移动性能测试 关于用 adb 命令统计手机所有 app 流量的优化
最近参考了大家一些关于流量的测试方法,
https://testerhome.com/topics/2643
https://testerhome.com/topics/2068
我自己也写了一个统计手机所有 app 流量的脚本,但是执行时间太慢了,手机大概 200 个 package,统计一次流量要将近 50 秒
其中 adb shell dumpsys package '+package+' | find "userId" 这条命令大概要执行 200 次 耗时 30 秒
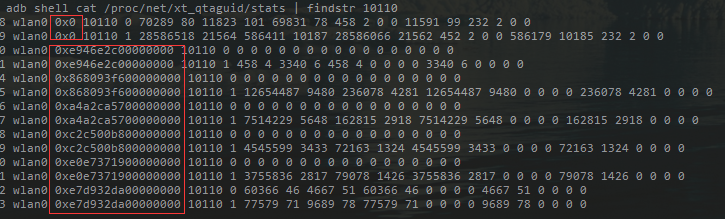
adb shell cat /proc/net/xt_qtaguid/stats | find "'+uid+'" 这条命令执行 100 多次,耗时 10 秒
想请大家帮忙看下有没有什么优化的方法,比如:使用 adb 命令一次性获取手机里面所有 App 的 uid 和 packageName,或者脚本的逻辑优化
# coding:utf-8
import subprocess
import time
def get_packages():
'''
获取所有的包名
:return:
'''
#存储包名
packages=[]
#获取所有的包
cmd='adb shell pm list package'
proc=subprocess.Popen(cmd,stdout=subprocess.PIPE,stderr=subprocess.PIPE,shell=True)
#以换行来划分
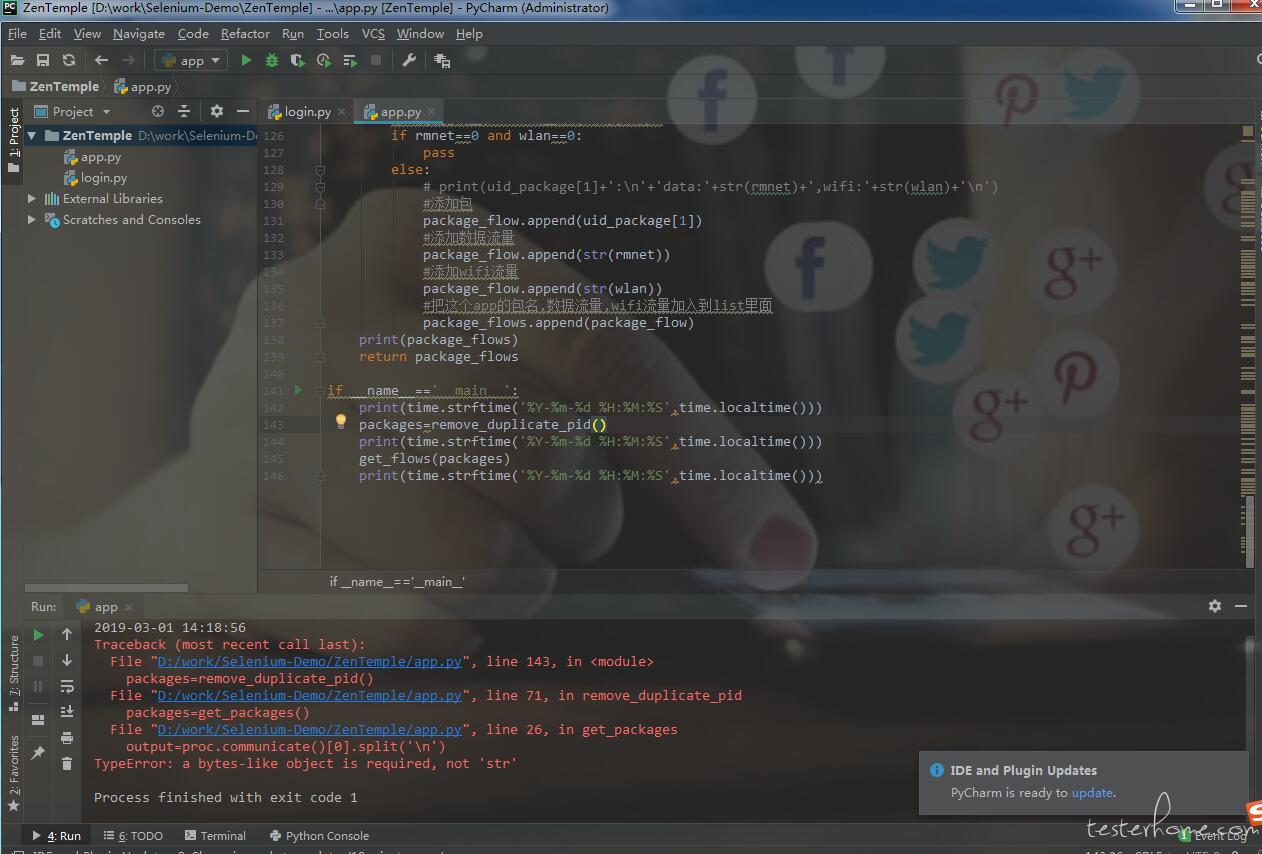
output=proc.communicate()[0].split('\n')
for package in output:
#去掉package:字符串
if 'package:' in package:
#去掉\r
package=package[8:].replace('\r','')
packages.append(package)
return packages
def get_uid(package):
'''
获取uid
:param package:
:return:
'''
uid=''
#获取uid
cmd='adb shell dumpsys package '+package+' | find "userId"'
proc=subprocess.Popen(cmd,stdout=subprocess.PIPE,stderr=subprocess.PIPE,shell=True)
#保留返回结果第一行
output=proc.communicate()[0].split('\n')[0]
#去掉空格
output=output.replace(' ','')
#判断结果里面是否有userId
if 'userId=' in output:
#找到 userId= 的下标
index=output.find('userId=')
#从 userId= 的下标+7,开始遍历,直到字符串结束
for j in range((index+7),len(output)):
#如果是数字,就拼接到uid
if output[j].isdigit():
uid=uid+output[j]
else:
#不是数字的时候,就停止拼接
break
return uid
else:
print('Not found uid')
return '0'
def remove_duplicate_pid():
'''
去掉重复的pid,获得整个设备的uid,package
:return:
'''
packages=get_packages()
uid_and_packages=[]
for package in packages:
#单个uid和package
uid_package=[]
#判定是否有重复的uid的标志位
flag=0
uid_package.append(get_uid(package))
uid_package.append(package)
for i in uid_and_packages:
#如果要加入的pid与已经存在相同,标志位置为1
if uid_package[0] == i[0]:
flag=1
#如果有重复的就去掉重复的,不添加
if flag==0:
uid_and_packages.append(uid_package)
return uid_and_packages
def get_per_flow(uid):
'''
根据uid获取流量
:param uid:
:return:
'''
#获取当前时间
#ltime=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())
#获取流量的adb命令
cmd='adb shell cat /proc/net/xt_qtaguid/stats | find "'+uid+'"'
proc=subprocess.Popen(cmd,stdout=subprocess.PIPE,stderr=subprocess.PIPE,shell=True)
output=proc.communicate()[0].split('\n')
#数据流量
rmnet=0
#wifi流量
wlan=0
for line in output:
#第6列数据是下行/接收流量,第八列数据是上行/发送流量
if 'rmnet' in line:
rmnet=rmnet+int(line.split(' ')[5])+int(line.split(' ')[7])
elif 'wlan' in line:
wlan=wlan+int(line.split(' ')[5])+int(line.split(' ')[7])
return rmnet,wlan
def get_flows(packages):
'''
获取所有的包名和对应流量
:return:返回数据为 [[包名1,数据流量1,wifi流量1],[包名2,数据流量2,wifi流量2],[包名3,数据流量3,wifi流量3]...]
'''
package_flows=[]
for uid_package in packages:
rmnet=0
wlan=0
package_flow=[]
#根据每一个uid查到对应的数据流量和wifi流量
rmnet,wlan=get_per_flow(uid_package[0])
#如果数据流量和wifi流量都为0,就不统计
if rmnet==0 and wlan==0:
pass
else:
# print(uid_package[1]+':\n'+'data:'+str(rmnet)+',wifi:'+str(wlan)+'\n')
#添加包
package_flow.append(uid_package[1])
#添加数据流量
package_flow.append(str(rmnet))
#添加wifi流量
package_flow.append(str(wlan))
#把这个app的包名,数据流量,wifi流量加入到list里面
package_flows.append(package_flow)
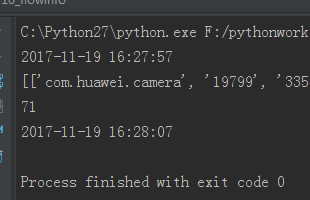
print(package_flows)
return package_flows
if __name__=='__main__':
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
packages=remove_duplicate_pid()
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
get_flows(packages)
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
==================分割线============================
以下内容 2017/11/19 更新
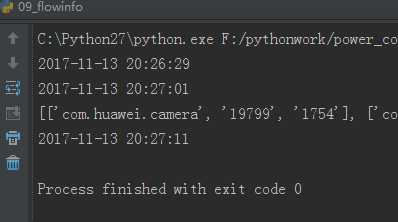
根据 @sandman 的建议,用 adb 命令一次性抓取所有的 uid 和 package,命令为:adb shell dumpsys package packages,重新调整了一下脚本,时间直接缩短到 10 秒
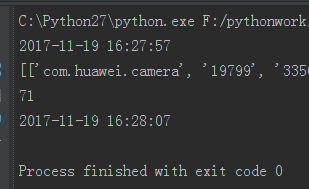
下面是更新后的代码:
# coding:utf-8
import subprocess
import time
def get_uid_and_packages():
uids=[]
uid=''
packages=[]
package=''
cmd='adb shell dumpsys package packages | findstr /c:"userId" /c:"Package ["'
proc=subprocess.Popen(cmd,stdout=subprocess.PIPE,stderr=subprocess.PIPE,shell=True)
output=proc.communicate()[0]
for line in output.split('\n'):
#判断结果里面是否有userId
if 'userId=' in line:
#找到 userId= 的下标
index=line.find('userId=')
#从 userId= 的下标+7,开始遍历,直到字符串结束
for i in range((index+7),len(line)):
#如果是数字,就拼接到uid
if line[i].isdigit():
uid=uid+line[i]
else:
#不是数字的时候,就停止拼接,初始化uid
uids.append(uid)
uid=''
break
#判断结果里面是否有Package [
elif 'Package [' in line:
#找到 Package [ 的下标
index_start=line.find('[')
index_end=line.find(']')
#从"["到"]"这里面的是package
package=line[index_start+1:index_end]
packages.append(package)
return [uids,packages]
def remove_duplicate_pid():
'''
去掉重复的pid,获得整个设备的uid,package
:return:
'''
uids=get_uid_and_packages()[0]
packages=get_uid_and_packages()[1]
uid_and_packages=[]
for i in range(len(packages)):
#单个uid和package
uid_package=[]
#判定是否有重复的uid的标志位
flag=0
uid_package.append(uids[i])
uid_package.append(packages[i])
for up in uid_and_packages:
#如果要加入的pid与已经存在相同,标志位置为1
if up[0] == uids[i]:
flag=1
#如果有重复的就去掉重复的,不添加
if flag==0:
uid_and_packages.append(uid_package)
return uid_and_packages
def get_per_flow(uid):
'''
根据uid获取流量
:param uid:
:return:
'''
#获取流量的adb命令
cmd='adb shell cat /proc/net/xt_qtaguid/stats | find "'+uid+'"'
proc=subprocess.Popen(cmd,stdout=subprocess.PIPE,stderr=subprocess.PIPE,shell=True)
output=proc.communicate()[0].split('\n')
#数据流量
rmnet=0
#wifi流量
wlan=0
for line in output:
#第6列数据是下行/接收流量,第八列数据是上行/发送流量
if 'rmnet' in line:
rmnet=rmnet+int(line.split(' ')[5])+int(line.split(' ')[7])
elif 'wlan' in line:
wlan=wlan+int(line.split(' ')[5])+int(line.split(' ')[7])
return rmnet,wlan
def get_flows():
'''
获取所有的包名和对应流量
:return:返回数据为 [[包名1,数据流量1,wifi流量1],[包名2,数据流量2,wifi流量2],[包名3,数据流量3,wifi流量3]...]
'''
package_flows=[]
for uid_package in remove_duplicate_pid():
rmnet=0
wlan=0
package_flow=[]
#根据每一个uid查到对应的数据流量和wifi流量
rmnet,wlan=get_per_flow(uid_package[0])
#如果数据流量和wifi流量都为0,就不统计
if rmnet==0 and wlan==0:
pass
else:
# print(uid_package[1]+':\n'+'data:'+str(rmnet)+',wifi:'+str(wlan)+'\n')
#添加包
package_flow.append(uid_package[1])
#添加数据流量
package_flow.append(str(rmnet))
#添加wifi流量
package_flow.append(str(wlan))
#把这个app的包名,数据流量,wifi流量加入到list里面
package_flows.append(package_flow)
print(package_flows)
print(len(package_flows))
return package_flows
if __name__=='__main__':
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
get_flows()
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))


 用了你教的方法
用了你教的方法