ) 2 X jn, 和 ( ) 2 Y jn, 相加得到第 k 个音频通道的能量谱 ( ) 2 X kn, 和 ( ) 2 Y kn, 。带噪语音能量谱 ( ) 2 Y kn, 被限制为信号失真比不能低于−15dB。中间值 d km ( , ) 是 ( ) 2 X km, 和 第 k 通道 m 分段的带噪语音能量谱 ( ) ( ) 2 Y kn n N , 1, , = 的相关指数。STOI 评分 d 是带噪语音每个频带可懂性的平均值,表达式如下: ( ) , 1 , k m d d km KM = ∑ STOI 通过对纯净语音和待评价的语音进行比较从而得到评分,取值范围为 0-1。取值越高语音质量越好。
STOI 通过对纯净语音和待评价的语音进行比较从而得到评分,取值范围为 0-1。取值越高语音质量 越好。
git:https://github.com/mpariente/pystoi
2.3 流畅度评估
- (来源:腾讯)流畅度一般以卡顿率来反映,卡顿的信息主要包含卡顿次数与卡顿时间;直播场景业界通常的卡顿定义是帧渲染间隔大于 1s 则为卡顿发生;但通过主观实验,一般这个值达到 200ms,观众即可感受到卡顿;
- 卡顿率 = sum (>200ms 卡顿时间) / 通话时间;
- 流媒体场景下的卡顿定义会采用不同的方法。
- 流畅度评估原理(安卓):通过获取 gfxinfo 中的帧信息,统计帧耗时和卡顿率。
2.4 网络模拟工具
可通过模拟不同的网络环境,一方面验证 SDK 承诺的各项性能指标是否合格,另一方面验证弱网环境下的音视频质量。
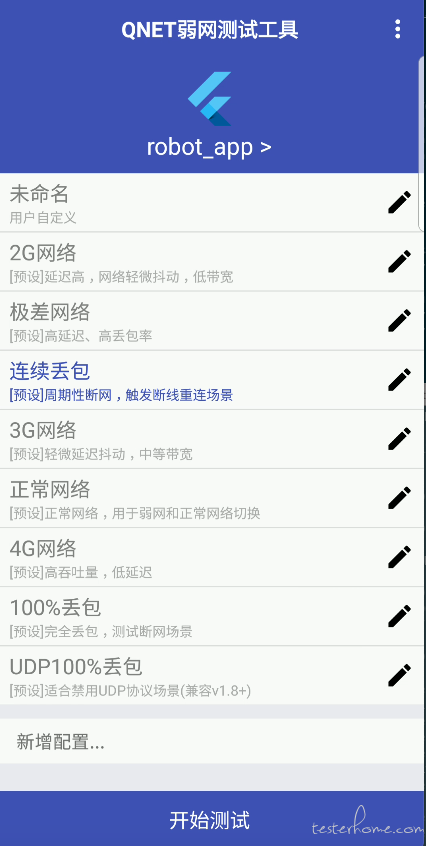
(1)QNET 弱网测试工具
推荐使用 QNET,使用成本极低,且体验很好。
只需要在设备上安装 APP,并用 QQ 登陆即可。弱网模拟环境稳定、安装简单。
(2)network emulator
弱网测试工具:network emulator,微软开源,可实现带宽、丢包、延时、抖动、综合网络等弱网参数的限制。
弱网测试常用参数:

(2)facebook ATC
安装及使用参考:https://testerhome.com/topics/15562
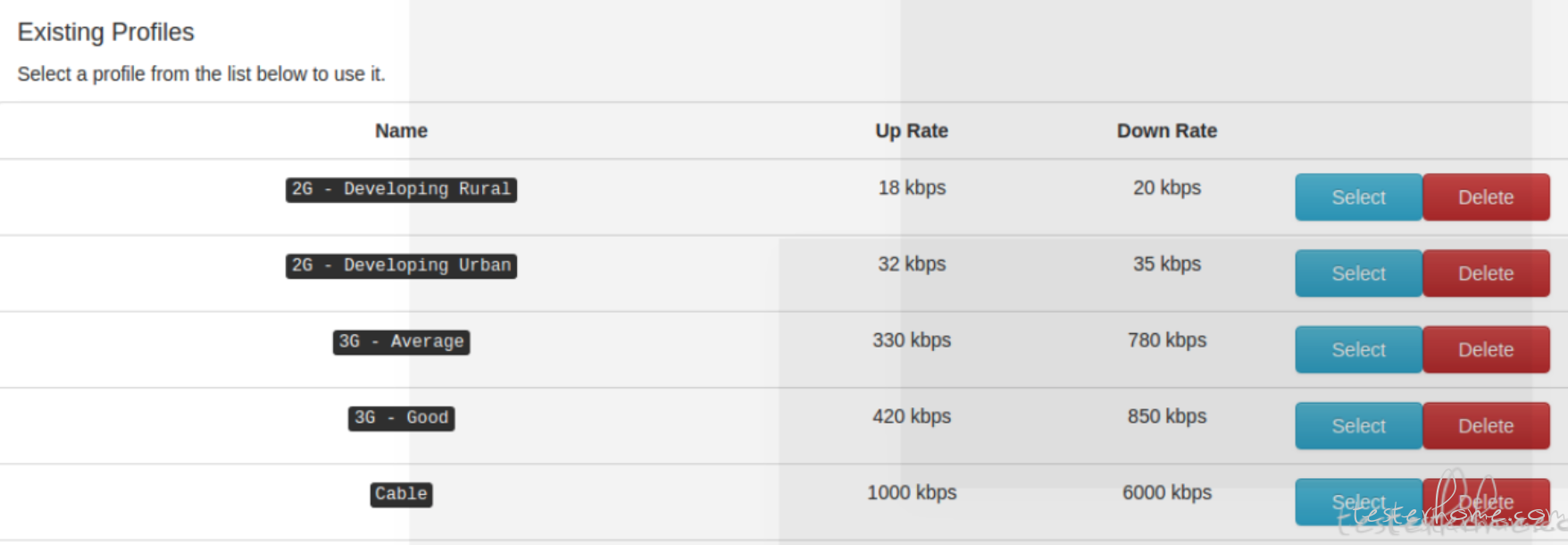
2.5 好用的测试框架
FR:@rikiesxiao (叉叉敌)
- scikit-image 这个主要是对视频,图片的一些算法, 比如 PSNR, SSIM 等
- QoSTestFramework 还有一个测试框架,这个也集成了 VMAF.
3、参考资料
UGC 质量评估:评估对象为短视频、直播、实时视频通话等。
3.1 SDK 性能指标
(1)音视频 SDK 性能指标
腾讯数据来源:https://cloud.tencent.com/document/product/454/9867
推流状态数据:
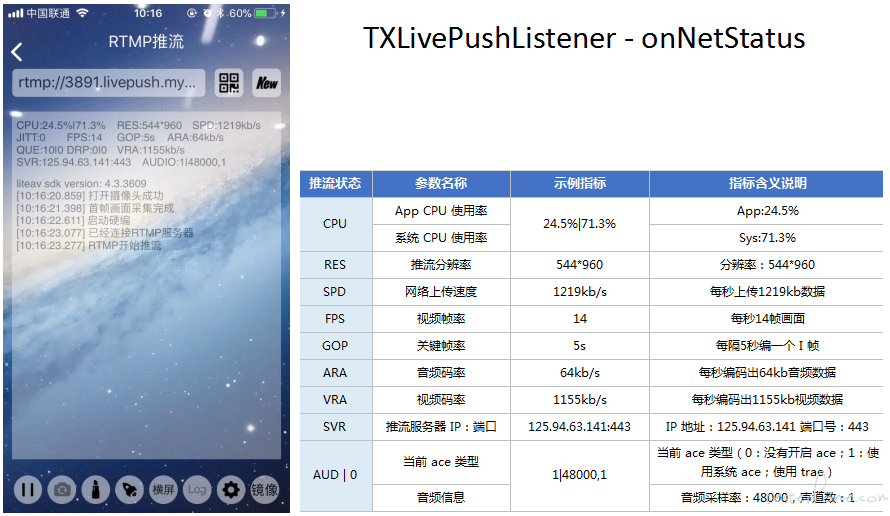
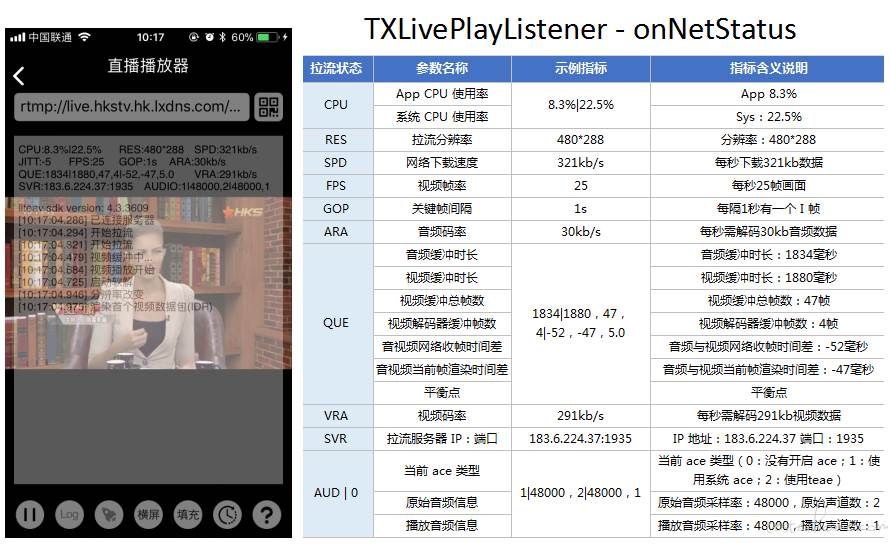
获取播放的状态数据:
3.2 视频质量标准及算法
视频质量客观评估就是量化一段视频通过视频传输/处理系统时画面质量变化(通常是下降)程度的方法。
(1)视频评估算法对比
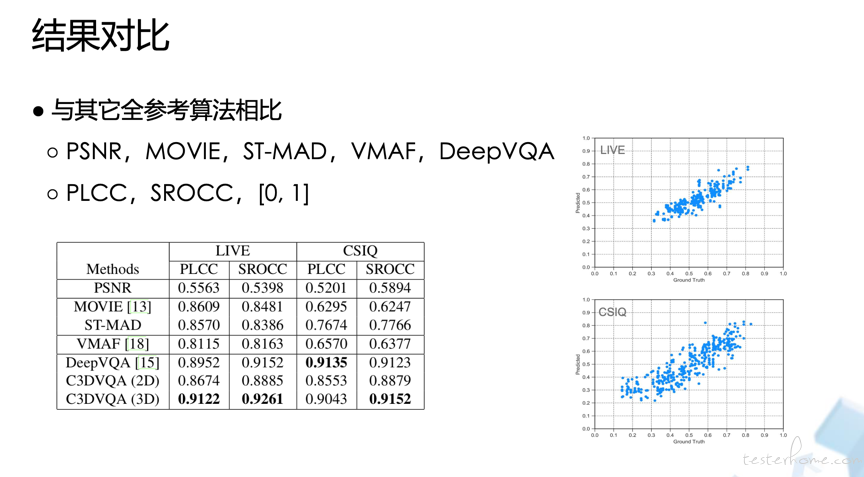
指标解析:
- PLCC:Pearson 线性相关系数,代表模型的线性相关性。
- SROCC:Spearman 秩序相关系数,用来衡量秩序的相关性的,代表模型的非线性相关性。 假设有两组序列 X 和 Y,其秩序为 R(X) 和 R(Y),则 SROCC(X, Y) = PLCC(R(X), R(Y))。
(2)腾讯会议开源的 DVQA
针对腾讯会议场景所开发的基于深度学习的实时视频全参考质量评估算法。
腾讯会议使用深度学习设计了一个新的网格,来自动学习视频质量的相关特征,然后在 PGC 数据集上训练得到一个通用的网格。
- 特点:
- 足够的准确度和区分度来衡量编解码器性能;
- PSNR、SSIM、MS-SSIM、VMAF,基于图像质量评估;
- 使用深度学习来自动学习质量相关特征;
- 使用迁移学习来拓展已有模型到新的场景;
- git 地址:https://github.com/Tencent/DVQA
- 腾讯会议 在线视频质量打分平台:来收集视频的主观数据: mos.medialab.qq.com
腾讯视频也开发了端到端自动的质量评测系统,这是整体的框架图。其实它的策略相对来说没那么复杂,就是在发送端播放源视频,经过可控的损伤网络之后,另一边是接收端,在接收端捕获会议呈现的画面,把这个画面拿出来再结合发送端的源视频去计算它的质量分数。前面提到的性能、码率这些绝对的指标都可以得到,抗性更多取决于什么样的网络情况下体验特别糟糕,时延、卡顿、音画同步、包括帧率都可以通过比对这两个视频得到结果。
(3)netflix VMAF
- 官方介绍
- git:https://github.com/Netflix/vmaf
- VMAF 安装指南、mac 安装指南
- 原理:Video Multimethod Assessment Fusion,简称 VMAF,通过结合多种基本质量指标来预测主观质量。其基本原理是,每个基本度量在源内容特征、工件类型和扭曲程度方面都可能有自己的优点和缺点。通过使用机器学习算法将基本度量 “融合” 成最终的度量标准ーー在我们的例子中是一个支持向量机回归子ーー它为每个基本度量标准赋予权重,最终的度量标准可以保留每个度量标准的所有优点,并提供一个更准确的最终得分。
- 开发技术说明:VDK 内核中的特征提取 (包括初等度量计算) 是计算密集型的,为了提高效率,采用 c 语言编写。控制代码是用 Python 编写的,用于快速原型化。
-
参考的基本指标:
- 视觉信息逼真度 (VIF):VIF 是一种被广泛采用的图像质量度量方法,它的前提是图像质量与信息保真度损失的度量相辅相成。在其原始形式,VIF 分数是衡量为一个失去保真度结合四个尺度。在 VMAF 中,我们采用了一个修正版的 VIF,其中每个尺度的保真度损失是作为一个基本的度量。
- 详细损失度量 (DLM):DLM 是一种图像质量度量方法,它的基本原理是分别测量影响内容可见性的细节损失,以及分散观众注意力的冗余损失。最初的度量结合了 DLM 和加性损害测量 (AIM) ,以产生最终的得分。在 VMAF 中,我们只采用 DLM 作为一个基本的度量。特别注意特殊情况,如黑框,其中数值计算的原始公式打破。
- Motion:测量相邻帧之间时间差的简单方法。这是通过计算亮度分量的平均绝对像素差来实现的。
- vmaf 基本用法
- 单模式运行:run_vmaf.py
- 命令格式
shell PYTHONPATH=python ./python/vmaf/script/run_vmaf.py format width height reference_path distorted_path [--out-fmt output_format] - 命令解析: format 可以是: (1)uv420p, yuv422p, yuv444p (8-Bit YUV) (2)yuv420p10le, yuv422p10le, yuv444p10le (10-Bit little-endian YUV) width height 是视频的宽高度,以像素为单位。
- 结果解析
这将生成如下 JSON 输出:

- 其中 VMAF_score 得分是最终得分,其他是 VMAF 的基本指标得分。
- adm2, vif_scalex 得分范围 0 (最差) to 1 (最好)
- motion2 得分范围 0 (静止的) to 20 (高速运动的)
批处理模式运行: run_vmaf_in_batch.py
命令行工具:ffmpeg2vmaf,提供了将压缩视频流作为输入的能力。
3.3 音频质量标准
PESQ 和 PQLQA 都是业界公认的语音音质评估算法;
(1)音频评估纬度
A. 绝对等级评分 (MOS)
<!--br {mso-data-placement:same-cell;}--> td {white-space:pre-wrap;}音频级别 MOS 值评价标准优 4.0~5.0 很好,听得清楚;延迟小,交流流畅良 3.5~4.0 稍差,听得清楚;延迟小,交流欠流畅,有点杂音中 3.0~3.5 还可以,听不太清;有一定延迟,可以交流差 1.5~3.0 勉强,听不太清;延迟较大,交流需要重复多遍劣 0~1.5 极差,听不懂;延迟大,交流不通畅
一般 MOS 应为 4 或者更高,这可以被认为是比较好的语音质量,若 MOS 低于 3.6,则表示大部分被测不太满意这个语音质量。
MOS 测试一般要求:
- 足够多样化的样本(即试听者和句子数量)以确保结果在统计上的显著;
- 控制每个试听者的实验环境和设备保持一致;
- 每个试听者遵循同样的评估标准。
B. 失真等级评分(Degradation Category Rating, DCR)
C. 相对等级评分(Comparative Category Rating, CCR)
(2)音频评估算法
A. python-pesq(PESQ)
- git:https://github.com/vBaiCai/python-pesq
- 功能:通过输入原始文件和待评估文件,输出 PESQ 得分,得分范围在-0.5--4.5 之间,得分越高表示语音质量越好。
- 说明:PESQ 算法需要带噪的衰减信号和一个原始的参考信号。开始时将两个待比较的语音信号经过电平调整、输入滤波器滤波、时间对准和补偿、听觉变换之后, 分别提取两路信号的参数, 综合其时频特性, 得到 PESQ 分数, 最终将这个分数映射到主观平均意见分 (MOS)。PESQ 得分范围在-0.5--4.5 之间。得分越高表示语音质量越好。
B. 分段信噪比(SegSNR)
由于语音信号是一种缓慢变化的短时平稳信号,因而在不同时间段上的信噪比也应不一样。为了改善信噪比的问题,可以采用分段信噪比。
C. 对数似然比测度(LLR)
坂仓距离测度是通过语音信号的线性预测分析来实现的。ISD 基于两组线性预测参数 (分别从原纯净语音和处理过的语音的同步帧得到) 之间的差异。LLR 可以看成一种坂仓距离(Itakura Distance,IS),但 IS 距离需要考虑模型增益。而 LLR 不考虑模型增益引起的幅度位移,更重视整体谱包络的相似度。
D. 对数谱距离(LSD)
E. 可短时客观可懂(STOI)
0-1 范围,值越大,可懂度越高。
F. 加权谱倾斜测度(WSS)
WSS 值越小说明扭曲越少,越小越好,范围
G. 感知客观语音质量评估(POLQA)
POLQA,是一种全参考(FR)算法,可对与原始信号相关的降级或处理过的语音信号进行评级。它将参考信号(讲话者侧)的每个样本与劣化信号(收听者侧)的每个相应样本进行比较。两个信号之间的感知差异被评为差异。
PQLQA 的音质评估涵盖了可懂度、卡顿等听感信息;因为是有参算法,所以不适合用于变声一类的场景评估;除关心音质的评价值外,音质平稳性也会对听感有较大影响。
4.5 音视频处理工具 FFmpeg
(1)统计码率
ffmpeg -i /Users/lizhen/Downloads/mask.mp4 -hide_banner
输出:

5、名词解释
(1)视频
- 帧率:帧率对视频质量的影响远远大于分辨率和 QP。
- 分辨率:就是帧大小每一帧就是一副图像。640*480 分辨率的视频,建议视频的码率设置在 700 以上,音频采样率 44100 就行了。一个音频编码率为 128Kbps,视频编码率为 800Kbps 的文件,其总编码率为 928Kbps,意思是经过编码后的数据每秒钟需要用 928K 比特来表示。
- QP:量化参数,反映了空间细节压缩情况。值越小,量化越精细,图像质量越高,产生的码流也越长。
- 性能:
- 码率:数据传输时单位时间传送的数据位数,一般我们用的单位是 kbps 即千位每秒。 通俗一点的理解就是取样率,单位时间内取样率越大,精度就越高,处理出来的文件就越接近原始文件。
- 抗性:
- 时延:是网络传输中的一个重要指标,测量了数据从一个端点到另外一个端点所需的时间。一般我们用毫秒作为其单位。通常我们也把延迟叫做延时,但是延时有时还会表示数据包发送端到接受端的往返时间。这个往返时间我们可以通过网络监控工具测量,测量数据包的发送时间点和接受到确认的时间点,两者之差就是延时。单向时间就是延迟。
- 抖动:由于数据包的大小,网络路由的路径选择等众多因素,我们无法保证数据包的延迟时间是一致的,数据包和数据包延迟的差异我们称为抖动。也就是说因为数据包的延时值忽大忽小的现象我们称为是抖动。
- 卡顿:
- 音画同步:
- YUV 视频格式(Android 中常用的 YUV420 格式):一般的视频采集芯片输出的码流一般都是 YUV 格式数据流,后续视频处理也是对 YUV 数据流进行编码和解析。
- YUV444:4 个像素里的数据有 4 个 Y、4 个 U、4 个 V,未丢弃任何数据。
- YUV422:4 个像素里的数据有 4 个 Y、2 个 U、2 个 V。采集方式为 奇数像素丢弃 V,偶数像素丢弃 U。
- YUV420:为横向、纵向同时丢弃数据的采样方式。
- 采样方式:偶数像素丢弃 UV,在此基础上,奇数行进一步丢弃 V,偶数行进一步丢弃 U。
- 播放 YUV:ffplay -video_size 1080x2220 mini_yuvj420p_1080_2220.yuv
- mp4 转 YUV:ffmpeg -i mp4_file yuv_file
- mp4 修改分辨率:ffmpeg -i clean_mp4 -vf scale=1080:1024 denoised_mp4 -hide_banner
- VMAF 比较两个视频: python run_vmaf.py yuv420p 1080 2220 demo.yuv demo.yuv --out-fmt json
(2)音频参数(参考资料)
- 采样频率 (Sample Rate):也称采样率, 是指录音设备在单位时间内对声音信号的采样数或样本数, 单位为 Hz(赫兹), 采样频率越高能表现的频率范围就越大。 一些常用音频采样率如下: 8kHz - 电话所用采样率 22.05kHz - 无线电广播所用采样率 44.1kHz - 音频 CD, 也常用于 MPEG-1 音频 (VCD, SVCD, MP3) 所用采样率 48kHz - miniDV、数字电视、DVD、DAT、电影和专业音频所用的数字声音所用采样率
- 采样位数 (Bit Depth, Sample Format, Sample Size, Sample Width), 也称位深度, 是指采集卡在采集和播放声音文件时所使用数字声音信号的二进制位数, 或者说是每个采样样本所包含的位数, 通常有 8 bit、16 bit。
- 声道数 (Channel), 是指采集卡在采集时使用声道数, 分为单声道 (Mono) 和双声道/立体声 (Stereo)
- 比特率 (Bit Rate), 也称位率, 指每秒传送的比特 (bit) 数, 单位为 bps(Bit Per Second), 比特率越高, 传送数据速度越快. 声音中的比特率是指将模拟声音信号转换成数字声音信号后, 单位时间内的二进制数据量。 其计算公式为: 比特率 = 采样频率 * 采样位数 * 声道数
