HttpRunner HttpRunner 再议参数化数据驱动机制
在《HttpRunner 实现参数化数据驱动机制》一文中,我们实现了参数化数据驱动的需求,并阐述了其设计思路的演变历程和开发实现涉及的核心要素。
问题及思考
经过一段时间的实际应用后,虽然参数化数据驱动的功能可以正常使用,但终究感觉不够优雅。
概括下来,主要有如下 4 个方面。
1、调用方式不够自然,描述方式比较繁琐。
- config:
name: "user management testset."
parameters:
- user_agent: Random
- app_version: Sequential
描述参数取值方式的时候,需要采用Sequential和Random来进行指定是要顺序取值还是随机乱序取值。暂且不说Sequential这个单词大家能否总是保证拼写正确,绝大多数情况下都是顺序取值,却也总是需要指定Sequential,的确会比较繁琐。
2、即使是简单的数据驱动场景,也同样需要准备 CSV 文件,问题复杂化。
指定数据驱动的数据源时,必须创建一个 CSV 文件,并将参数化数据放置在其中。对于大数据量的情况可能没啥问题,但是假如是非常简单的场景,例如上面的例子中,我们只需要对app_version设定参数列表 ['2.8.5', '2.8.6'],虽然只有两个参数值,也同样需要去单独创建一个 CSV 文件,就会显得比较繁琐了。
试想,假如对于简单的参数化数据驱动场景,我们可以直接在 YAML/JSON 测试用例中描述参数列表,如下所示,那就简单得多了。
- config:
name: "user management testset."
parameters:
- user_agent: ['iOS/10.1', 'iOS/10.2', 'iOS/10.3']
- app_version: ['2.8.5', '2.8.6']
3、无法兼顾没有现成参数列表,或者需要更灵活的方式动态生成参数列表的情况。
例如,假如我们期望每次执行测试用例的时候,里面的参数列表都是按照特定规则动态生成的。那在之前的模式下,我们就只能写一个动态生成参数的函数,然后在每次运行测试用例之前,先执行函数生成参数列表,然后将这些参数值导入到 CSV 文件中。想想都感觉好复杂。
既然 HttpRunner 已经实现了在 YAML/JSON 测试用例中调用函数的功能,那为啥不将函数调用与获取参数化列表的功能实现和描述语法统一起来呢?
试想,假如我们需要动态地生成 10 个账号,包含用户名和密码,那我们就可以将动态生成参数的函数放置到 debugtalk.py 中:
def get_account(num):
accounts = []
for index in range(1, num+1):
accounts.append(
{"username": "user%s" % index, "password": str(index) * 6},
)
return accounts
然后,在 YAML/JSON 测试用例中,再使用 ${} 的语法来调用函数,并将函数返回的参数列表传给需要参数化的变量。
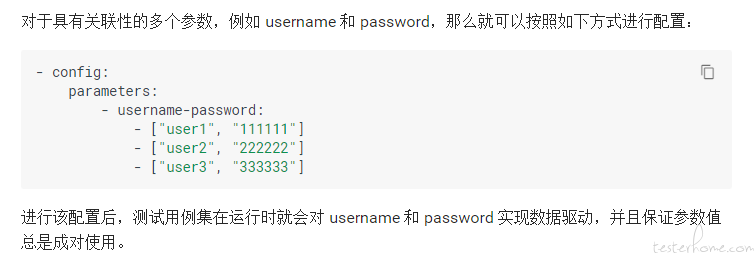
- config:
parameters:
- username-password: ${get_account(10)}
实现了这一特性后,要再兼容从 CSV 文件数据源中读取参数列表的方式也很简单了。我们只需要在 HttpRunner 中内置一个解析 CSV 文件的 parameterize 函数(也可以简写为 P 函数),然后就可以在 YAML/JSON 中通过函数调用的方式引用 CSV 文件了。如下例中的 user_id 所示。
- config:
name: "demo"
parameters:
- user_agent: ["iOS/10.1", "iOS/10.2", "iOS/10.3"]
- user_id: ${P(user_id.csv)}
- username-password: ${get_account(10)}
这样一来,我们就可以优雅地实现参数列表数据源的指定了,并且从概念理解和框架实现的角度也能完成统一,即对于 parameters 中的参数变量而言,传入的都是一个参数列表,这个列表可以是直接指定的,可以是从 CSV 文件中加载的,也可以是通过调用自定义函数动态生成的。
4、数据驱动只能在测试用例集(testset)层面,不能针对单个测试用例(testcse)进行数据驱动。
例如,用例集里面有两个接口,第一个接口是获取 token,第二个接口是创建用户(参考 QuickStart 中的 demo-quickstart-6.json)。那么按照之前的设计,在 config 中配置了参数化之后,就是针对整个测试用例集(testset)层面的数据驱动,使用每一组参数运行的时候都要先执行第一个接口,再执行第二个接口。
这可能就跟我们预期的情况不一样了。假如我们期望的是只针对第二个接口做数据驱动,即第一个接口只需要调用一次获取到 token,然后使用参数列表中的数值分别调用第二个接口创建用户,那么之前的方法就行不通了。
既然有这类需求,因此数据驱动也应该具有作用域的概念。
类似于定义的 variables,定义在 config 中是全局有效的,定义在 test 中就只对当前测试用例有效。同样地,我们也可以针对 parameters 增加作用域的概念,若只需实现对当前用例(testcase)的参数化数据驱动,就可以将 parameters 配置放置到当前 test 中。
新的实现
想法明确了,改造实现也就比较简单了。
从版本 1.1.0 开始,HttpRunner 便支持了上述新的数据驱动方式。详细的使用方法,可参考如下使用说明文档:
http://cn.httprunner.org/advanced/data-driven/
至此,HttpRunner 的数据驱动机制就比较完善和稳定了,应该可以解决绝大多数数据驱动场景的需求。
遗留问题
不过,还有一类场景暂时没有实现支持,即需要根据先前接口返回结果来对后续接口进行数据驱动的情况。
以如下场景为例:
- 加载用户列表,获取当前用户列表中的所有用户;
- 依次对每一个用户进行点赞或者发送消息的操作。
这和前面的第三条有点类似,都需要先动态获取参数列表,然后再使用获取得到的参数列表进行数据驱动。但也存在较大的差异,即获取用户列表的操作也是测试场景的一部分,并且通常因为需要共享 session 和 cookies,因此不能将第一步的请求放置到 debugtalk.py 中。
之前的一个想法是,在第一个接口中,将结果返回的用户列表提取(extract)出来保存至变量(user_list),然后在后续需要做数据驱动的接口中,在 parameters 中引用前面提取出的用户列表($user_list);若有需要,还可以自定义函数(parse_users),将前面提取出来的用户列表转换至框架支持的格式。
- test:
name: load user list
request: {...}
extract:
- user_list: content.users
- test:
name: send message to user
parameters:
- user: ${parse_users($user_list)}
request: {...}
这个方式乍一看是可行的,但实际却是行不通的。
问题在于,在 HttpRunner 的数据驱动机制中,采用参数列表构造测试用例是在初始化阶段,做的工作主要是根据参数列表中的数据生成测试用例并添加至 unittest 的 TestSuite 中,此时测试用例还没有进入执行环节,因此也没法从接口的响应结果中提取参数列表。
若非要解决这个问题,针对 test 的数据驱动,可以将解析 parameters 的实现放置到 request 中;这的确可以实现上述场景中的功能,但在测试用例执行统计方面就会出现问题。以该场景为例,假如获取到的用户列表有 100 个用户,那么整个用例集将执行 101 次测试用例,但最终生成的测试报告中却只会展示运行了 2 条测试用例。
针对该场景,我还没有想到很好的解决方案,暂且将其作为一个遗留问题吧。若你有比较好的实现方案,欢迎反馈给我,或者直接提交 PR。