
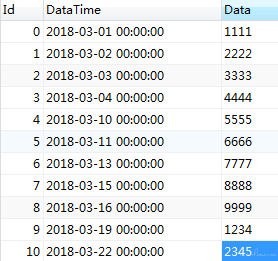
假设数据是这样的,日期各不相同,且已经按时间升序排序
错开一行,生成新的数据表,并计算时间间隔
再按时间差降序排序,取第一个即可

SELECT NewTable.DataTime, NewTable.NewDate, DATEDIFF(NewTable.DataTime, NewTable.NewDate) AS Diff
FROM (
SELECT DataTime
, (
SELECT DataTime
FROM TestTest Alias
WHERE TestTest.DataTime > Alias.DataTime
ORDER BY DataTime DESC
LIMIT 1
) AS NewDate
FROM TestTest
) NewTable
ORDER BY Diff DESC
LIMIT 1
题目可以理解为比较同一个表中每行的日期列,然后选择一个值最大的,说白了就是上下相邻的两个数据进行比较,然后选出差值最大一个。
答案为:select t1.id, t1.create_time, t2.id, t2.create_time, timediff(t2.create_time, t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id order by diff desc limit 1;
#t1 表为原始表,t2 表可以理解原始表的复制表,
下面以 mysql 为例,使用了 mysql 自连接,即同一个表自己和自己进行连表查询(一般遇到最多的是不同的两个表进行连表查询,如 inner join, left join, right join 等等)
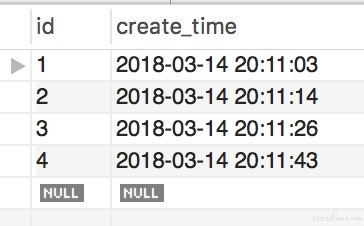
数据库表类似:
下面为 SQL 语句:
select t1.id, t1.create_time, t2.id, t2.create_time, timediff(t2.create_time,t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id;
# 关键点 1: on t1.id+1 = t2.id,意思是连表查询的条件为原始表的 id + 1 与复制表的 id 相同,这样做的目的就是为了把原始表的第一行的数据与复制表的下一行的数据生成于连表查询的结果表同一行中;(说白了就是同一个表的数据错行显示在结果表上)
关键点 2: timediff(t2.create_time, t1.create_time) as diff, 这样做是对 t2 的列对 t1 表的列取差值,并取别名 (为后面的排序做准备)
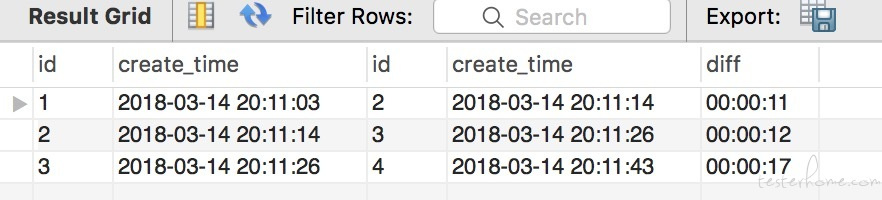
查询结果如下:
排序使用 order by diff;找出间隔最大的那一个,即使用 limit 1;最后查询结果如下:

当然如果你只想显示最大的值
select timediff(t2.create_time, t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id order by diff desc limit 1;
结果如下:

希望能面试的上。
情况 1,找到两条连续的数据中,时间间隔最大的
select max(
TIMESTAMPDIFF(
SECOND,
ii.cTime,
(
select cTime
from issues
where id=(select min(id) from issues where id > ii.id)
)
)
) as maxDateRange
from issues as ii
情况 2,找到所有数据中最大的时间差?
select TIMESTAMPDIFF(SECOND, MIN(cTime), MAX(cTime)) as maxDataRange from issues
不错的问题
使用 Max 和 DATEDIFF 函数就行了吧,感觉 DATEDIFF 这个函数用的少
数据测试工程师的面试题
假设数据是这样的,日期各不相同,且已经按时间升序排序
错开一行,生成新的数据表,并计算时间间隔
再按时间差降序排序,取第一个即可
SELECT NewTable.DataTime, NewTable.NewDate, DATEDIFF(NewTable.DataTime, NewTable.NewDate) AS Diff
FROM (
SELECT DataTime
, (
SELECT DataTime
FROM TestTest Alias
WHERE TestTest.DataTime > Alias.DataTime
ORDER BY DataTime DESC
LIMIT 1
) AS NewDate
FROM TestTest
) NewTable
ORDER BY Diff DESC
LIMIT 1
我选择用 cursor 外加一个临时变量,循环比对,这种写法在 oracle 时代用的不要太多哦
嗯,应该把 SQL 分开会易懂一些
SELECT DataTime,
(
SELECT DataTime
FROM TestTest Alias
WHERE TestTest.DataTime > Alias.DataTime
ORDER BY DataTime DESC
LIMIT 1
) AS NewDate
FROM TestTest
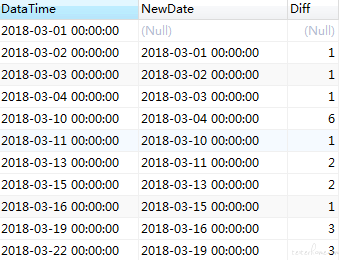
这块 sql 执行出来就是第 2 张图的结果,括号里面的 sql 对应第二列数据(NewDate)。
因为日期已经排好序了,所以取比DataTime小的日期里面最大的日期,就是 NewDate。
不知道这样说明白了没。。
SELECT DataTime
FROM TestTest Alias
WHERE TestTest.DataTime > Alias.DataTime
ORDER BY DataTime DESC
LIMIT 1
这个里面是什么意思?是 mysql 吗?
话说 “用 sql 找出间隔最久没有数据的间隔” 也不加个标点,我都没看懂问题
我明白了,关键在:
SELECT DataTime,
(
SELECT DataTime
FROM TestTest Alias
WHERE TestTest.DataTime > Alias.DataTime
ORDER BY DataTime DESC
LIMIT 1
) AS NewDate
FROM TestTest
里面
SELECT DataTime
FROM TestTest Alias
WHERE TestTest.DataTime > Alias.DataTime
ORDER BY DataTime DESC
LIMIT 1
这个子查询不能单独存在,必须和外面的一起。
题目可以理解为比较同一个表中每行的日期列,然后选择一个值最大的,说白了就是上下相邻的两个数据进行比较,然后选出差值最大一个。
答案为:select t1.id, t1.create_time, t2.id, t2.create_time, timediff(t2.create_time, t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id order by diff desc limit 1;
#t1 表为原始表,t2 表可以理解原始表的复制表,
下面以 mysql 为例,使用了 mysql 自连接,即同一个表自己和自己进行连表查询(一般遇到最多的是不同的两个表进行连表查询,如 inner join, left join, right join 等等)
数据库表类似:
下面为 SQL 语句:
select t1.id, t1.create_time, t2.id, t2.create_time, timediff(t2.create_time,t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id;
# 关键点 1: on t1.id+1 = t2.id,意思是连表查询的条件为原始表的 id + 1 与复制表的 id 相同,这样做的目的就是为了把原始表的第一行的数据与复制表的下一行的数据生成于连表查询的结果表同一行中;(说白了就是同一个表的数据错行显示在结果表上)
关键点 2: timediff(t2.create_time, t1.create_time) as diff, 这样做是对 t2 的列对 t1 表的列取差值,并取别名 (为后面的排序做准备)
查询结果如下:
排序使用 order by diff;找出间隔最大的那一个,即使用 limit 1;最后查询结果如下:
当然如果你只想显示最大的值
select timediff(t2.create_time, t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id order by diff desc limit 1;
结果如下:
希望能面试的上。
情况 1,找到两条连续的数据中,时间间隔最大的
select max(
TIMESTAMPDIFF(
SECOND,
ii.cTime,
(
select cTime
from issues
where id=(select min(id) from issues where id > ii.id)
)
)
) as maxDateRange
from issues as ii
情况 2,找到所有数据中最大的时间差?
select TIMESTAMPDIFF(SECOND, MIN(cTime), MAX(cTime)) as maxDataRange from issues
mysql:使用时间和行号存储为一个结果集,存储两个(用来比较的),结果集中按时间排序,保证结果的排序规则一致;然后使用第二个结果集的下一行与第一个结果集的当前行相减,然后取最大的。
select max(to_days(t2.test_time) - to_days(t1.test_time)) from
(select test_time,(@row_no:=@row_no+1) as row_no from testreport,(select (@row_no:=0)) b order by test_time) t1
join (select test_time,(@row_no1:=@row_no1+1) as row_no from testreport,(select (@row_no1:=0)) b order by test_time) t2
on t1.row_no = t2.row_no-1