-
**复杂业务流**末端的接口前置数据应该如何准备? at May 03, 2020
自动化的难点就是这个,需要测试接口 8,结果需要把 1-7 的接口都调用一次。然后各种环境问题,各种团队合作的问题,各种不稳定的问题。不是自动化本身有多难,而是你需要把周边的各种事情安排的妥妥帖帖。生活是真艰难。
-
有需要测试兼职的吗? at May 03, 2020
-
[北上杭深] 大厂 招聘 测试开发 at February 06, 2020
-
自动化测试那些事 (一) at February 06, 2020
稍微杠一下,httprunner 和 unittest,pytest 这种其实不是在一个层面的框架,放在一起不合适
-
如何看待领导直接丢过来个系统,没有需求文档、环境搭建文档等,且要求一个月内完成测试! at December 21, 2019
我现在遇到这种情况是没啥好抱怨的,抱怨没用,不如多沟通把文档自己整理出来了,大部分的公司都这样。换公司也是也好不到哪里去。测试的悲剧也在这里,做了很多没人看到的事情,测好了应该的,测不好就是你的问题,要么解决这个问题,要么就换换地方或者只职位。公司大部分人都是开发,开发就是不太想写文档,你要说服大部分人,那很难。
-
一起探讨持续交付的价值 at December 19, 2019
都很好就是公司倒闭了
-
在社区和 github 看了测试平台,都是千篇一律的 curd 结合 appium、selenium、接口。 at November 30, 2019
讨论了这么多 我觉得关键一条 这是测试不是测试工程师这个完全不等同的 现有测试工程师如果不升级 路越来越窄 如果一个团队四个人三个开发 一个测试 那么测试的工作可以悄无声息的可以被三个开发人员平分 说到底那些价值可以不容易呗替代
-
在社区和 github 看了测试平台,都是千篇一律的 curd 结合 appium、selenium、接口。 at November 28, 2019
其实大部分的 app,网站,后台服务等等,也就是这些吧
-
[求助] 使用 poi-4.1.1 写 excel 文件时报异常 NoClassDefFoundError at November 25, 2019
maven pom 文件里面添加 commons-math3 的依赖再看下
-
测试陷阱 2: 永远都在忙碌重要紧急的事情 at October 31, 2019
反正我不觉得反复看了几次语法就算入门了,至于说什么 1 年才能入门我也说不上,我主要意思是就是既然都想提高,又不在提高的方向上投入时间,那么只会越来越焦虑,而不会发生任何变好的情况。
-
win10 质量事件思考 at October 22, 2019
越底层测试越和测试没关系
-
lagou PC 版搜索选项工作经验选择应届后,取消应届后,不能返回原来的工作经验选项,这是个 Bug 还是个需求?欢迎讨论 at October 08, 2019
是的,选了应届毕业生之后就没有工作经验了;产品层面可能也有道理,但是我不太接受的是不能再把工作经验这个选项再恢复了
-
lagou PC 版搜索选项工作经验选择应届后,取消应届后,不能返回原来的工作经验选项,这是个 Bug 还是个需求?欢迎讨论 at October 08, 2019
是的是的,但是就是从逻辑上来说有点奇怪,选了应届之后,就没有工作经验了,也没有办法退回工作经验的选项了。主要还是逻辑上也有道理,但是又有点不完全走的通,有商量的余地,对于测试来说这是会经常发生的事情,所以我觉得讨论讨论
-
以太坊 (Ethereum) 部署私链和合约 at October 07, 2019
阿里也在做区块链?貌似好厉害的
-
以太坊 (Ethereum) 部署私链和合约 at October 07, 2019
开始区块链测试了?技术真是变化太快了
-
关于测试开发的思考 at June 28, 2019
我同意你的看法,能做出来好的测试工具的测试开发水平可能比一般开发还强,好的测试工具就是 ToB 的业务,你想想你要了解你使用的人,都是专家,你能做出让专家满意的东西,你能不强吗。只是大部分老板没有意识到而已。既然工资给不到,那么其实大部分工具质量不高是可以理解的
-
关于测试开发的思考 at June 28, 2019
有人抱怨测试开发没有产出 推进事情我觉得两方面都有原因 需要带动的是代码能力弱一点的测试 但是这个事情有多难 只有做过的人知道 事情大部分不是一方面的问题 但是需要一方面的人负责任 世界就这么运转
-
关于测试开发的思考 at June 28, 2019
我觉得测试开发不纯粹是开发框架的 测试开发测业务 应该是用代码的地方用代码 需要业务的时候用业务知识 需要自动化的时候自动化 代码应该是随手就能写出来 这应该是大部分测试需要达到的水平 可惜现实中没有这么多 测试用例的代码难度没有那么大也没有那么简单 但是往往工作量大 这也就是为什么好多开发不愿意写单测代码也好集成也好的一个很重要原因 解决工作量大的问题同时还要解决欠债太多问题 这个真不是一般测试开发搞得定的 无解 混日子 工资到手就可以
-
在 DevOps 蓬勃发展的时代,软件测试还有没有价值? at June 28, 2019
讨论价值没意义 有意义的是讨论价值多少
-
用了那么多 UI 自动化框架,为什么没有人尝试直接用 js 来做呢? at April 29, 2019
个人觉得这个做法是可行的.
像 https://www.cypress.io/ 这个 UI 测试的,其实用在本机测试使用 Mock 会有比较好的效果.我自己个人的感受,看了 angular 或者 vue 这种 model 和 view 自动绑定的前端,其实在运行层上面完全可以进行 model 和 view 绑定。
上面有点玄乎,举个例子来说:- 页面的某个输入框 model 的名字是 name, 那么你的测试数据里面如果有一个属性也是 name, 那么默认应该就是这个属性 name 的值就应该输入到这个 model 名字是 name 的框中
- 大部分控件的默认操作就一种,输入框就是 input
- 结合以上两点,在运行 UI 测试的时候也可以做到 model 和 view 绑定,已 java 为例子,给一个对象实例,他有变量名,有变量的值, 通过这个变量名可以找到这个变量名在 page 中定义的定位元素,就可以直接操作了, 最后的测试用例其实就是变成类似:
login(String processName,List<Pages> pages, TestData data)这个样子了. data 中包含所有需要测试的数据,变量名自动到 Page 里面去寻找这个流程需要的页面元素,selenium 里面的常用操作都可以在写测试用例的时候都需要知道,只要知道数据是什么就可以了。
可以参考老帖子: https://testerhome.com/topics/2788
这个就是当时看了 angular 想到的, 甚至通过解析页面元素 model 这样的东西,可以把生成一部分 PageObject 类。然后在反射关联页面的 model 和测试的数据,页面,定位,数据都可以分开,model 对业务系统来说是稳定的,页面元素变来变去,只要改 pageobject 就可以,页面操作什么都可以不用改,因为大部分都使用默认操作,默认操作封装在框架就好。最后只能说没有什么用,因为其实大部分的测试越封装,效果就越不好,太多的概念分层都不如直接写 selenium 原生的 api 好用,什么稳定不稳定,自己没试过怎么有感受内,类似于在 json 对象里面找一个元素,如果在学习了一段时间后,还是要花很长时间才会用,什么框架都不管用。
具体的是可以参考: https://github.com/ideasfortester/mixed-first
还有一点其实个人觉得如果有类似于的埋点系统的话,完全可以把页面操作的所有动作都记录下来,直接通过埋点系统来完成录制回放。不过不好的地方就是这些都变成开发的事情了, 要测试做什么。 所以我也被 fire 了。 嗨找工作真难!
-
大家对功能分批提测有什么看法? at January 19, 2019
分批提测理论上是可以提高交付速度分批提测 分批验证 分批 UAT 提高并行度 但是需要需求分解好 同时沟通频率也加大 测试工作量是提高了的 环境问题吗 能做的还是需要基础设施能力 挑战肯定是加大了 能不能快只能说看能力 都说不准 如果马上试肯定会有点混乱的
-
对于一个日活量 20 万的接口,应该怎么做压测 at January 18, 2019
首先明确一下开户接口调用的时间分布 最高一段时间会有多少人 然后转换到一秒会有多少 tps 给这个值 *2 就当你的目标 然后看看用户行为 会有同时注册这种情况吗如果有就要增加一个抢注册这样场景 并发需要设置集合点 其他可以再看看会有持续比较长时间一值有人注册的场景 可以模拟这个场景看系统较长时间运行情况
以上纯属拍脑袋
-
[OPPO 深圳] 19年-全新岗位招聘--测试开发工程师 / 测试开发架构师 / 平台开发工程师 [以下岗位长期有效] at January 08, 2019
又精通分布式又精通 android 感觉还是个人吗
-
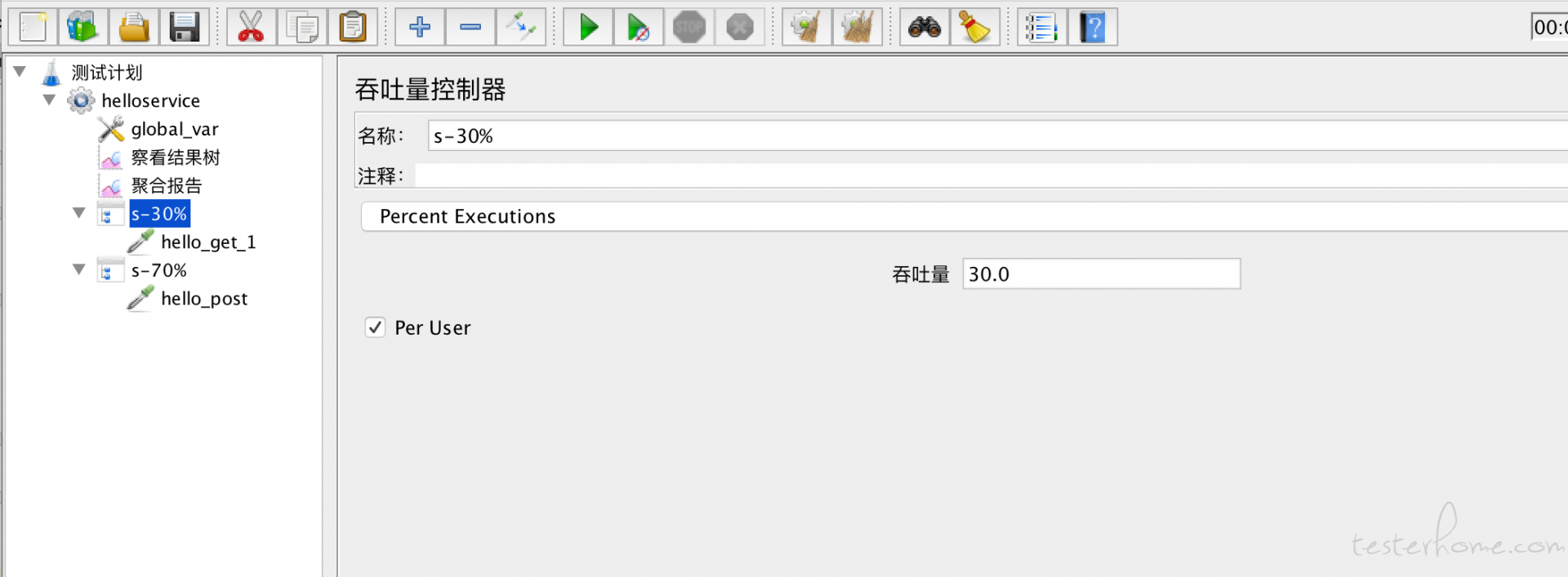
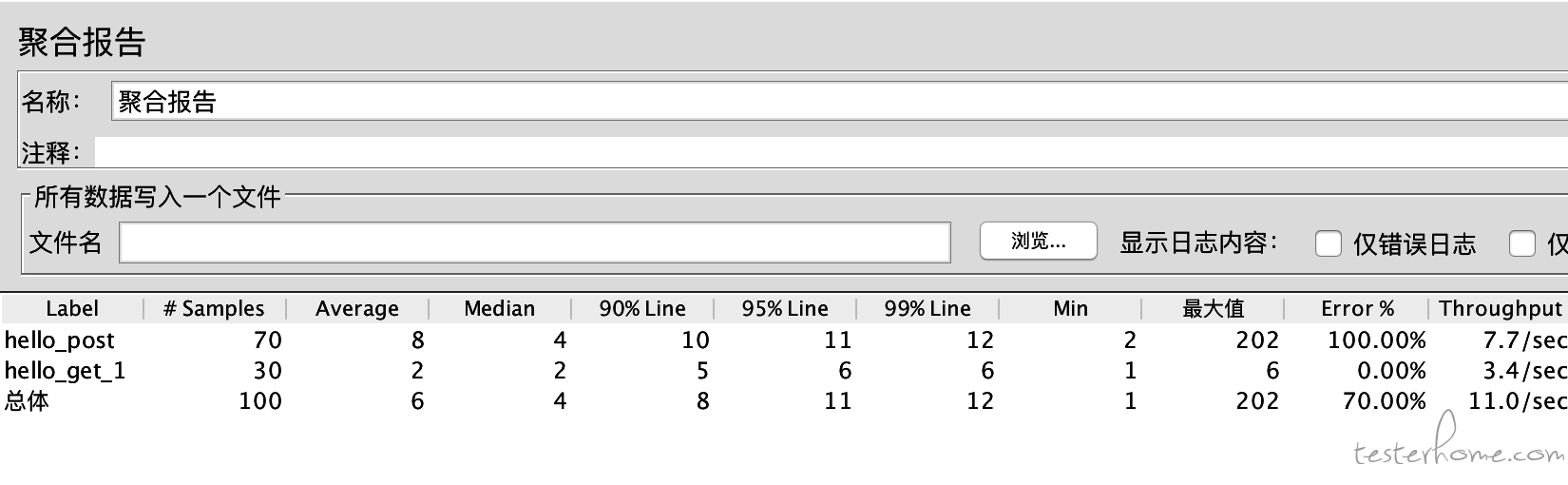
jmeter 测试混合场景如何控制业务比例 at December 26, 2018
使用吞吐量控制器也可以做到:
-
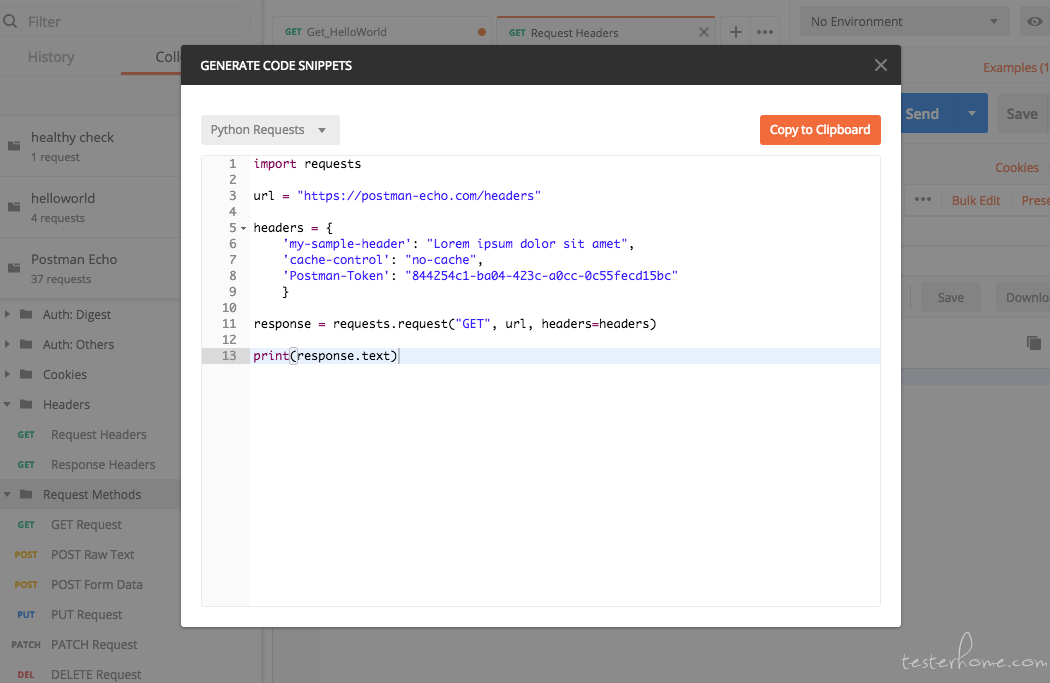
学习接口自动化测试时的疑问 at December 25, 2018
一个方便的办法就是:用 postman,里面 postman echo 基本例子都有
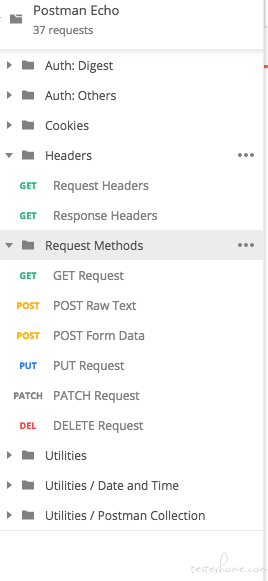
然后查看 postman 的 code 生成: