新手
mixure (hellohell)
第 19162 位会员 / 2017-07-13
14 篇帖子 • 329 条回帖
-
app 自动化测试开发打包好后自动运行 at 2018年05月14日
下载, curl -O 难道不能用么
-
新手测试开发困惑 at 2018年05月12日
- 如果你是手工测试工程师,你不发愁没事干,因为领导总会给你分活儿;
- 如果你是测开/自动化,同时你的领导是纯粹管理型的,要么你会沦落成手工测试,要不你没活儿干,因为 ta 不知道你能干啥, 最后连绩效你都不知道怎么填.这就是部分第二类人的现状.
-
在 testerhome 发话题,代码怎么配色的 at 2018年05月08日
这 markdown 是够混乱的
-
求 CPU 占有率、流量、电量等专项测试的教程 at 2018年05月08日
帖子是真多,我是没能力辨识到底说的对还是不对
-
兼容性测试的问题 at 2018年05月07日
你们如此多的机型都不知道咋搞,那我们就跟没法活了;
只能放弃完美,黑下心来测试了 -
兼容性测试的问题 at 2018年05月07日
- 在 app 上埋点,看看你的产品在用户设备上的分布情况
- 然后是厂商,分辨率,系统版本什么的
- 不过说实在的,这就是痛点:确实找不到一个好的理由,在不购买大量机型的情况下,说明使用云测是靠谱还是不靠谱的.千万别看广告. 大厂有人有钱,他们用的方法不一定能套在一般公司上.
- bug 就像生活,好多情况无法预测,当然有些可以看出苗头,可惜有人就是死矫情;
-
python 多进程编程遇到的问题,请高手赐教 at 2018年05月07日
还有如此骚操作

-
基于 Appium 的 App UI 遍历 & Monkey 工具 (支持操作步骤回放) at 2018年05月06日
懂了;靴靴;
-
基于 Appium 的 App UI 遍历 & Monkey 工具 (支持操作步骤回放) at 2018年05月06日
- 支持这个工具
- 对这些不是太了解,工具是否有可以定制
预期结果?还是遍历后不 crash,就认为达到测试目的了? - ps: 顺便吐槽下,leader 说不做检查点的自动化没意义,只能呵呵, 真是头发不长,见识也不长.
-
python 多进程编程遇到的问题,请高手赐教 at 2018年05月05日
- 楼上说的对
- 那个 continue 有啥用,for 循环的最后一句
-
如何做到快捷查看 linux 环境中的多个实时日志? at 2018年05月05日
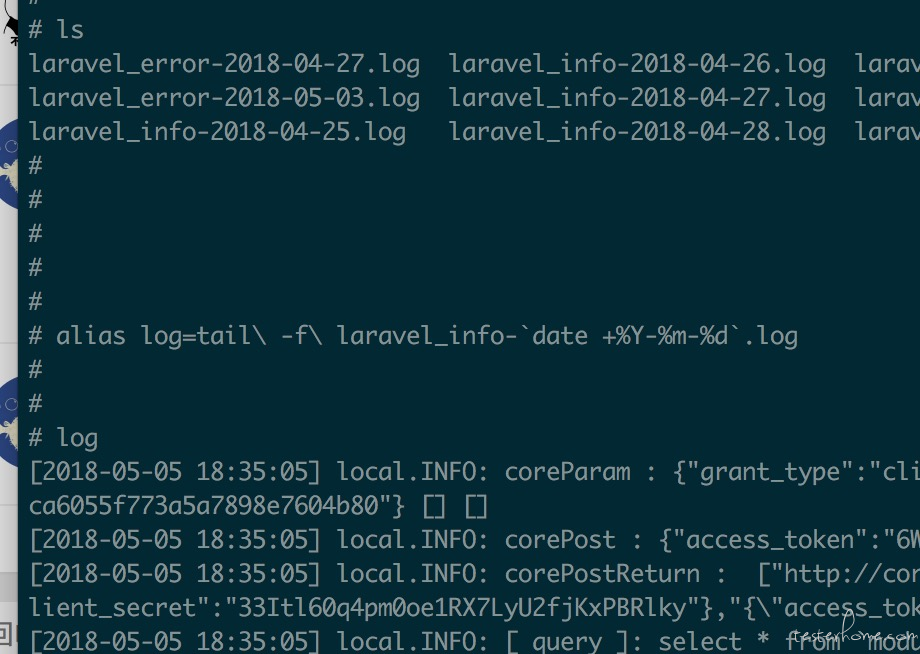
-
新人问问。。python+requests 的问题,求大佬帮忙。。 at 2018年05月04日
其实我也比较懵逼
看了看帖子,开始有一个地方没太想通,requests 在 post 提交 json 的时候不是该
requests.post(url,json='xxx',header={'Content-Type': "application/json"}怎么
requests.post(url,data='xxx',header={'Content-Type': "application/json"}也可以?当然 data 和 json 的实参类型不一样;
然后我做了个实验
去 github 上 clone requests 模块代码,clone 到 Download 目录;
去 requests-master/requests/adapters.py 第 435 行添加了
print request.body
ta 就变成了这样
if not chunked: print request.body # 这是我添加的 resp = conn.urlopen( method=request.method, url=url, body=request.body, headers=request.headers, redirect=False, assert_same_host=False, preload_content=False, decode_content=False, retries=self.max_retries, timeout=timeout )3.然后写了代码
import sys,os sys.path[0:0]=[os.path.expanduser('~/Downloads/requests-master/')] print sys.path[0] import requests print requests.__file__ url = "http://ivt3.hschefu.com:9199/login" headers = { 'Content-Type': "application/json", } # 第一种方式 requests.request("POST", url, json={"data": {"password": "12345678", "username": "xiangjin"} }, headers=headers) # 第二种方式 payload = "{\"data\": {\"password\": \"12345678\",\"username\": \"xiangjin\"}}" requests.request("POST", url, data=payload, headers=headers) # 第三种方式 requests.request("POST", url, data=payload)输出是
/Users/yeap/Downloads/requests-master/ /Users/yeap/Downloads/requests-master/requests/__init__.pyc {"data": {"username": "xiangjin", "password": "12345678"}} {"data": {"password": "12345678","username": "xiangjin"}} {"data": {"password": "12345678","username": "xiangjin"}}所以基本断定这三种写法的效果是一样的,当然我推荐第一种;
至今仍看不懂 requests,我不会 py
然后连 charles 代理,一样的请求,只是第三种没有 headers 字段;
-
新人问问。。python+requests 的问题,求大佬帮忙。。 at 2018年05月04日
- Postman 使用小技巧 - 用 Postman 生成 Request 代码
- 失眠症比 postman ui 简单的多
-
selenium+PIL+tesseract 实现 web 简单验证码识别 at 2018年05月03日
验证码图片获取,有的时候需要加上 header,cookie,克服 CSRF
import requests # 获取的是百度搜索页面上图标 r=requests.get('http://www.baidu.com/img/bd_logo1.png?where=super') import io i=io.BytesIO() i.write(r.content) from PIL import Image image=Image.open(i) image.save('captchaCode.png') -
selenium+PIL+tesseract 实现 web 简单验证码识别 at 2018年05月02日
取验证码截图那是一种可推荐的方法;
-
接口测试的响应结果是一样的,但是触发原因是不一样的。怎么确定这个响应结果是由于原因 A 引起的,而不是 B at 2018年05月02日
那就是用例设计的太粗.
- rd 告知你,先做 xxx 判断,后做 xxx 判断
- 前端负责哪部分判断, 后端负责哪部分判断;
- prd 上写着:发生 xx 问题,给予用户 xxx 提示;然后报错后已填写数据不丢失不需要用户重新填写
以上都在幻想中出现
-
接口测试的响应结果是一样的,但是触发原因是不一样的。怎么确定这个响应结果是由于原因 A 引起的,而不是 B at 2018年05月02日
另外对于失败性测试,一个用例应该只携带一个导致失败的因素,比如上传图片,你非要上传个 超过最大允许大小的被破坏的把后缀改成 txt 的图片文件 ...
-
接口测试的响应结果是一样的,但是触发原因是不一样的。怎么确定这个响应结果是由于原因 A 引起的,而不是 B at 2018年05月02日
看后台日志;
接口测试是测试环节,不看日志,不看库;基本瞎测 -
每个测试用例过后要不要关闭浏览器 at 2018年05月02日
原则上:
1.每个用例是独立场景,要关闭浏览器;
事实上:
取决你的领导 -
来练练手!在一个 html 页面中截取一段字符串 at 2018年04月27日
-
来练练手!在一个 html 页面中截取一段字符串 at 2018年04月26日
用//定义正则的都是大神,像 10 楼
-
来练练手!在一个 html 页面中截取一段字符串 at 2018年04月26日
s='''<html> <input type="hidden" name="_csrf" value="12345678-1234-1234-1234-123456781234" /> </html> ''' import re print re.search(r'name="_csrf" value="(.+)"',s).group(1) -
# 每日一道面试题 # 如何判断一个字符串是回文字符串,并对你的写出的方法进行测试 at 2018年04月26日
又改的骚了点
def test(str_): def test_(str_): h,str_,t=str_[0],str_[1:-1],str_[-1] return True if len(str_)==0 else (False if h!=t else test_(str_)) return False if len(str_)==1 else test_(str_) -
# 每日一道面试题 # 如何判断一个字符串是回文字符串,并对你的写出的方法进行测试 at 2018年04月26日
import timeit print timeit.repeat(setup="from __main__ import test",stmt='test("abba")') -
# 每日一道面试题 # 如何判断一个字符串是回文字符串,并对你的写出的方法进行测试 at 2018年04月26日
我也不想写成这么骚的操作
def test(str_): def test_(str_): if len(str_)==0:return True h,str_,t=str_[0],str_[1:-1],str_[-1] return False if h!=t else test_(str_) return False if len(str_)==1 else test_(str_) print test('a') print test('aBa') print test('abba')