-
mysql 亿级数据优化 at 2018年08月28日
这个可以作为 mysql 优化的 checklist
 . 一个小小的想法:如果 LZ 可以加上优化的步骤如使用 Explain 语句检查问题原因,检查 Process List,检查最大连接数等类似过程,那就更完美了。
. 一个小小的想法:如果 LZ 可以加上优化的步骤如使用 Explain 语句检查问题原因,检查 Process List,检查最大连接数等类似过程,那就更完美了。 -
TesterHome 深圳线下沙龙第六期活动总结 ppt at 2018年05月14日
优先的苏老板。给力的社区!
-
# 每日一道面试题 # 在一个数据库表中,有不同天的多条记录,用 sql 找出间隔最久没有数据的间隔 at 2018年03月14日
题目可以理解为比较同一个表中每行的日期列,然后选择一个值最大的,说白了就是上下相邻的两个数据进行比较,然后选出差值最大一个。
答案为:select t1.id, t1.create_time, t2.id, t2.create_time, timediff(t2.create_time, t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id order by diff desc limit 1;
#t1 表为原始表,t2 表可以理解原始表的复制表,
下面以 mysql 为例,使用了 mysql 自连接,即同一个表自己和自己进行连表查询(一般遇到最多的是不同的两个表进行连表查询,如 inner join, left join, right join 等等)
数据库表类似:
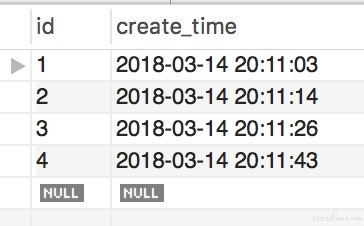
下面为 SQL 语句:
select t1.id, t1.create_time, t2.id, t2.create_time, timediff(t2.create_time,t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id;
# 关键点 1: on t1.id+1 = t2.id,意思是连表查询的条件为原始表的 id + 1 与复制表的 id 相同,这样做的目的就是为了把原始表的第一行的数据与复制表的下一行的数据生成于连表查询的结果表同一行中;(说白了就是同一个表的数据错行显示在结果表上)
关键点 2: timediff(t2.create_time, t1.create_time) as diff, 这样做是对 t2 的列对 t1 表的列取差值,并取别名 (为后面的排序做准备)
查询结果如下:
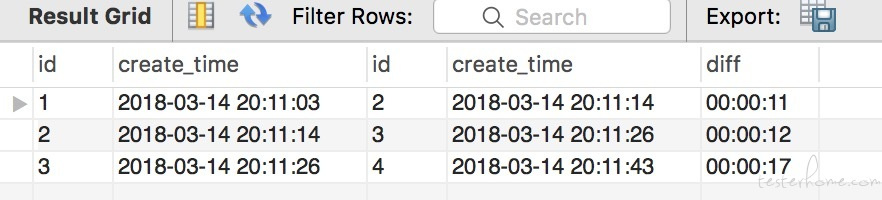
排序使用 order by diff;找出间隔最大的那一个,即使用 limit 1;最后查询结果如下:

当然如果你只想显示最大的值
select timediff(t2.create_time, t1.create_time) as diff from timestamps t1 inner join timestamps t2 on t1.id +1 = t2.id order by diff desc limit 1;
结果如下:

希望能面试的上。

-
互联网小公司里 QA Leader 由谁来领导更合理 (在小公司如何做好测试的向上管理)? at 2016年07月19日
流程,规范,文档?需要什么东西,细化到什么程度是根据实际项目情况来的。领导给的只能是大体的方向,具体实施需要你来做。这才是你价值的体现。所有功能细化到 1,2,3,4 点才能开发,才能测试的话,估计你的项目黄了,你的职位也不在了 (当然你还可以找其他工作)。此时情况下要和开发,设计,产品经理多沟通。直到所有人达成一致的共识。