-
智能测试平台之文本相似度校验 at December 12, 2019
之前研究线上日志聚合时,也调研过相似度,有两种方法:
一种是简单的,python 标准库里有个 difflib,也可以用来比较两个文本的相似度,像这样:def similarity(str1, str2) -> float: '''获取两个字符串的相似度 [0~1]''' sm = difflib.SequenceMatcher(None, str1, str2) return sm.ratio()只是要不断的调整阈值,挺难定义的。(最后还是被我给废掉了,原因是我统计崩溃日志时,同一种原因的崩溃,但在两处位置调用,从 bug 的角度讲,这是两个位置的 bug。但从文本相似的角度讲,这是一个 bug。结果碰上个也不太细心的开发,最终 bug 没修复彻底)
一种难点的,也是使用 google 的算法
只说下思路:
1、使用 google 的 simHash 算法,获取文本的唯一指纹信息
2、比较两个指纹的 Haming 距离,当距离小于 3 时即认为相似
但实际使用时,当文本长度越长,对有差别的内容检测就越模糊,虽然可以通过加权的方式调整,但实际上仍很麻烦我比较同意作者的思路,没事就应该多折腾尝试,兴许就发现更多的测试思路和巧,不过也同意@Ouroboros 的观点,测试就看不那么相似的,如同我遇到的那个问题,两个相似度极高的崩溃 log,它是两个 bug
-
在社区和 github 看了测试平台,都是千篇一律的 curd 结合 appium、selenium、接口。 at November 27, 2019
能解决问题就好,何必在乎是否是重复的轮子,纠结于这个的话,你最好自己搞一套编程语言吧
-
这几年的杂乱总结 at March 01, 2019
我也有必要做这么一个总结
-
JMeter 与 Locust 压测结果比对 at September 17, 2018
作者大大,这个问题现在解决了吗,已经放弃 locust 了吗,最近在学习 locust,对比 jmeter 的结果,吓我一跳
-
[centos7][nginx][tshark] 基于 tshark 的页面流量统计 at May 17, 2018
使用 adb 统计流量不行吗,为什么弄这么复杂?
-
关于用 adb 命令统计手机所有 app 流量的优化 at December 21, 2017
hi,我通过 uid 统计的流量之和,发现与实际的流量相差很大,差不多在两倍左右(实际流量我是通过开发在代码中打印请求响应大小的 log),所以我怀疑使用此方法统计流量时有重复累加的可能。查找到这个文章http://www.voidcn.com/article/p-tolukrhb-vz.html。
其中 acct_tag_hex 为 0x0 的一行为某应用开机以来产生的总流量
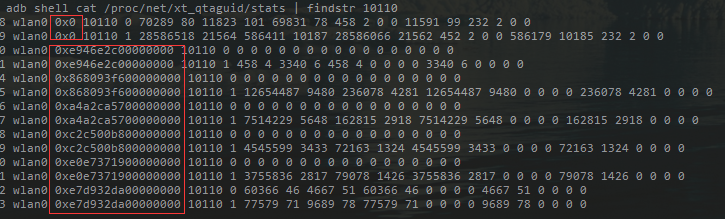
所以,这样的话,我想如果把包含 uid 的所有行里的数据累加,可能会出现重复统计,差不多刚好一倍,因此我在代码中把 0x0 过滤掉了if 'wlan' in line and '0x0' not in line:之后,再统计的结果中,下行流量总和与开发给出的结果很相近。
- adb 统计:

- log 打印:

但不清楚我的猜测是否正确,请多多指教
- adb 统计:
-
求一个 swipe 使用方法。python-appium 使用场景; at September 22, 2017
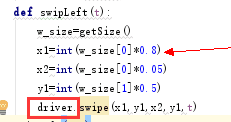
你的这个没有定义 driver 对象,所以是 NoneType object,应该把 self 传进去,使用 self.driver.swipe