楼主没答出来,社区高手试试?我觉得能答出来的人不超过 1%
题目:给定一个不确定的 json 对象,求 json 子节点的最大深度,如:
编程语言不限,不可写伪代码
{
"item":{
"data": {
"text": "123",
},
"children": [{
"data": {
"text": "234"
},
"children": []
}, {
"data": {
"text": "345"
},
"children": [{
"data": {
"text": "456"
},
"children": []
}, {
"data": {
"text": "plid"
},
"children": [{
"data": {
"text": "567"
},
"children": [....]
}, {
"data": {
"text": "678"
},
"children": [...]
}
]
}, {
// 不确定长度的Children节点
}
}
其实是个递归算法,json 本质是一个 tree 节奏的数据,先把 json 转成标准的各个语言的结构体,比如 python 的 dict 或者 java 的 hashmap。剩下的就是递归判断 children 的类型并计数深度。我碰巧之前写过类似的算法,不过 scala 的代码。。。
不得不说这个算法其实是测试工程里用的非常多的场景。用递归解决深层次数据的分析问题,在很多工具里都有一些应用的。
appcrawler 里也有好几段是关于这个算法的使用的,比如从 xpath 匹配的节点中反向生成 xpath 定位表达式,把 html 网页的 page source 转成 appium 兼容的 xml 格式,对数据结构做扁平化好进行数据对比。
def getAttributesFromNode(node: Node): ListBuffer[Map[String, String]] ={
val attributesList = ListBuffer[Map[String, String]]()
//递归获取路径,生成可定位的xpath表达式
def getParent(node: Node): Unit = {
if (node.hasAttributes) {
val attributes = node.getAttributes
var attributeMap = Map[String, String]()
0 until attributes.getLength foreach (i => {
val kv = attributes.item(i).asInstanceOf[Attr]
attributeMap ++= Map(kv.getName -> kv.getValue)
})
attributeMap ++= Map("name()" -> node.getNodeName)
attributeMap ++= Map("innerText" -> node.getTextContent.trim)
attributesList += attributeMap
}
if (node.getParentNode != null) {
getParent(node.getParentNode)
}
}
getParent(node)
//返回一个从root到leaf的属性列表
return attributesList.reverse
}
不过这次我用昨天霍格沃兹测试学院的 Linux 三剑客公开课的技术给你一个简单的解法
depth(){
echo "$1" \
sed 's#"[^"]*"##g' \
| grep -oE '{|}' \
| awk '/{/{a+=1}/}/{a-=1}{if(max<a) max=a}{print max,a}END{print "max depth="max}'
}
# 结果貌似是6
depth '
{
"item":{
"data": {
"text": "123",
},
"children": [{
"data": {
"text": "234"
},
"children": []
}, {
"data": {
"text": "345"
},
"children": [{
"data": {
"text": "456"
},
"children": []
}, {
"data": {
"text": "plid"
},
"children": [{
"data": {
"text": "567"
},
"children": [....]
}, {
"data": {
"text": "678"
},
"children": [...]
}
]
}, {
// 不确定长度的Children节点
}
}
'
# testerhome的json接口,貌似是4
depth "$(curl https://testerhome.com/api/v3/topics.json 2>/dev/null)"
# taobao的某个接口,结果为2
depth "$(curl http://ip.taobao.com/service/getIpInfo.php?ip=63.223.108.42 2>/dev/null )"
格式调整一下,题目不会,打扰了
感觉用栈和一个普通的计数就可以解决吧。
遍历树?
可以转成 string,然后比较{}出现的次数吧
题目还有更多细节需要沟通才清楚,我这里假定 list 类型不算一个深度,如果 list 也算的话就在切分一次
class Solution(object):
def max_deep(self, json_object):
if len(json_object) == 0:
return 0
list_json_object = str(json_object).split('{')
max_count = 0
init_count = 0
for json_str in list_json_object:
if '}' in json_str:
init_count -= json_str.count('}')
else:
init_count += 1
if init_count > max_count:
max_count = init_count
return max_count
看到{ +1
} -1
保留最大数,收工。
社区高手很多,我觉得像我这样答不出来的不超过 1%。
都能过腾讯的面试筛选却答不上这道题,不太相信。
空的 [] 算不算 json 子节点?
我看到第二级子节点会有多个 data 节点,多个 data 节点里面会有多个并列的不确定长度和深度的 Children 节点,请问只统计 “}” 是否准确?
计数器 + 递归 + 迭代器
写了个,感觉应该能满足
#-*- coding: utf-8 -*-
# @Time : 2019/1/25 12:27
# @File : jsondemo.py
# @Author : 守望@天空~
from collections import OrderedDict
import json
jsonstr = """
{"item":{"data":{"text":"123"},"children":[{"data":{"text":"234"},"children":[]},{"data":{"text":"345"},"children":[{"data":{"text":"456"},"children":[]},{"data":{"text":"plid"},"children":[{"data":{"text":"567"},"children":[]},{"data":{"text":"678"},"children":[]}]}]}]}}
"""
def dig_path(jsonstr,prepath=[],paths=[]):
if not prepath:
prepath=[]
t=jsonstr
if isinstance(t,(dict,OrderedDict)):
if t:
for key,value in t.items():
prepath_tmp=prepath[:]
prepath_tmp.append(key)
dig_path(value,prepath_tmp[:],paths)
else:
paths.append(prepath)
elif isinstance(t,list):
if t:
for index,value in enumerate(t):
prepath_tmp=prepath[:]
prepath_tmp.append(index)
dig_path(value,prepath_tmp[:],paths)
else:
paths.append(prepath)
else:
paths.append(prepath)
if __name__=="__main__":
paths = []
ttt = json.loads(jsonstr, object_pairs_hook=OrderedDict)
dig_path(ttt,paths=paths)
print("deep","\t","path")
for i in paths:
print(len(i),"\t",".".join([str(t) for t in i ]))
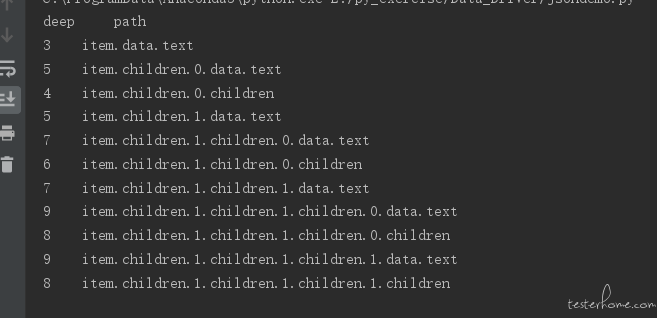
如果认为 list 和 dict 就算 1 级,那么其他类型就是最后一级了?
class Test:
def test(self, par, t):
if isinstance(par, dict):
t += 1
for i in par:
self.test(par[i], t)
if isinstance(par, list):
t += 1
for i in par:
self.test(i, t)
if not isinstance(par, (dict, list)):
print(t)
if __name__ == '__main__':
s = {"item":{"data":{"text":"123"},"children":[{"data":{"text":"234"},"children":[]},{"data":{"text":"345"},"children":[{"data":{"text":"456"},"children":[]},{"data":{"text":"plid"},"children":[{"data":{"text":"567"},"children":[]},{"data":{"text":"678"},"children":[]}]}]}]}}
Test().test(s, 0)
比较笨的方法是用递归
其实是个递归算法,json 本质是一个 tree 节奏的数据,先把 json 转成标准的各个语言的结构体,比如 python 的 dict 或者 java 的 hashmap。剩下的就是递归判断 children 的类型并计数深度。我碰巧之前写过类似的算法,不过 scala 的代码。。。
不得不说这个算法其实是测试工程里用的非常多的场景。用递归解决深层次数据的分析问题,在很多工具里都有一些应用的。
appcrawler 里也有好几段是关于这个算法的使用的,比如从 xpath 匹配的节点中反向生成 xpath 定位表达式,把 html 网页的 page source 转成 appium 兼容的 xml 格式,对数据结构做扁平化好进行数据对比。
def getAttributesFromNode(node: Node): ListBuffer[Map[String, String]] ={
val attributesList = ListBuffer[Map[String, String]]()
//递归获取路径,生成可定位的xpath表达式
def getParent(node: Node): Unit = {
if (node.hasAttributes) {
val attributes = node.getAttributes
var attributeMap = Map[String, String]()
0 until attributes.getLength foreach (i => {
val kv = attributes.item(i).asInstanceOf[Attr]
attributeMap ++= Map(kv.getName -> kv.getValue)
})
attributeMap ++= Map("name()" -> node.getNodeName)
attributeMap ++= Map("innerText" -> node.getTextContent.trim)
attributesList += attributeMap
}
if (node.getParentNode != null) {
getParent(node.getParentNode)
}
}
getParent(node)
//返回一个从root到leaf的属性列表
return attributesList.reverse
}
不过这次我用昨天霍格沃兹测试学院的 Linux 三剑客公开课的技术给你一个简单的解法
depth(){
echo "$1" \
sed 's#"[^"]*"##g' \
| grep -oE '{|}' \
| awk '/{/{a+=1}/}/{a-=1}{if(max<a) max=a}{print max,a}END{print "max depth="max}'
}
# 结果貌似是6
depth '
{
"item":{
"data": {
"text": "123",
},
"children": [{
"data": {
"text": "234"
},
"children": []
}, {
"data": {
"text": "345"
},
"children": [{
"data": {
"text": "456"
},
"children": []
}, {
"data": {
"text": "plid"
},
"children": [{
"data": {
"text": "567"
},
"children": [....]
}, {
"data": {
"text": "678"
},
"children": [...]
}
]
}, {
// 不确定长度的Children节点
}
}
'
# testerhome的json接口,貌似是4
depth "$(curl https://testerhome.com/api/v3/topics.json 2>/dev/null)"
# taobao的某个接口,结果为2
depth "$(curl http://ip.taobao.com/service/getIpInfo.php?ip=63.223.108.42 2>/dev/null )"
我只会递归实现…之前写过从 json 中获取给定 key 值的列的表递归方法,实现方式跟这个差不多,就是递归,像剥洋葱。
现场手写肯定写不出来真正能 work 的
设 maxnumber=0,number=0,然后把 json 里每个字符一个一个地读,读到 “{” 则 number+1,读到 “}” 则 number-1,读到其他则 number+0,每次 number+1 后就比较 number 和 maxnumber 直接的大小,如果 number>maxnumber 则 maxnumber=number,最后得出的 maxnumber 就是你要的结果
递归
想到了栈,用编译原理那套
普通的通过遍历的解法
public int testJson(JSONObject jo) {
int deepLevel = 0;
if (jo == null) {
return deepLevel;
}
Iterator it = jo.keys();
int[] levels = new int[jo.keySet().size()];
int index = 0;
while (it.hasNext()) {
int subLevel = 0;
String key = it.next();
Object v = jo.get(key);
if (v instanceof JSONObject) {
subLevel = 1+testJson((JSONObject) v);
} else if (v instanceof JSONArray) {
JSONArray array = (JSONArray) v;
if(array.length()==0){
return 1;
}
int[] subLevels = new int[array.length()];
int index2 = 0;
Iterator it2 = array.iterator();
while (it2.hasNext()) {
subLevels[index2++] = 1 + testJson((JSONObject) it2.next());
}
Arrays.sort(subLevels);
subLevel += subLevels[0];
} else {
subLevel += 1;
}
levels[index] = subLevel;
}
Arrays.sort(levels);
return levels[levels.length-1];
}
上面的有个手误
public int testJson(JSONObject jo) {
int deepLevel = 0;
if (jo == null) {
return deepLevel;
}
Iterator it = jo.keys();
int[] levels = new int[jo.keySet().size()];
int index = 0;
while (it.hasNext()) {
int subLevel = 0;
String key = it.next();
Object v = jo.get(key);
if (v instanceof JSONObject) {
subLevel = 1+testJson((JSONObject) v);
} else if (v instanceof JSONArray) {
JSONArray array = (JSONArray) v;
if(array.length()==0){
return 1;
}
int[] subLevels = new int[array.length()];
int index2 = 0;
Iterator it2 = array.iterator();
while (it2.hasNext()) {
subLevels[index2++] = 1 + testJson((JSONObject) it2.next());
}
Arrays.sort(subLevels);
subLevel += subLevels[subLevels.length-1];
} else {
subLevel += 1;
}
levels[index] = subLevel;
}
Arrays.sort(levels);
return levels[levels.length-1];
}
这也就是 leetcode easy 的水平,1% 太夸张了
发现社区嘴炮比较多,递归都不知道用,就直接说简单的(确实简单)
我用递归实现的:
···python
def calDeep(deep, jsonVar):
if (isinstance(jsonVar,tuple)):
jsonVar = jsonVar[1]
if (isinstance(jsonVar,dict)):
return max(map(lambda x: calDeep(deep + 1, x), jsonVar.items()))
if (isinstance(jsonVar,list)):
return max(map(lambda x: calDeep(deep,x),jsonVar))
else:
return deep
if name == "main":
print(calDeep(0, json.loads(jsonVar)))
题目应该很清楚,看这个 json 数据,最大子一个节点深度为 3, 并不是统计 children 总数额,那来那么多?
static int maxDeep;
public static int getDeep(JSONObject jsonObject,int deepLength) {
if (jsonObject == null){
return maxDeep = 0;
}else {
for (Map.Entry entry : jsonObject.entrySet()) {
Object obj = jsonObject.get(entry.getKey());
if (obj instanceof JSONObject) {
JSONObject obj1 = (JSONObject) obj;
deepLength = deepLength + 1;
getDeep(obj1, deepLength);
}
}
if (maxDeep <= deepLength) {
maxDeep = deepLength;
}
return maxDeep+1;
}
};