Python 求指教!! 爬取天眼查数据的时候,脚本运行一段时间,就会被天眼查的反爬取搞出来。怎么能躲过这个检测
爬虫脚本执行一段时间以后,后续就会报错。
手动访问天眼查页面,发现页面提示确认是否是机器人。请大神指导怎么能躲过反爬取检测。
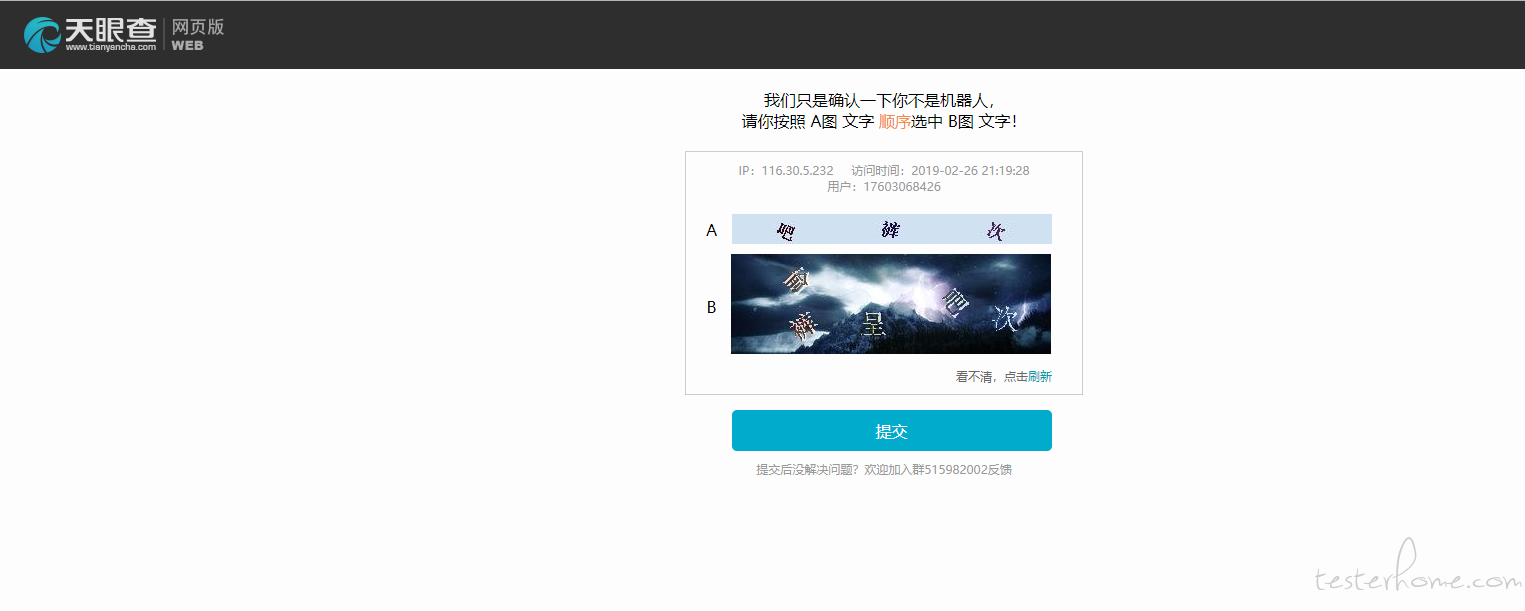
问题:
目前不太清楚天眼查是根据 IP,还是根据 cookie 来做的反爬取限制。
尝试过的操作:
1、延长每次请求的时间,设置为 3s 中爬取一次,结果中途也断了。
2、将请求的时间设置为随机时间在 0~5s 之内,结果也中途断了。
-----------------------------------------分割线--------2019.02.08 更新 ---------------------【代理池报错问题】-------------------------------------
r = s.get(city_url, headers=my_heads, proxies=params_file.proxies)
增加了 IP 地址池,IP 地址数据如下(购买的 IP 数据):
proxies = {
"https":"https://112.87.71.162:9999",
"https":"https://125.123.139.163:9999",
"https":"https://116.209.55.229:9999",
"https":"https://104.248.99.101:3128",
"https":"https://116.209.52.240:9999",
"https":"https://116.192.171.51:31742",
"https":"https://113.121.146.70:9999",
"https": "https://112.85.129.166:9999",
"https": "https://1.10.188.100:59164",
}
结果页面有报错:接口返回值为 403
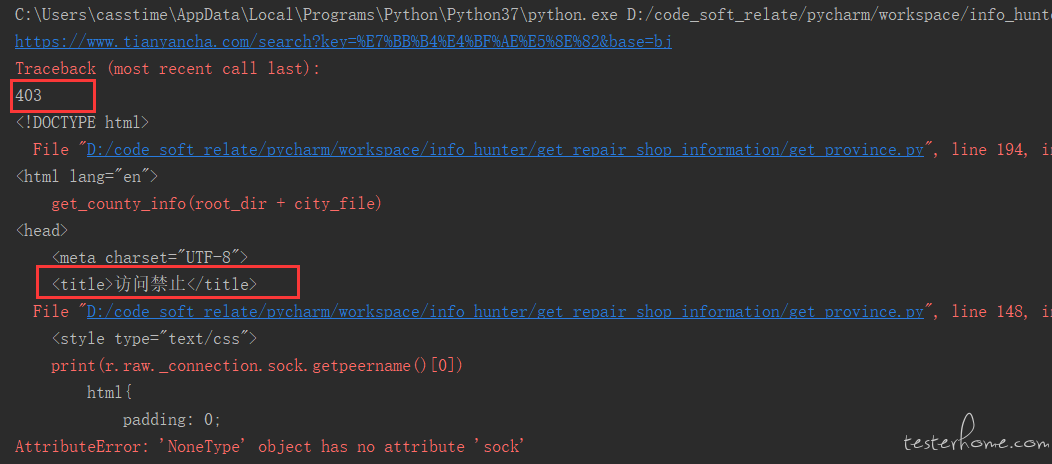
目前陷入了停滞状态,我尝试过去掉地址池,页面访问正常
所以有点尴尬,去掉地址池,爬一段时间,就要被封。用了地址池,程序跑不起来
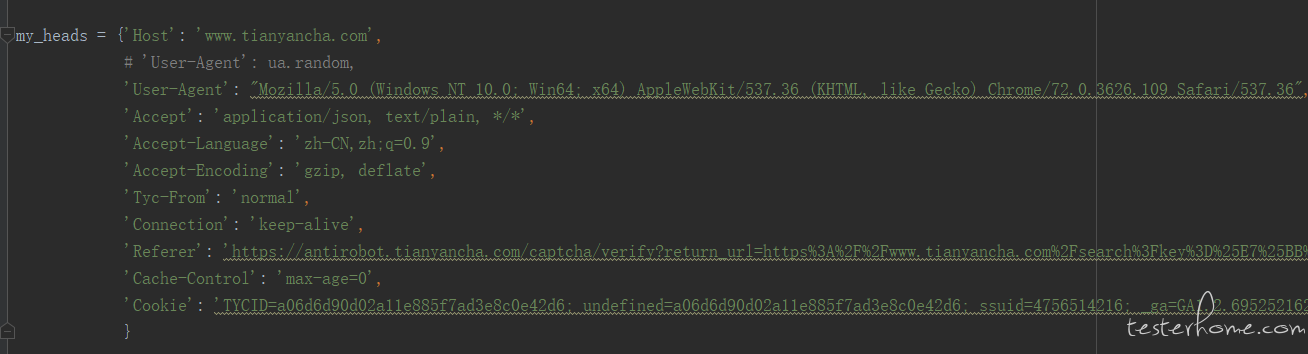
hreader 信息:
-----------------------------------------分割线--------2019.03.04 更新 --------------【代理 IP 以后,依然被封】--------------------------------------------
1、解决上面的代理池报错问题
使用以下命令获取当前运行请求的 IP 信息,发现一直是一个固定 IP 在运行,所以会被封掉。
print(r.raw._connection.sock.getpeername()[0])
修改方案:
每次 requests 请求前初始化一个 proxy
# 设置proxy,每次从ip_pool里面随机取ip
IP = ip_pool[random.randint(0, len(ip_pool)-1)]
print(IP)
proxies = {"https": IP, }
# 调用proxy
r = s.get(city_url, headers=my_heads, proxies=proxies, stream=True, timeout=10)
2、 解决 IP 代理可用性不高的问题。
由于免费的 IP 速度都比较慢,并且需要自己手动去爬,可用性贼低。所以最终还是买了收费版的 IP。
从使用体验来看,芝麻代理<西瓜代理<蘑菇代理。但是以上的 IP 可用性都应该不到 90% 吧(个人感觉),所以也会出现爬一段时间以后,由于连接有问题,导致程序暂定。
所以中间应该加一段异常处理和重试,另外不可用的 IP 需要从 IP 池剔除。
#异常处理:
while True:
# time.sleep(1)
# 设置proxy
IP = ip_pool[random.randint(0, len(ip_pool)-1)]
print(IP)
proxies = {"https": IP, }
# 访问
try:
r = s.get(city_url, headers=my_heads, proxies=proxies, stream=True, timeout=10)
# r = s.get(city_url, headers = my_heads, proxies = proxies, timeout = 10)
print('r.status_code', r.status_code)
# 具体爬虫部分太长,pass
break
except Exception as e:
# 当前运行失败,说明IP出了问题;1、删除失效IP。 2、判断IP池的大小,如果小于20,自动添加IP
ip_pool.remove(IP)
if len(ip_pool)<20:
# get_https_ip.get_IP() 封装了代理网站获取IP的API
new_ip_pool = get_https_ip.get_IP()
for data in new_ip_pool:
print('添加一次',data)
ip_pool.append(data)
3、新的问题。
使用 IP 代理之后,发现爬一段时间,账号依然会被封。不知道什么原因?
是因为一直使用一个 cookie 吗?这么搞的话,是不是得使用多个账号交替去爬?