HttpRunner HttpRunner 实现参数化数据驱动机制
从 1.1.0 版本开始,数据驱动机制进行了较大的优化和调整。
请参考:《HttpRunner 再议参数化数据驱动机制》
背景
在自动化测试中,经常会遇到如下场景:
1、测试搜索功能,只有一个搜索输入框,但有 10 种不同类型的搜索关键字;
2、测试账号登录功能,需要输入用户名和密码,按照等价类划分后有 20 种组合情况。
这里只是随意找了两个典型的例子,相信大家都有遇到过很多类似的场景。总结下来,就是在我们的自动化测试脚本中存在参数,并且我们需要采用不同的参数去运行。
经过概括,参数基本上分为两种类型:
- 单个独立参数:例如前面的第一种场景,我们只需要变换搜索关键字这一个参数
- 多个具有关联性的参数:例如前面的第二种场景,我们需要变换用户名和密码两个参数,并且这两个参数需要关联组合
然后,对于参数而言,我们可能具有一个参数列表,在脚本运行时需要按照不同的规则去取值,例如顺序取值、随机取值、循环取值等等。
对于这一块儿,没有太多新的概念,这就是典型的参数化和数据驱动。遗憾的是,当前HttpRunner并未支持该功能特性。
考虑到该需求的普遍性,并且近期提到该需求的的人也越来越多(issue #74, issue #87, issue #88, issue #97),因此趁着春节假期的空闲时间,决定优先实现下。
经过前面的场景分析,我们的目标已经很明确了,接下来就是如何实现的问题了。
借鉴 LoadRunner 的数据参数化
要造一个轮子,最好是先看下现有知名轮子的实现机制。之前有用过一段时间的 LoadRunner,对其参数化机制印象蛮深的,虽然它是性能测试工具,但在脚本参数化方面是通用的。
我们先看下在 LoadRunner 中是如何实现参数化的。
在 LoadRunner 中,可以在脚本中创建一个参数,然后参数会保存到一个.dat的文件中,例如下图中的psd.dat。

在.dat文件中,是采用表格的形式来存储参数值,结构与CSV基本一致。
对于单个独立参数,可以将参数列表保存在一个单独的.dat文件中,第一行为参数名称,后续每一行为一个参数值。例如本文背景介绍中的第一类场景,数据存储形式如下所示:
Keyword
hello
world
debugtalk
然后对于参数的取值方式,可以通过Select next row和Update value on进行配置。
Select next row的可选方式有:
- Sequential:顺序取值
- Random:随机取值
- Unique:为每个虚拟用户分配一条唯一的数据
Update value on的可选方式有:
- Each iteration:每次脚本迭代时更新参数值
- Each occurrence:每次出现参数引用时更新参数值
- Once:每条数据只能使用一次
而且,可以通过对这两种方式进行组合,配制出 9 种参数化方式。
另外,因为 LoadRunner 本身是性能测试工具,具有长时间运行的需求,假如Select next row选择为Unique,同时Update value on设置为Each iteration,那么就会涉及到参数用完的情况。在该种情况下,可通过When out of value配置项实现如下选择:
- Abort vuser:当超出时终止脚本
- Continue in a cyclic manner:当超出时回到列表头再次取值
- Continue with last value:使用参数表中的最后一个值
对于多个具有关联性的参数,可以将关联参数列表保存在一个.dat文件中,第一行为参数名称,后续每一行为一个参数值,参数之间采用逗号进行分隔。例如本文背景介绍中的第二类场景,数据存储形式如下所示:
UserName,Password
test1,111111
test2,222222
test3,333333
对于参数的取值方式,与上面单个独立参数的取值方式基本相同。差异在于,我们可以只配置一个参数(例如UserName)的取值方式,然后其它参数(例如Password)的取值方式选择为same line as UserName。如此一来,我们就可以保证参数化时的数据关联性。
LoadRunner 的参数化机制就回顾到这里,可以看出,其功能还是很强大的,使用也十分灵活。
设计思路演变历程
现在再回到我们的 HttpRunner,要如何来实现参数化机制呢?
因为 LoadRunner 的参数化机制比较完善,用户群体也很大,因此我在脑海里最先冒出的想法就是照抄 LoadRunner,将 LoadRunner 在 GUI 中配置的内容在 HttpRunner 中通过YAML/JSON来进行配置。
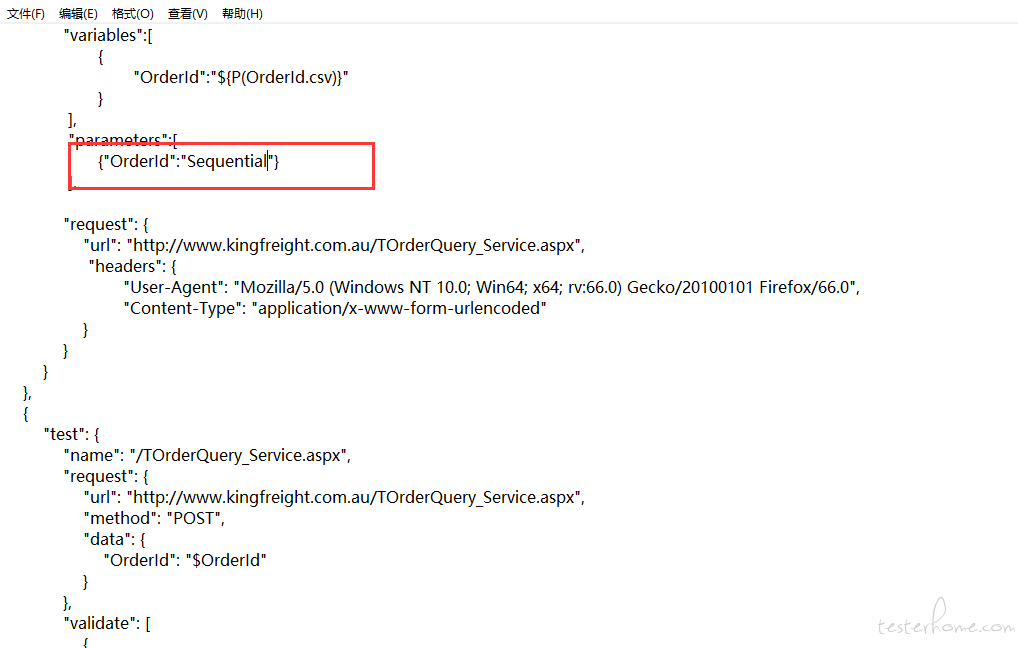
按照这个思路,在 HttpRunner 的 config 中,就要有一块儿地方用来进行参数化配置,暂且设定为parameters吧。然后,对于每一个参数,其参数列表要单独存放在文件中,考虑到 LoadRunner 中的.dat文件基本就是CSV格式,因此可以约定采用大众更熟悉的.csv文件来存储参数;在脚本中,要指定参数变量从哪个文件中取值,那么就需要设定一个parameter_file,用于指定对应的参数文件路径。接下来,要实现取值规则的配置,例如是顺序取值还是随机取值,那么就需要设定select_next_row和update_value_on。
根据该设想,在YAML测试用例文件中,数据参数化将描述为如下形式:
- config:
name: "demo for data driven."
parameters:
- Keyword:
parameter_file: keywords.csv
select_next_row: Random
update_value_on: EachIteration
- UserName:
parameter_file: account.csv
select_next_row: Sequential
update_value_on: EachIteration
- Password:
parameter_file: account.csv
select_next_row: same line as UserName
这个想法基本可行,但就是感觉配置项有些繁琐,我们可以尝试再对其进行简化。
首先,比较明显的,针对每个参数都要配置select_next_row和update_value_on,虽然从功能上来说比较丰富,但是对于用户来说,这些功能并不都是必须的。特别是update_value_on这个参数,绝大多数情况下我们的需求应该都是采用Each iteration,即每次脚本再次运行时更新参数值。因此,我们可以去除update_value_on这个配置项,默认都是采用Each iteration的方式。
经过第一轮简化,配置描述方式变为如下形式:
- config:
name: "demo for data driven."
parameters:
- Keyword:
parameter_file: keywords.csv
select_next_row: Random
- UserName:
parameter_file: account.csv
select_next_row: Sequential
- Password:
parameter_file: account.csv
select_next_row: same line as UserName
然后,我们可以看到UserName和Password这两个参数,它们有关联性,但却各自单独进行了配置;而且对于有关联性的参数,除了需要对第一个参数配置取值方式外,其它参数的select_next_row应该总是为same line as XXX,这样描述就显得比较累赘了。
既然是有关联性的参数,那就放在一起吧,参数名称可以采用约定的符号进行分离。考虑到参数变量名称通常包含字母、数字和下划线,同时要兼顾YAML/JSON中对字符的限制,因此选择短横线(-)作为分隔符吧。
经过第二轮简化,配置描述方式变为如下形式:
- config:
name: "demo for data driven."
parameters:
- Keyword:
parameter_file: keywords.csv
select_next_row: Random
- UserName-Password:
parameter_file: account.csv
select_next_row: Sequential
接着,我们再看下parameter_file参数。因为我们测试用例中的参数名称必须与数据源进行绑定,因此这一项信息是不可少的。但是在描述形式上,还是会感觉有些繁琐。再一想,既然我们本来就要指定参数名称,那何必不将参数名称约定为文件名称呢?
例如,对于参数Keyword,我们可以将其数据源文件名称约定为Keyword.csv;对于参数UserName和Password,我们可以将其数据源文件名称约定为UserName-Password.csv;然后,再约定数据源文件需要与当前YAML/JSON测试用例文件放置在同一个目录。
经过第三轮简化,配置描述方式变为如下形式:
- config:
name: "demo for data driven."
parameters:
- Keyword:
select_next_row: Random
- UserName-Password:
select_next_row: Sequential
同时该用例文件同级目录下的数据源文件名称为Keyword.csv和UserName-Password.csv。
现在,我们就只剩下select_next_row一个配置项了。既然是只剩一项,那就也省略配置项名称吧。
最终,我们的配置描述方式变为:
- config:
name: "demo for data driven."
parameters:
- Keyword: Random
- UserName-Password: Sequential
不过,我们还忽略了一个信息,那就是脚本的运行次数。假如参数取值都是采用Sequential的方式,那么我们可以将不同组参数进行笛卡尔积的组合,这是一个有限次数,可以作为自动化测试运行终止的条件;但如果参数取值采用Random的方式,即每次都是在参数列表里面随机取值,那么就不好界定自动化测试运行终止的条件了,我们只能手动进行终止,或者事先指定运行的总次数,不管是采用哪种方式,都会比较麻烦。
针对参数取值采用Random方式的这个问题,我们不妨换个思路。从数据驱动的角度来看,我们期望在自动化测试时能遍历数据源文件中的所有数据,那么重复采用相同参数进行测试的意义就不大了。因此,在选择Random的取值方式时,我们可以先将参数列表进行乱序排序,然后采用顺序的方式进行遍历;对于存在多组参数的情况,也可以实现乱序排序后再进行笛卡尔积的组合方式了。
到此为止,我们的参数化配置方式应该算是十分简洁了,而且在功能上也能满足常规参数化的配置需求。
最后,我们再回过头来看脚本参数化设计思路的演变历程,基本上都可以概括为约定大于配置,这的确也是HttpRunner崇尚和遵循的准则。
开发实现
设计思路理顺了,实现起来就比较简单了,点击此处查看相关代码,就会发现实际的代码量并不多。
在这里我就只挑几个典型的点讲下。
数据源格式约定
既然是参数化,那么肯定会存在数据源的问题,我们约定采用.csv文件格式来存储参数列表。同时,在同一个测试场景中可能会存在多个参数的情况,为了降低问题的复杂度,我们可以约定独立参数存放在独立的.csv文件中,多个具有关联性的参数存放在一个.csv文件中。另外,我们同时约定在.csv文件中的第一行必须为参数名称,并且要与文件名保持一致;从第二行开始为参数值,每个值占一行。
例如,keyword这种独立的参数就可以存放在keyword.csv中,内容形式如下:
keyword
hello
world
debugtalk
username和password这种具有关联性的参数就可以存放在username-password.csv中,内容形式如下:
username,password
test1,111111
test2,222222
test3,333333
csv 解析器
数据源的格式约定好了,我们要想进行读取,那么就得有一个对应的解析器。因为我们后续想要遍历每一行数据,并且还会涉及到多个参数进行组合的情况,因此我们希望解析出来的每一行数据应该同时包含参数名称和参数值。
于是,我们的数据结构就约定采用list of dict的形式。即每一个.csv文件解析后会得到一个列表(list),而列表中的每一个元素为一个字典结构(dict),对应着一行数据的参数名称和参数值。具体实现的代码函数为_load_csv_file。
例如,上面的username-password.csv经过解析,会生成如下形式的数据结构。
[
{'username': 'test1', 'password': '111111'},
{'username': 'test2', 'password': '222222'},
{'username': 'test3', 'password': '333333'}
]
这里还会涉及到一个问题,就是参数取值顺序。
在YAML/JSON测试用例中,我们会配置参数的取值顺序,是要顺序取值(Sequential)还是乱序随机取值(Random)。对于顺序的情况没啥好说的,默认从.csv文件中读取出的内容就是顺序的;对于随机取值,更确切地说,应该是乱序取值,我们需要进行一次乱序排序,实现起来也很简单,使用random.shuffle函数即可。
if fetch_method.lower() == "random":
random.shuffle(csv_content_list)
多个参数的组合
然后,对于多个参数的情况,为了组合出所有可能的情况,我们就需要用到笛卡尔积的概念。直接看例子可能会更好理解些。
例如我们在用例场景中具有三个参数,a为独立参数,参数列表为 [1, 2];x和y为关联参数,参数列表为 [[111,112], [121,122]];经过解析后,得到的数据分别为:
a:
[{"a": 1}, {"a": 2}]
x & y:
[
{"x": 111, "y": 112},
{"x": 121, "y": 122}
]
那么经过笛卡尔积,就可以组合出 4 种情况,组合后的结果应该为:
[
{'a': 1, 'x': 111, 'y': 112},
{'a': 1, 'x': 121, 'y': 122},
{'a': 2, 'x': 111, 'y': 112},
{'a': 2, 'x': 121, 'y': 122}
]
这里需要强调的是,多个参数经过笛卡尔积运算转换后,仍然是list of dict的数据结构,列表中的每一个字典(dict)代表着参数的一种组合情况。
参数化数据驱动
现在,我们已经实现了在YAML/JSON测试用例文件中对参数进行配置,从.csv数据源文件中解析出参数列表,并且生成所有可能的组合情况。最后还差一步,就是如何使用参数值来驱动测试用例的执行。
听上去很高大上,但实际却异常简单,直接对照着代码来说吧。

对于每一组参数组合情况来说,我们完全可以将其视为当前用例集运行时定义的变量值。而在 HttpRunner 中每一次运行测试用例集的时候都需要对runner.Runner做一次初始化,里面会用到定义的变量(即config_dict["variables"]),那么,我们完全可以在每次初始化的时候将组合好的参数作为变量传进去,假如存在同名的变量,就进行覆盖。
这样一来,我们就可以使用所有的参数组合情况来依次驱动测试用例的执行,并且每次执行时都采用了不同的参数,从而也就实现了参数化数据驱动的目的。
效果展示
最后我们再来看下实际的运行效果吧。
假设我们有一个获取 token 的接口,我们需要使用 user_agent 和 app_version 这两个参数来进行参数化数据驱动。
YAML 测试用例的描述形式如下所示:
- config:
name: "user management testset."
parameters:
- user_agent: Random
- app_version: Sequential
variables:
- user_agent: 'iOS/10.3'
- device_sn: ${gen_random_string(15)}
- os_platform: 'ios'
- app_version: '2.8.6'
request:
base_url: $BASE_URL
headers:
Content-Type: application/json
device_sn: $device_sn
- test:
name: get token with $user_agent and $app_version
api: get_token($user_agent, $device_sn, $os_platform, $app_version)
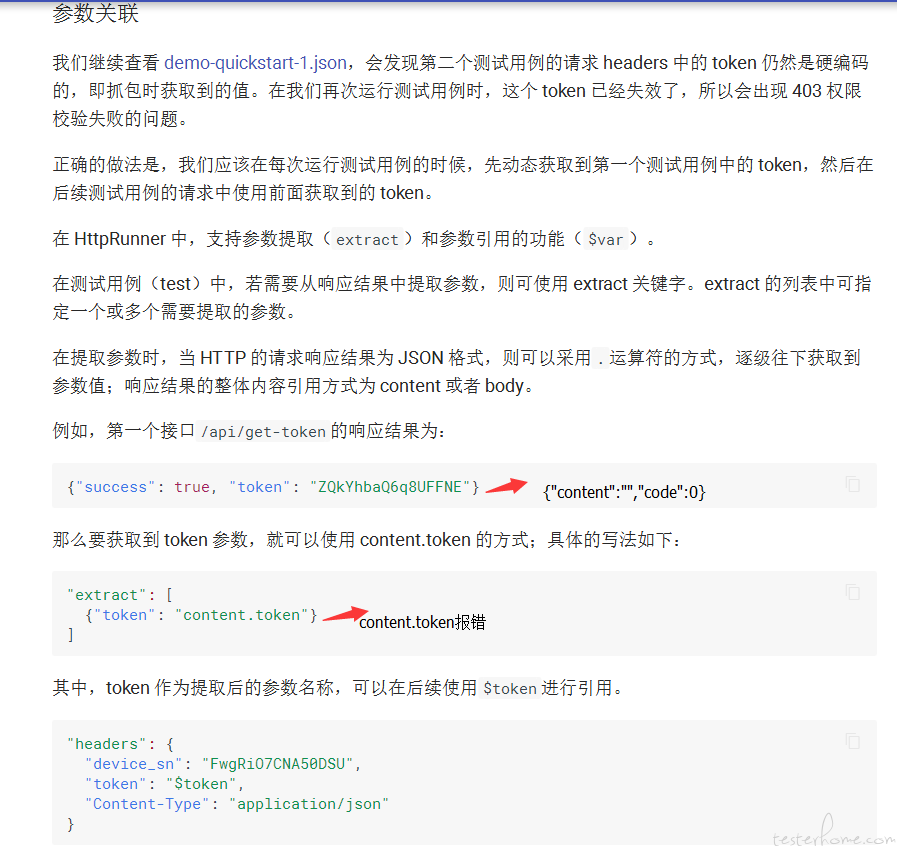
extract:
- token: content.token
validate:
- "eq": ["status_code", 200]
- "len_eq": ["content.token", 16]
其中,user_agent 和 app_version 的数据源列表分别为:
user_agent
iOS/10.1
iOS/10.2
iOS/10.3
app_version
2.8.5
2.8.6
那么,经过笛卡尔积组合,应该总共有 6 种参数组合情况,并且 user_agent 为乱序取值,app_version 为顺序取值。
最终的测试结果如下所示:
$ hrun tests/data/demo_parameters.yml
Running tests...
----------------------------------------------------------------------
get token with iOS/10.2 and 2.8.5 ... INFO:root: Start to POST http://127.0.0.1:5000/api/get-token
INFO:root: status_code: 200, response_time: 13 ms, response_length: 46 bytes
OK (0.014845)s
get token with iOS/10.2 and 2.8.6 ... INFO:root: Start to POST http://127.0.0.1:5000/api/get-token
INFO:root: status_code: 200, response_time: 2 ms, response_length: 46 bytes
OK (0.003909)s
get token with iOS/10.1 and 2.8.5 ... INFO:root: Start to POST http://127.0.0.1:5000/api/get-token
INFO:root: status_code: 200, response_time: 3 ms, response_length: 46 bytes
OK (0.004090)s
get token with iOS/10.1 and 2.8.6 ... INFO:root: Start to POST http://127.0.0.1:5000/api/get-token
INFO:root: status_code: 200, response_time: 5 ms, response_length: 46 bytes
OK (0.006673)s
get token with iOS/10.3 and 2.8.5 ... INFO:root: Start to POST http://127.0.0.1:5000/api/get-token
INFO:root: status_code: 200, response_time: 3 ms, response_length: 46 bytes
OK (0.004775)s
get token with iOS/10.3 and 2.8.6 ... INFO:root: Start to POST http://127.0.0.1:5000/api/get-token
INFO:root: status_code: 200, response_time: 3 ms, response_length: 46 bytes
OK (0.004846)s
----------------------------------------------------------------------
Ran 6 tests in 0.046s
至此,我们就已经实现了参数化数据驱动的需求。对于测试用例中参数的描述形式,大家要是发现还有更加简洁优雅的方式,欢迎反馈给我。
最后,本文发表于 2018 年大年初一,祝大家新年快乐,狗年旺旺旺!