devops [持续交付实践] pipeline:pipeline 使用之 MultiBranch Pipeline
前言
在探讨 multiBranch Pipeline 之前,很有必要先探讨下如何制定有效的代码分支管理规范,使用高效的版本控制系统,并对构建产物及其依赖进行管理。
我们首先要强调,需要进行版本控制的不仅是源代码,还有测试代码、数据库脚本、构建和部署脚本、依赖的库文件等,并且对构建产物的版本控制也同样重要。只有这些内容都纳入版本控制了,才能够确保所有的开发、测试、运维活动能够正常开展,系统能够被完整的搭建。
制定有效的分支管理策略对达成持续交付的目标非常重要。看过《持续交付》这本书的同学都知道,持续交付建议的方式是基于主干的开发(Trunk Based Development,TBD)模式,所有开发者在主干上频繁的提交代码,然后通过持续集成的机制,对修改触发快速的自动化验证和反馈,Google 就在坚持使用主干开发模式,所有人的所有更改直接提交到 Trunk 上。那持续交付为什么这样建议呢,实际应用中又是否能够适用?
常见分支管理策略
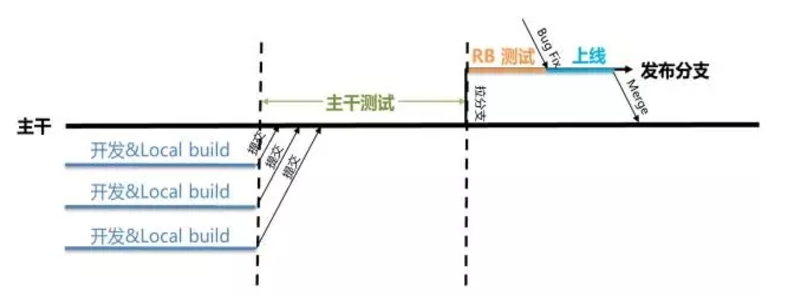
1.基于主干的开发
前面已经介绍过了《持续交付》更倾向使用基于主干的开发模式,所有项目成员把代码都提交到主干上,提交后自动触发持续集成进行验证和快速反馈,通过频繁的集成和验证,在保证质量的同时提升效率。主干开发模式非常强调代码提交习惯,包括频繁、有规律的代码提交(比如每人每天提交一次),而提交前需要进行充分的本地验证和预测试,以保证提交质量,降低污染主干代码的概率。
优点:
相比于分支开发,主干开发模式有很多优势。首先是代码提交到主干,可以做到真正的持续集成,在冲突形成的早期发现和解决问题,避免后期的” 合并地狱”,这样的整体成本才是最低的。
对持续集成来说,具体实施也将会变的非常简单,只需要维护一条 pipeline 交付流水线,通过 git 的 hook 机制,当有新代码提交的时候就会触发 pipeline 的执行并反馈结果,如果有问题代码提交人员必须要实时去解决。
难点:
主干开发模式有很多优势,但具体实施过程中会发现,当一个项目开发者多了以后,如果没有强力的制度约束和相关意识支撑,推动起来会碰到不少的困难,比如:
- 主干上功能开发完成时间有先有后,如果遇到有未完成的功能但又需要发布时,就需要一种方法屏蔽掉未完成功能,才能进行安全的发布
- 主干上功能开发完成后,如果需要比较长的时间进行验收测试,那么此时为了确保发布功能的稳定性且所有功能是经过验证的,可能会限制新功能的提交,有的团队采用的封版、冻结主干的做法就是这种情况,这样的确会影响开发效率
- 如果修改的功能非常复杂,或者要进行架构上的大范围重构,以上问题就更加明显和难以解决了
- 如果团队规模比较大,同时工作在主干上的开发人员比较多,那么冲突的概率会比较大,持续集成的失败率可能比较高
这些问题并不是无解,比如通过功能拆解合理规划需求进行增量开发;通过配置隐藏未完成功能;以微服务的思想对大的架构进行拆分组件,每个组件独立开发和部署等。前提是我们的系统要有良好的架构设计,以及我们的开发者要有良好编码协作习惯。
2.基于分支的开发
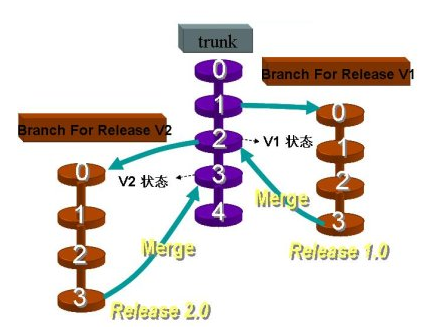
这正是很多团队经常默认使用的模式,具体表现为接到需求后拉出分支,后面的开发都在分支上提交,每个分支生命周期较长,并且可能有多个并行分支,直到快要上线时或者上线后才合并到主干。
优点:
多个功能可以完全并行开发,互不干扰。还可以按每个功能特性拉出分支,那么每次提交都是完整的功能特性,分支划分明确、版本控制的记录也会比较清晰易懂。并且由于不同需求的开发进度不同,可以选择某个先开发完成的功能特性进行合并、发布,而不会被其它分支上未完成的功能特性阻塞。
缺点:
引用电影《无间道》中的一句话,“出来混,总有一天要还的”,因为虽然使用分支暂时隔离了不同功能的代码,但系统的多个功能或者多个组成部分最终还是要集成在一起工作的。如果不同分支代码之间有交互,合并时可能会有大量冲突需要解决。
在实际项目中,进行代码合并时通常很容易出错,解决冲突也非常耗时,特别是到代码合并时基本都已经到了项目后期,经常出现合并错误甚至遗漏合并的问题,对于 QA 来说,每个分支通过测试后,合并代码以后又需要系统的重新测试一次,工作量巨大不说还很容易导致一些合并造成的 bug 遗漏到线上,经历过的同学都曾体会过这种方式的痛苦。
对于持续交付来说,每条分支我们都需要搭建一条完整的 pipeline 与之对应,这意味着需要更多的部署环境和更多的重复测试,在合并代码后所有的过程还需要重新来一遍以避免各种代码合并错误。
3.权衡和建议
在某些情况下,有时迫不得已要采用分支开发的模式,比如并行需求太多且相互干扰,比如开发团队的习惯无法驱动改变,拉出分支其实意味着已经在持续集成/持续交付上做出了妥协,那么我们建议至少要使用一些折中的方案。
- 尽量缩短分支的周期,最长也不要超过迭代周期;
- 每个分支上运行单独的测试流水线,保证质量。虽然这种方式浪费资源,而且其实也没进行” 真正的 “集成;
- 分支只与主干合并代码,分支彼此之间尽量不做合并;
- 分支定期合并主干上的变更。
具体到 Jenkins Pipeline 的实施,个人认为主干开发模式,或者分支比较少的分支开发模式,原来的普通 pipeline 模式已经足够。但如果是并行分支比较多的分支开发模式,以个人实践经验,单条 pipeline 使用时冲突会变的比较严重,虽然 pipeline 也可以通过参数化的方式去适配多个分支使用,但这种方式的缺点是每个分支的结果可视化会变的比较糟糕,这种情况下我们更推荐使用 MultiBranch Pipeline。
MultiBranch Pipeline
前面啰嗦了这么多,终于到了重点要介绍的 multiBranch Pipeline 部分内容,但理解持续交付的分支管理策略确实对我们 pipeline 的具体使用非常重要。
之前已经介绍过了,Pipeline as Code 是 2.0 的精髓所在。multiBranch Pipeline 简单来说,可以理解为是一个项目里所有分支代码 pipeline 的集合。它的使用首先需要在每个分支代码的根目录下存放 Jenkinsfile(Pipeline 的定义文件),我们可以理解下 maven 的 pom.xml 文件,Jenkinsfile 作为 pipeline 的管理文件也需要在源代码中进行直接的配置管理。这就要求 devops 工程师(QA、运维等)首先要有代码库的权限,或者至少赋能给 dev 工程师 jenkinsfile 的设计能力。
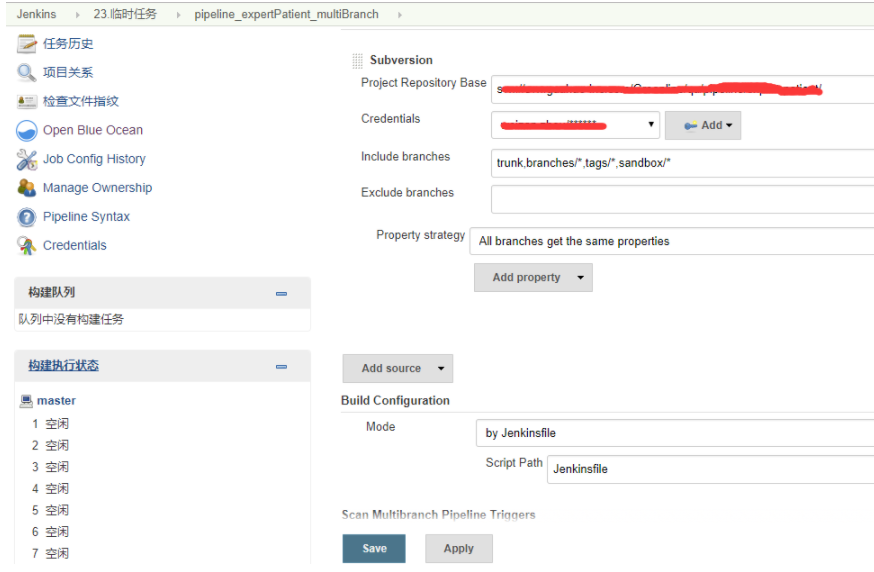
1.新建 multibranch pipeline job
对代码地址和 jenkinsfile 路径进行配置如下
2.自动为每个 branch 生成 job
在 multibranch pipeline job 保存后,jenkins 自动地检查所有的 branch,且自动地为所有的 branch 创建 job,当然前提是存在 jenkinsfile 文件
例如上面的 job,自动地生成了文件夹 pipeline_expertPatient_multiBranch,且在此文件夹下自动地为 trunk 和 branch 生成了 job。如果在代码库上某个 branch 分支被删除,multibranch pipeline 也会自动检测变化并删除相应的 job。
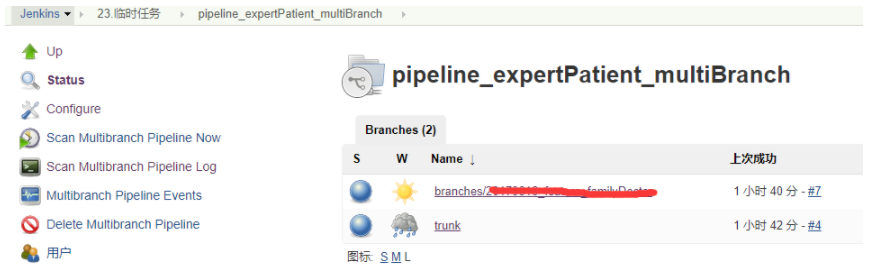
3.Scan Multibranch Pipeline Now
第一次生成 Multibranch Pipeline 时,会自动扫描 pipeline 配置文件并建立相应的 job,后续如果 jenkinsfile 文件有变更,也可以手动触发扫描,日志输出如下
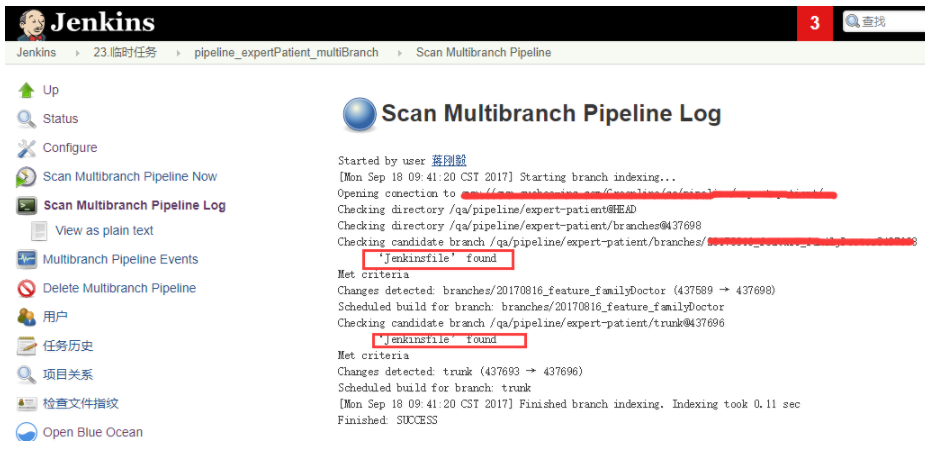
这样一个完整的 MultiBranch Pipeline 就建立完成,你可以根据不同的分支定制不同的 pipeline 策略,当然也可以采用参数化的方式使用通用的 jenkinsfile 文件。
结语
MultiBranch Pipeline 可以理解为是针对某个工程所有分支代码的 pipeline 集合,jenkins 会自动发现源代码中的 jenkinsfile 配置文件生成对应的分支 job。
而 MultiBranch Pipeline 要求 jenkinsfile 配置文件存放在源代码的方式,也是符合 Pipeline as Code 的理念。虽然这也会给一些没有代码提交权限的 devops 工程师带来困扰。