前言
从 2019 年开始,趋于整个行业的形式,一直在学习 AI 机器学习方面的知识,这期间买了很多书,也听了很多课。一开始学习的感觉很神奇,再到迷茫,几乎弃坑,最后到认清事实,中间花了一些时间来读书、看书和思考,我在这里分享 1 下自己粗浅的学习心得,是为了让更多的朋友从"白话故事"的角度理解机器学习,仅此而已。
此贴的目的,是让不懂机器学习的小白用户入个门而已。
论坛里面有很多帖子是关于 35 岁之后怎么办的话题,我今年也过了 35 了,AI 人工智能是整个互联网的大趋势,是挡不住的,要硬着头皮学下去才是生存之道。
如果内容表述过程中出现了理解上的偏差和错误,还请各位指正。
我学习机器学习的目的
其实一开始学习的目的非常简单,希望能学到互联网业内神奇的"黑科技"知识,在测试工作中所运用和实践,既学了知识,又能提高团队的工作效率,还能在组织内 show 一下技术肌肉,实在是一举三得。
随着逐渐深入学习和接触下来,越学习越感觉害怕,对于数学不是很擅长的我,也越来越吃力,最后到了近乎放弃的状态。
停了一段时间后,自己还是重新调整了目标方向,把自己的目标定小一些,可不可以这样:"如果不懂机器学习的人问你这是什么,给别人解释明白",看似初级的目标,就成了我的学习目的。
弄清楚几个基本概念
最近几年特别热门的概念:人工智能、机器学习、深度学习,到底他们啥区别。
人工智能:
目的是为了让机器有 “智力”,为人所用。不是一个技术方法,只是一个广泛的概念。
机器学习:
让机器有 “智力” 这件事,怎么落地呢?那就让机器自己去学习与思考。人先定义好一些算法、输入数据(样本)、人标记出来的特征数据,并用这些信息进行分析,得出结果后自己做出一些行为。
深度学习:
让机器有 “智力” 后,深层次的挖掘数据中的关系。
在三国时代中,武将如云,谁能称得上是真正的"良将"?
一万个读者中,就有一万个哈姆雷特,A 说,我觉得是:吕布。B 说,我觉得是:赵云。C 说,我觉得是:关羽......,总之很难得出一个正确的答案,那么我们就以这个问题,借助机器学习的知识来实践一下,到底谁是三国时代中最厉害的武将,如果你是三国时代的一方郡主,招揽什么样的武将帮你打天下?
张飞很不服气
张飞说,刚刚的读者都没有提到我,是因为我长得丑吗?我不服。

那么,我们来客观分析 1 下,武将得具备哪儿些条件,参考了游戏《三国志》中的主要数据:
- 指挥统率
领兵打仗的能力,下属听不听你的。团队管理能力,能不能让 1 个 P5 的小兵在你的队伍中发挥 P6 的水平?
- 智谋
就是智谋高低,是否聪明狡猾
- 武力
就是武功高低,是否身手了得
- 魅力
应该是颜值、人格等等这些信息,是不是名士
如果用这些维度去衡量一个武将的话,指挥统率能力、智谋、武力、魅力就是特征。拿张飞举例,张飞是一个武将,那么他就是一个数据样本;他的武力如果是 92,这个值就是特征值;张飞{指挥统率:77,智谋:80,武力:92,魅力:10}这一组数据就是一个武将的特征向量。
换句话说,如果我们得到了三国时期一批武将的数据样本,通过机器学习,这些数据样本可以叫做训练集,我们通过训练就可以得出了谁是三国时期最厉害的武将了。
如:张飞{指挥统率:77,智谋:80,武力:92,魅力:10}
吕布{指挥统率:87,智谋:88,武力:99,魅力:85}等等......
数据是机器学习的先决条件
挑选良将英才
如果你是三国时期割据一方的领主,那你肯定希望网络那个时期的所有英才,辅佐你成就大业。
有的同学会问了,以张飞为例,下面这组数据中,如何让机器学习的算法去理解,"良将英才"跟这些特征之间有什么关系呢?
张飞{指挥统率:77,智谋:80,武力:92,魅力:10}
那么,我们可以把张飞的特征值,我们假设他的值为 x,把 x 放入 1 个三维空间里,空间里会有 1 个点来代表 “张飞”,这就是特征向量。一个向量就是一个武将的各种特征数据集合。
如果张飞的特征值 x 是输入数据,那么这个武将是否是良将英才的结果就是输出了。我们需要在输入和输出之间建立一个计算武将"英才能力"程度的算法模型。
我们本来并不知道这个算法模型的样子,代码怎么写,不过我们可以通过收集 N 多个武将的数据来得到算法,这个过程叫做回归。
现在我们来多输入几位武将,然后把几位武将的点都模拟在坐标轴中:
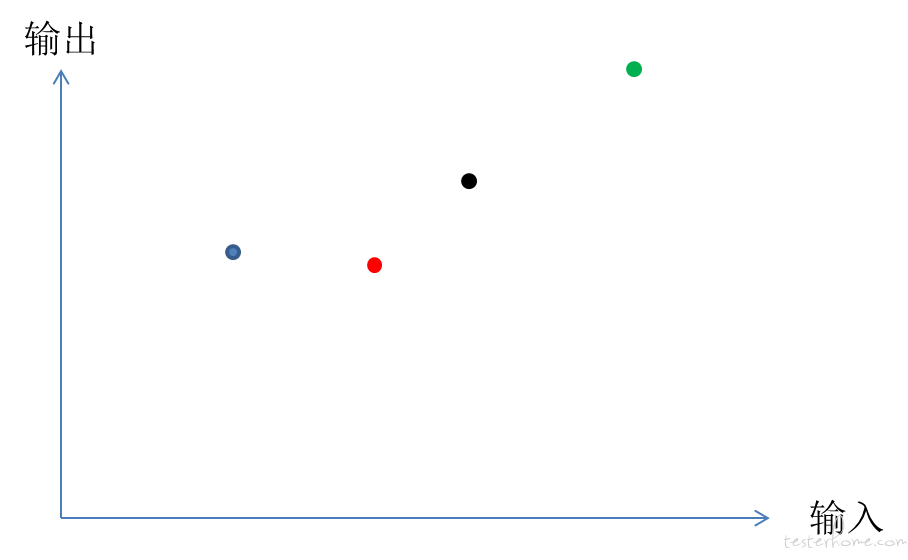
然后我们尝试用一条直线把各个数据点连起来,为了拟合这些数据点,直线要进行移动和旋转。
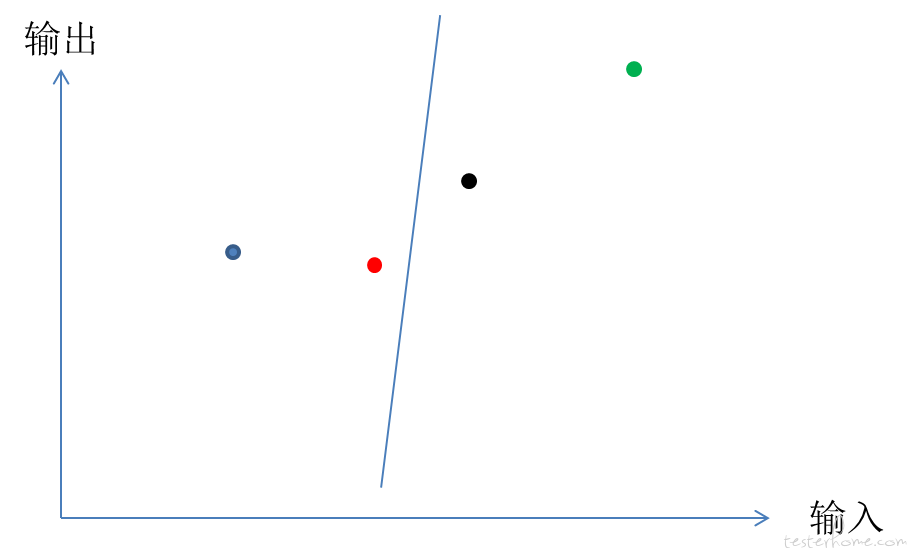
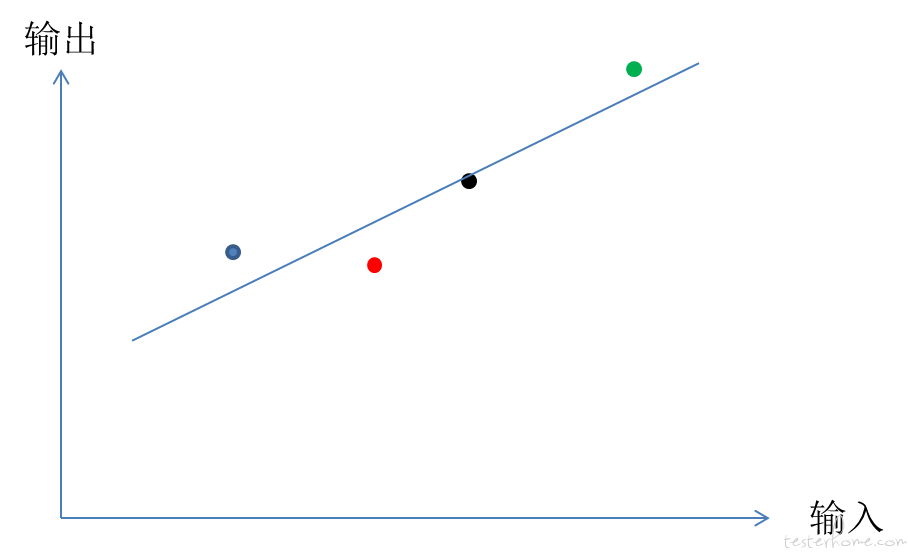
慢慢调整这条直线方程( y = f(x) )里的参数,这就是在做微调。尽量消除偏差,让直线与各个数据点精确吻合。
武将特征的权重
前面我们对武将的每一个特征进行了说明,分别是:指挥统率能力、智谋、武力、魅力,但是"良将"对于这 4 个特征属性的占比权重肯定各不相同,请看下面:
指挥统率能力 × W + 智谋 × W + 武力 × W + 魅力 × W = 良将值
权重(Weight)通常是 0 到 1 的一个小数。究竟哪儿个特征是重要的呢?其实我也不知道,我们需要不断的"调试参数",需要输入大量大量的武将数据,让自己的算法模型进行匹配。
那么问题来了,怎样才能让匹配结果的达到精准呢?
这时,要确定 1 个武将的"误差函数":列出理想的输出与实际输出,分别做减法后,得到偏差,再把所有的偏差进行平方和的计算。
为了计算的更精准,我们通常把数据按照数据结构特征进行分类,这称作:聚类法。比如:可以让同一类具有相似的武将值进行分类,也可以将具有相近重要性的武将分为一类。
为什么要做分类呢?因为只看原始数据,我们是看不出什么的,但是通过初步分类再看数据,会得到更多有用数据。
机器学习的目的就是对世界万物建立模型,以达到认识世界和改造世界的目的。而这个过程需要不断训练数据样本、不断加入新数据样本、交叉组合反复训练,最终利用算法模型来对世界万物进行相对准确的预测。
