性能常识 记一次服务端 IO 瓶颈问题定位
背景
近期发现测试平台,数据库读写速度较慢,基于此开始定位性能问题;
备注:因为资源有限,python 服务和数据库 mysql 放在了同一台服务器上
一、资源问题定位
1、先通过 uptime me 或 top 查看资源概况
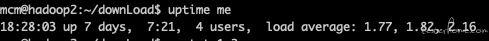
发现 CPU load 较低
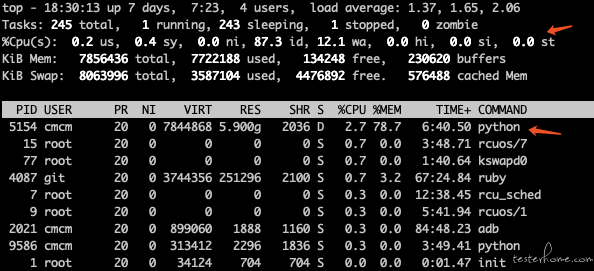
从上图看到,总体 CPU 空闲较多,iowait 为 12.1,继续查看多核的详细情况;
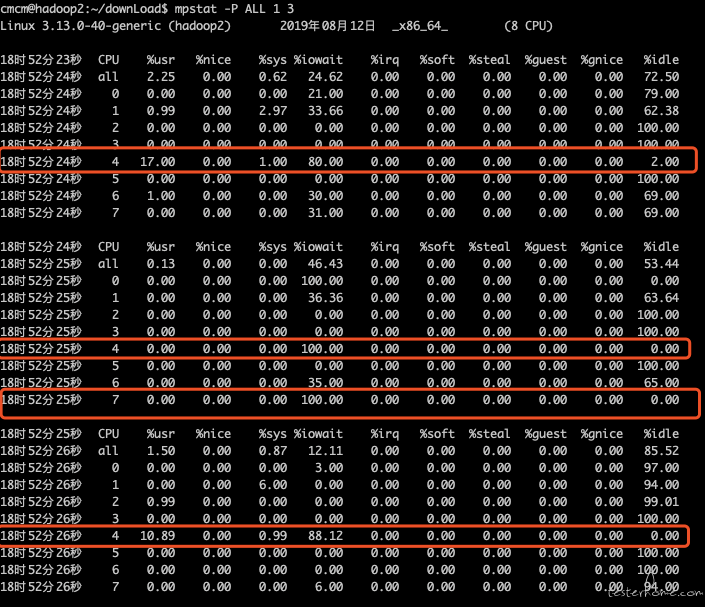
2、查看各核 CPU 情况 mpstat -P ALL 1 3
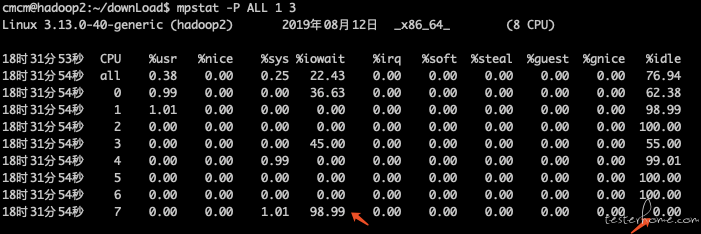
发现问题:编号 7 的 CPU,98.99 的 CPU 时间消耗在了 io 等待上,可能是 io 瓶颈。
接下来针对 iowait 过高的情况进行定位。
3、iowait 过高问题的查找及解决 linux
参考资料:https://www.cnblogs.com/happy-king/p/9234122.html
3.1 科普
(1)iostat 基础:%iowait 并不能反应磁盘瓶颈。
(2)iowait 实际测量的是 cpu 时间:%iowait = (cpu idle time)/(all cpu time)
说明:高速 cpu 会造成很高的 iowait 值,但这并不代表磁盘是系统的瓶颈。唯一能说明磁盘是系统瓶颈的方法,就是很高的 read/write 时间,一般来说超过 20ms,就代表了不太正常的磁盘性能。为什么是 20ms 呢?一般来说,一次读写就是一次寻到 + 一次旋转延迟 + 数据传输的时间。由于,现代硬盘数据传输就是几微秒或者几十微秒的事情,远远小于寻到时间 2~20ms 和旋转延迟 4~8ms,所以只计算这两个时间就差不多了,也就是 15~20ms。只要大于 20ms,就必须考虑是否交给磁盘读写的次数太多,导致磁盘性能降低了。
(3)iostat 分析
在 Linux 下,可以通过 iostat 命令还查看磁盘性能。其中的 svctm 一项,反应了磁盘的负载情况,如果该项大于 15ms,并且 util% 接近 100%,那就说明,磁盘现在是整个系统性能的瓶颈了。
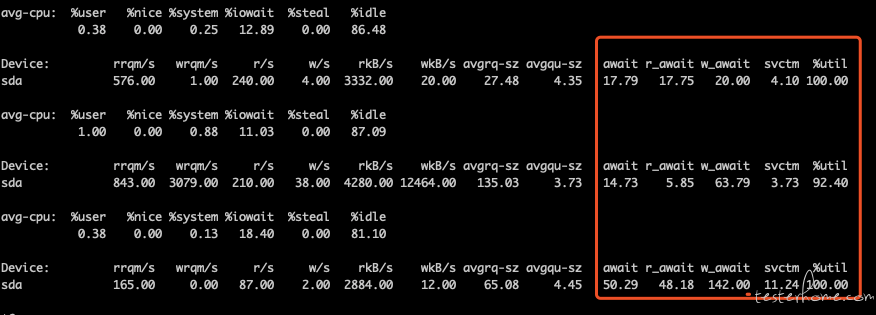
- rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
- wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
- r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
- w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
- rsec/s: 每秒读扇区数。即 delta(rsect)/s
- wsec/s: 每秒写扇区数。即 delta(wsect)/s
- rkB/s: 每秒读 K 字节数。是 rsect/s 的一半,因为每扇区大小为 512 字节。(需要计算)
- wkB/s: 每秒写 K 字节数。是 wsect/s 的一半。(需要计算)
- avgrq-sz: 平均每次设备 I/O 操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
- avgqu-sz: 平均 I/O 队列长度。即 delta(aveq)/s/1000 (因为 aveq 的单位为毫秒)。
- await: 平均每次设备 I/O 操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
- svctm: 平均每次设备 I/O 操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
- %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为 use 的单位为毫秒) 如果 %util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈。
** 结论:idle 小于 70% IO 压力就较大了,一般读取速度有较多的 wait。**
同时可以结合 vmstat 查看查看 b 参数 (等待资源的进程数) 和 wa 参数 (IO 等待所占用的 CPU 时间的百分比,高过 30% 时 IO 压力高)

await 的参数也要多和 svctm 来参考。差的过高就一定有 IO 的问题
二、iowait 过高问题定位及解决
1、确认是否是 I/O 问题导致系统缓慢
确认是否是 I/O 导致的系统缓慢我们可以使用多个命令,但是,最简单的是 unix 的命令 top,或 mpstat 查看各核情况
2、查看哪块磁盘正在被写入或读取
上边的 top 命令从一个整体上说明了 I/O wait,但是并没有说明是哪块磁盘影响的,想知道是哪块磁盘引发的问题,我们用到了另外一个命令 iostat 命令

上边的例子中,iostat 会每 2 秒更新一次,一共打印 5 次信息, -x 的选项是打印出扩展信息
第一个 iostat 报告会打印出系统最后一次启动后的统计信息,这也就是说,在多数情况下,第一个打印出来的信息应该被忽略,剩下的报告,都是基于上一次间隔的时间。举例子来说,这个命令会打印 5 次,第二次的报告是从第一次报告出来一个后的统计信息,第三次是基于第二次 ,依次类推
在上面的例子中,sda 的%utilized 是 91%~100%,这个很好的说明了有进程正在写入到 sda 磁盘中。
除了%utilized 外,我们可以得到更丰富的资源从 iostat,例如每毫秒读写请求(rrqm/s & wrqm/s)),每秒读写的((r/s & w/s),当然还有更多。在上边的例子中,我们的项目看起来正在读写非常多的信息。这个对我们查找相应的进程非常有用
3、查找引起高 I/O wait 对应的进程 iotop

4、查找哪个文件引起的 I/O wait
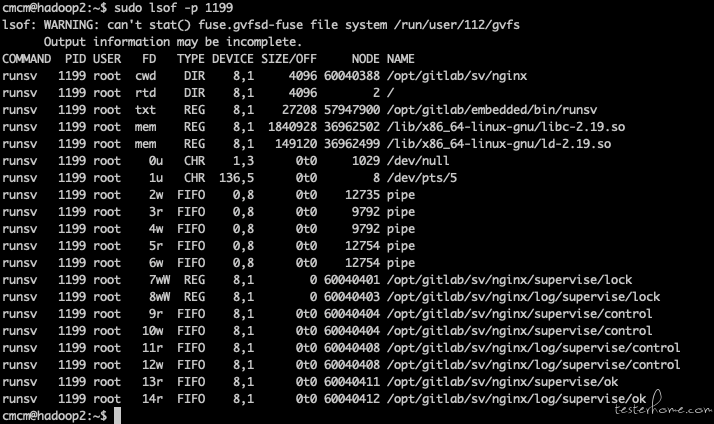
lsof 命令可以展示一个进程打开的所有文件,或者打开一个文件的所有进程。从这个列表中,我们可以找到具体是什么文件被写入,根据文件的大小和/proc 中 io 文件的具体数据
我们可以使用-p 的方式来减少输出,pid 是具体的进程
5、df -h 路径 查看服务器那块磁盘的根目录

最终,找到对应的文件,以及读写该文件对应的进程进行相应的处理就可以了
