-
最近用 selenium 写 ui 自动化 at 2022年08月30日
常见的 PO 并没有变,组件化只是把元素定位和操作这块单独提出来做了抽象封装,以此提高组件的复用性,易用性,然后在 PO 里面就不再直接操作标签,而是通过组件进行交互。
我之前在飞哥的帖子下面也有做新的回复,写了一些我做的案例,可以看一下。UI 自动化的分层设计,然后 renorex 的组件化思路是对的,从人的角度来讲,我们看到的确实是一个个组件,从开发角度讲,现在前端和客户端也都是组件式开发,selenium 早期的 locator 已经不适用了,组件化定位和操作以后肯定会像 PO 一样成为 UI 自动化规范。
by the way,我已经转游戏客户端开发了,以后在测试方向的研究会少很多,现在也还只是出于兴趣在了解和探讨,不过技术和开发思想都是相通的,以后有想到什么好的方法和方案有利于测试的,到时候也会到 testerhome 来聊聊。
-
最近用 selenium 写 ui 自动化 at 2022年08月30日
看了下官网介绍,这个工具在 web 测试方面底层驱动应该也是 selenium,定位的话好像自己整合了一个 RanoreXPath 来适配多端。除此之外有整合组件化的概念,这也是我第一次专门看到一个工具在 UI 方面做组件化,和我做组件化的思路是完全一样的。然后有自己定义 action 来整合一些常用的方法,最后做了录制。虽说录制是快速做到 60,70 分,但底层做的工作还是让这个工具拥有定制化然后达到 80,90 分的能力。
仔细看了下这个工具支持的概念和功能,还是不错的,我一个测开做的话可能至少要差不多半年时间才能做出类似的东西还不一定更好用。如果是到一个新团队然后要推 UI 自动化,我可能会更多调研之后尝试推这个工具。
-
最近用 selenium 写 ui 自动化 at 2022年08月30日
使用层级定位和一些 xpath 的写法,如果楼主能看明白的话,应该是可以解决定位不了的问题。
def _get_options(self, layer: int) -> list[WebElement]: # 普通下拉 xpath = f"//div[contains(@class,'el-popper') and not(contains(@style,'none'))]/descendant::ul[{layer + 1}]" # 添加组合商品等待下拉的按钮,会使用下面的样式 xpath += "|//ul[contains(@class,'el-popper') and not(contains(@style,'none'))]" element = self._driver.find_element(By.XPATH, xpath) return element.find_elements(By.XPATH, ".//li") -
最近用 selenium 写 ui 自动化 at 2022年08月30日
用 selenium 的话,应该是 web 自动化吧,selenium 是最优解,所有网页基本都是可以定位和操作的,如果做不到,说明自己理解还不够深。没事可以多看看 xpath 和 selenium 官方文档。
另外前端组件化之后,大多组件确实只能靠 text 定位,所以我现在大多都是用 text 定位,还可以使用层级关系,先找到一个元素,然后通过元素找下级元素,和轴定位还不太一样。
这里贴一个我写的 xpath:
class Button(ClickMixin): def __init__(self, text: str): # 把当前节点的文本去除前后空格后,替换中间空格,然后比较文本 # template = ".//{0}[translate(normalize-space(),' ','')='{1}']" # 暂时只开放button和a标签,避免匹配太多标签导致混乱 a = f".//a[translate(normalize-space(),' ','')='{text}']" button = f".//button[translate(normalize-space(),' ','')='{text}']" # 支持带cursor css类的span标签 span = f".//span[translate(normalize-space(),' ','')='{text}']" # vue表格操作栏的按钮 table_btn = f".//div[.='{text}' and @class='table-handleBtn']" xpath = f"{a}|{button}|{span}|{table_btn}" super().__init__(xpath=xpath) -
辞职后发现连面试的机会都没有 at 2022年08月30日
说是像培训出来的,主要是工作经历有点偏门,农业管理平台,音乐下载器等等,一看就是小公司,产品线比较混乱,这样的团队一般对测试流程也不太重视。
我说的专业理论和深度思考,其实是要求个人要有对行业和技能的理解,归纳能力强。

例如写工作流程这段,需求评审,用例评审,提交 bug,bug 验收等等,我只能看出来候选人知道这些流程,但并不一定知道为什么要有这些流程和怎么去改进流程,把每个环节做得更好。另外随便写点,比如学习平台项目经历这段,我可能会这样写:
恒智 AI 学习平台
平台分三种角色,管理员、讲师、学员,测试内容涉及管理员侧的账号管理、课程管理、学校信息管理,讲师课程管理,发布学习任务,实时讲课,课后问答等功能,学生端课程学习、在线编程,查看学习进度,报告等功能。项目期间能够从多角度,用户需求出发,主动及时发现问题,提升体验,保障产品质量,遇到问题能够认真分析问题,和开发高效沟通并协力解决问题,提高产品交付质量和效率。
-
辞职后发现连面试的机会都没有 at 2022年08月29日
简历给人的感觉像是培训出来伪造的经历,工作经历偏门,业务梳理不清晰,技能太浅显表面,感觉缺乏专业的理论和深度思考。
-
UI 自动化中的分层设计 at 2022年08月24日
时隔大半年,自己在这中间也在公司实践 UI 自动化,结合自己的经验和网上的案例与理念,造了一些轮子。
一、组件化:
class Page(metaclass=ABCMeta): def __init__(self, driver: Chrome): self._driver = driver # 每一个页面都有独立的组件,所以page方法不能覆盖,需要全部调用一遍,这里是遍历继承链,把所有父类和本身的page方法都执行一遍 for base in self.__class__.__mro__[::-1]: if issubclass(base, Page): base.__page__(self) @abstractmethod def __page__(self): pass # 使用self.btn_submit = Element()时调用,注入driver到component def __setattr__(self, name, component): if issubclass(component.__class__, Component): component.set(driver=self._driver) super().__setattr__(name, component) class LoginPage(Page): def __page__(self): self._input_username = Input("请输入用户名") self._input_password = Input("请输入登录密码") self._btn_login = Button("登录") def login(self, username: str = "admin", password: str = "admin"): self._input_username.send_keys(username) self._input_password.send_keys(password) self._btn_login.click() # 使用方式 # LoginPage(driver).login()实际项目中封装的组件很多,除输入框、按钮外、还有日期选择,日期范围选择、表格、下拉等,适配 element、antd 等各个前端框架。组件化的核心理念在于类内部存储定位方式,使用惰性加载的方式后置传 driver,执行操作时动态查找元素,还用到了 xpath 的或条件等增加组件的兼容性。
二、链式调用:
这个其实使用范围很广了,但我看很多人写 UI 自动化还是没按这个理念去设计,所以还是贴一下,可以简化代码和增加可读性。# 链式调用示例 page = ProductIndexPage(driver) ( page.navigate_to(PriceCalculatorPage) .add_product_info("电脑整机", "笔记本", "戴尔", "E7240") .choose_product_level("A") .choose_product_config({"CPU": "i7 8代", "内存": "4G"}) .choose_product_property() .choose_other_property(is_new=True, is_return_after_rental=True, use_channel=0) .fill_in_price_valid_date(5000, 5000, False, "厂商", (3, 7, "天")) .fill_in_residual_value(5000) .compute() .save() ) # 方法内部实现 class PriceCalculatorPage(ProductIndexPage): def choose_product_level(self, level: str): """选择商品等级 Args: level: A、B、C """ self._select_product_level.select_by_text(level) return self def compute(self): """点击计算""" self._btn_compute.click(delay=1) self.scroll_to_end() return self -
为啥给函数赋值时,可以传入它的内部函数里? at 2022年03月21日
func1 最后一行是 return func2,func2 不加括号就是返回 func2 这个函数本体,所以执行 func3 = func1(1) 的时候相当于 func3 = func2,再执行 func3(2) 时等同于执行 func2(2)
python 里函数也是对象,可以用来作为参数传递和赋值,这里贴一个高阶函数的教程https://www.liaoxuefeng.com/wiki/1016959663602400/1017328525009056
-
网易有道 UI 自动化探索与落地方案 at 2022年02月26日
之前也见过一些人在做录制回放和云真机平台的集成,确实降低了使用要求和学习成本,作者能够完成这样一个平台并落地,发文章出来,想来也应该是有一定成效,但还是有一些疑问希望提出来大家共同探讨。
UI 通常包含多个部分的内容,例如样式、文案、动态内容和用户状态,使用截图对比的方式会不会 UI 稍微一变动就会报错,缺少容错性;截图对比具体是靠什么指标去判断断言是否通过呢,相似度么,会有一个绝对差值么。
如果一条用例中有一小部分改动了,这个时候怎样去维护用例呢,修改 solopi 指令不能达到模拟手动操作的效果会需要重新录制脚本么。
用截图对比和录制的方式,可以做到兼容性测试么,录制的用例能否覆盖多个主流机型。
开发这样一个 UI 自动化平台大概需要多少人天
-
请教一个元类使用的问题? at 2022年02月18日
同楼上,楼主在避免处理魔术方法时把带
__的方法都漏掉了,漏掉了__classcell__,所以报 DeprecationWarning,高版本 python 应该会报 RuntimeError,漏掉了__init__,类创建后默认使用了无参初始化方法,所以报 MetaClassTest() takes no argumentsclass LowerAttrMetaClass_4(type): def __new__(mcs, name, bases, attr): attr = {key if key[:2] == "__" else key.lower(): value for key, value in attr.items()} return type.__new__(mcs, name, bases, attr) class MetaClassTest(metaclass=LowerAttrMetaClass_4): Say = "hello world" def __init__(self, name, age): self.name = name self.age = age def Run(self): print("MetaClassTest run method") tmp_obj = MetaClassTest(name="zzz", age=20) tmp_obj.run() # >>> # MetaClassTest run method -
急!!!测试一个页面时一定要以另一个页面为前提,测试类该怎么写?????? at 2022年02月14日
- 最关键的问题在于不应该把进入 home page 和 rgbcw page 的方法写在 setup class,rgbcw 页面会覆盖 home page
- 测试用例应该职责分离,test_in_contexts 和 test_in_rgbcw_page 这两个依赖 home page 的用例不应该出现 TestRgbcw 中,而实际应该出现在 TestHomePage 中,把 self.home_page 和两条 home page 的用例移除掉,TestRgbcw 应该是可以跑的。
- 最好每条测试用例都环境隔离,即一个类下面每条 case 的初始页面应该是一样的,每条用例执行完后可以回到初始页面或者重新加载页面。
-
pytest 怎么异步执行用例呢 at 2022年01月26日
- 可以安装 pytest-asyncio 插件,安装插件后有两种方式运行异步函数,①使用 pytest.mark.asyncio 标记测试用例,②配置文件里写 asyncio_mode = auto,pytest 会自动识别异步函数然后用异步的方式执行。
- 加了异步插件后,不影响之前的同步测试用例和 fixture,如果需要使用异步 fixture,可以加@pytest_asyncio.fixture
- pytest-asyncio 插件原理上是把异步协程封装成同步函数,只是给用例执行套了一层壳,原则上不影响 pytest 原有功能和其他插件
- 异步协程只能提高并发量,并不能减少网络 io 时间,而 pytest 是按顺序运行测试用例的,所以使用异步并不能减少测试的执行时间。
-
分享一下 xmind 转化测试用例工具的思路和收获 at 2022年01月26日
xmind 本质上来讲是一个多叉树数据结构,而测试用例算是一个数据类,这中间的转化过程主要分为两步:
- 如何对树的所有节点进行归类 (辨别它们归属于同一条 case)
- 如何对归类后的数据进行职能匹配 (识别哪些是标题信息、步骤、预期结果、辅助信息) 简单的解析方式是把一条路径解析成一条 case(对应归类),通过固定路径上节点的 index 来匹配职能 (对应匹配)
您的问题点在于:
- 贴图片、代码、测试思路 => 扩充了节点的职能和数据类型,从编程角度来讲算是增加了测试用例数据类的字段和支持非文本节点解析,难度并不高。
- 由扩充节点引发了第二个问题,需求、技术实现、测试思路等辅助信息 (细节) 可能位置相对分散,不容易固定,及如何对这些节点进行归类会相对复杂一点,但我相信一定是有规律可循,您也可以相对制定一些使用规则来方便分类这些信息,最简单的方式是打标记。
规范不是为了限制 xmind 和使用人原有的能力,而是为了方便抽离转化的普遍规律以及统一使用人的认知和习惯。
综上,您目前的问题虽说增加了归类和匹配的复杂度,但是并没有超出转化模型的能力范围,是完全能够解决的,编程是把抽象的逻辑信息化,在用例转化这个问题上,只要您能看懂文档 (更希望团队的所有人都能看懂),计算机也就能看懂、识别、转化,并不存在特别的限制。
-
分享一下 xmind 转化测试用例工具的思路和收获 at 2022年01月25日
首先讲讲 xmind 的优点,利于发散,快捷键生成不同节点比 excel 等编辑更顺畅,格式简单且方便收折...总体来讲编写和阅读体验会比传统的 excel 或者在线编辑更好,这个没什么疑问,所以 xmind 是首选。=> 一定要用 xmind。
关于强格式规范,虽说有固定解析规则,但解析规则其实并不多,因为测试用例核心要素本就不多,迭代名称取 root 节点,用例标题按照中间的路径生成,倒数两个节点解析为操作步骤、预期结果,比起以往其实只多了一个预期结果。大部分人不喜欢写预期结果,而不喜欢写预期结果的原因在于结果一般是常识性问题,所以预期结果不复杂时可以写得很简单 (例如 “执行成功”,“数据展示 ok”),当然前提是操作步骤和预期结果等算是常识时才尽量精简,如果复杂的话,还是写得准确些更好。说起是规范,但更多的是约定大于配置,这些约定基本是符合人的思考方式和常识的,并不是强制制定一个规范而让大家都来遵守。=> 规则不多,且符合常识和 xmind 使用习惯,推行时学习成本很低。
从规范上来讲,争议最大的点应该是操作步骤和预期结果是否应该写得很详细以及重复的内容是否应该写几遍,关于这两点,①有操作步骤和预期结果应该是下限,写得完整且准确应该是上限。每一个有追求的测试人员都应该守住下限,提高上限。测试用例是需要评审的,需要用于开发自测,产品验收的,需要后人接手的,如果没有下限,将会是灾难。②重复内容可使用父节点和概要归纳为一个节点,相对减少重复编写的内容。=> 问题看似很难,实际不难。
关于接受度,我个人使用上来讲非常能够接受,因为和我之前的编写习惯基本一致,反而因为规范,我写的用例比之前更加清晰明了;其他人至少基本没有不能接受的,也有一部分人觉得现在细节还不够,希望再增加一些规则 (例如优先级、编写人) => 基于上面的原因,目前接受度还行。
贴一份最近写的完全符合解析规则的用例吧,虽说内容相对简单,但是书写思路和复杂用例是一样的,用例编写难在设计,书写反而是简单的 (类似编程)。
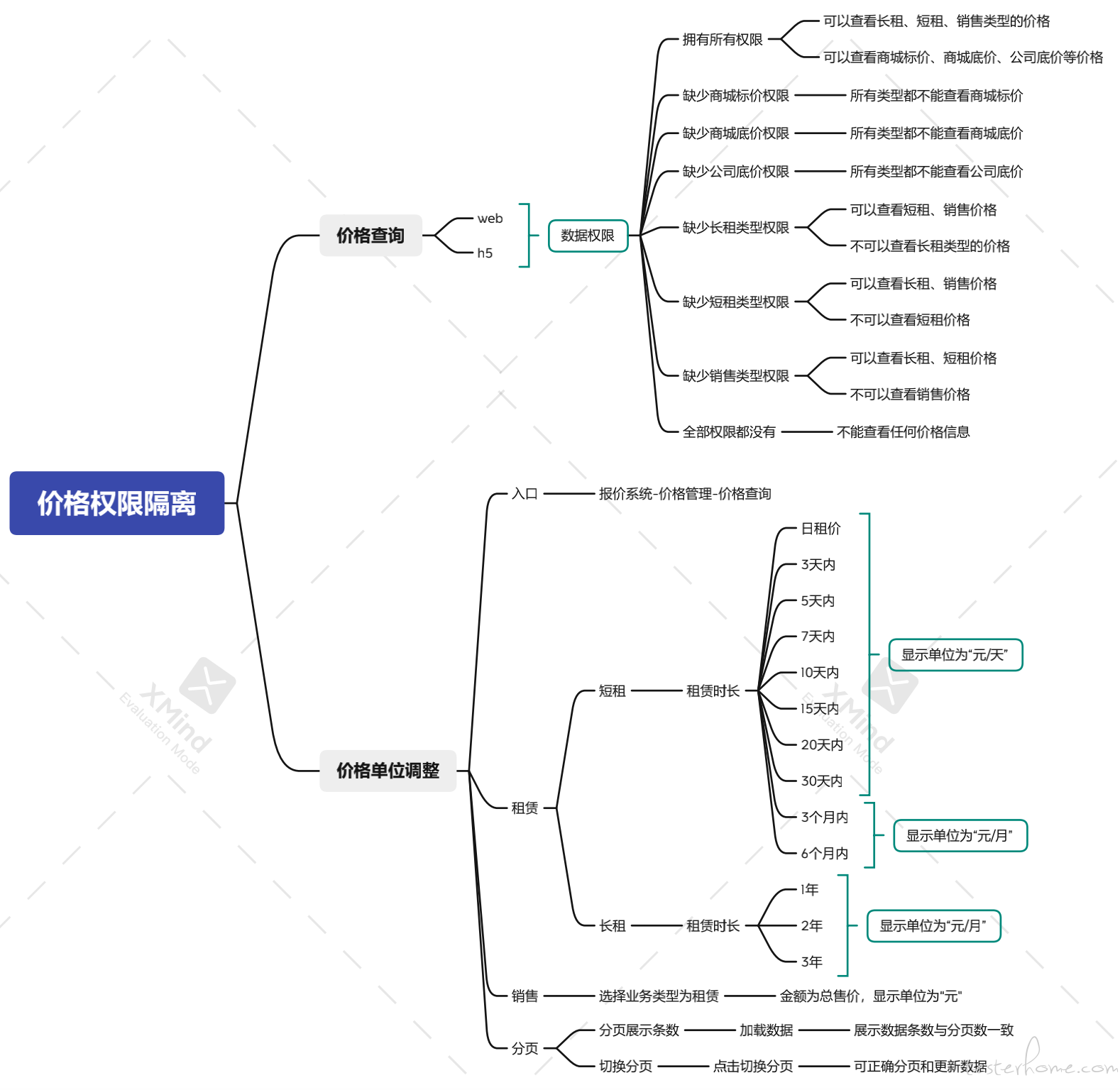
-
测试开发之路—大厂工作四年的感悟 at 2021年12月06日
现状和道理很多人都或多或少有感触,关键还是要如何去破局,转行转岗就不说了,就说说怎么在这条路坚持下去。
职业发展往上走,都是需要综合素质和影响力的,看似瓶颈,但实际上能做的还有很多。测开和开发、产品等岗位本质上都是一样的,运用自己的知识、经验,提供交付能力,只是侧重点略微不同而已。说点实际的吧,我个人的话是预期在未来往两个方向努力:
- 个人能力,提升开发、产品体系、测试经验总结、沉淀
- 建立体系的能力,包括业务测试、自动化、效能
瓶颈归瓶颈,真正遇到瓶颈的人,哪怕晋升再难,实际过得也已经很不错了,慢慢沉淀呗,总是有各个方面需要提升的。另外真有其他打算,也可以换条赛道。
-
今天来小水一篇 - 面试当中经常会考的算法题吧 at 2021年12月02日
这道题只是一道简单的字符串题,一个遍历就搞定,不涉及动态规划。具体的动态规划可以搜一下动态规划标签的题
-
求助:请问 macbookair m1 8+256 能满足测开的工作需要吗? at 2021年12月02日
我看了下内存占用,开 IJ WS PC DG 四个 IDE+chrome 几个网页 + 一个通讯软件的情况下就占用 16G 了,8G 不够用的
-
我觉得我还可以再抢救一下 - 继续学习无敌哥的装饰器系列 at 2021年11月30日
我每天正事不干,光琢磨着怎么炫技去了

正常项目里面我可能会分成两个装饰器去写,尽量避免不同类型的入参和出参 -
我觉得我还可以再抢救一下 - 继续学习无敌哥的装饰器系列 at 2021年11月30日
看见 python 代码,手痒,用类的实现方式也写了一个玩玩
class loop: def __init__(self, times): self.func = times if callable(times) else None self.times = times if isinstance(times, int) else 5 def __call__(self, *args, **kwargs): if self.func is None: self.func = args[0] return self.__call__ for i in range(self.times): self.func(*args, **kwargs) print(f"运行的第{i + 1}次") -
请问下大家在做自动化测试的时候有遇到需要测试电影院选座的场景吗?请教下都是怎么解决的啊 at 2021年11月29日
这种情况我个人能想到的就还是多模板匹配了,个人比较擅长用图像识别的方式做 UI 自动化。
- 把不同座位的图截下来
- 遍历座位模板,多模板匹配,找出图中不同座位的分布信息
组合不同座位的分布信息,就可以得到上面我说的整体座位信息矩阵。分类的话就是按模板来的,匹配什么模板,就对应什么分类信息
涉及坐标变化,通常坐标变化都是有规律的,操作完之后记录整体的坐标变化量或者复位之后再继续操作也行。
可能还涉及不同设备的兼容性问题 (用图像识别都会遇到这个问题),先搞定上面的问题再看吧
这个方案能解决问题,就是需要对图像处理和识别比较熟练。
-
请问下大家在做自动化测试的时候有遇到需要测试电影院选座的场景吗?请教下都是怎么解决的啊 at 2021年11月29日
突然想到自绘的话也是从后端接口拿的数据,可以先请求后端座次信息接口,再计算对应坐标点,通过坐标的方式操作控件。
-
请问下大家在做自动化测试的时候有遇到需要测试电影院选座的场景吗?请教下都是怎么解决的啊 at 2021年11月29日
问题的核心还是在于拿不到控件信息吧,用图像识别的多模板匹配是可以做到获取控件信息的。
只要实现这样一个函数,就可以解决问题,
输入:座位截图
输出:座位信息矩阵
[
[Seat(), Seat(), Seat(), Seat(), Seat()],
[Seat(), Seat(), Seat(), Seat(), Seat()],
[Seat(), Seat(), Seat(), Seat(), Seat()],
[Seat(), Seat(), Seat(), Seat(), Seat()],
]
Seat 类里面包含了座位的是否可选、价格、类型等信息 -
接口间参数传递的一种解决方案 at 2021年11月29日
资源池的创建和销毁主要是靠框架维护,按任务隔离,每个任务都给一个 id,在任务执行完 (或执行异常) 时清掉该任务创建的资源。
我的场景还不太一样,最初的痛点是经常会按不同的维度去划分服务,有时按系统分,有时按场景分,有时又按业务领域分,但是他们的一些基础依赖 (例如各个系统的登录、数据库连接等等) 又是会有重叠的,每个服务都自己创建一遍资源太浪费,每个资源都自己维持一个单例或者资源池又可能会受不同任务的并发影响,索性建立了一个按任务隔离的上下文 + 资源管理池。
接口间这个数据传参我倒没有像楼主这样按 key、value 去划分,通常粒度控制在 DTO(对象,字典) 范围,我司的跨接口或跨系统传参经常都是按对象去传,比如一个订单要填地址信息,这个地址信息通常不是单个字段,而是包含姓名、电话、地址等多个字段的集合,我从获取地址信息的接口拿到这个集合,更改一下不同的 key 或者类型,多出来的不管,把它传递到下一个下单的接口。
-
接口间参数传递的一种解决方案 at 2021年11月29日
挺不错的实践,我最近在解决类似依赖问题的时候也是采用了同样的方案,用资源池解决上下游的耦合以及避免资源的重复创建,用依赖注入来减少主动去资源池拉资源的代码。
主要的思想来源是 spring 和recoil -
怎么统计接口返回的 json 中 key 的数量? at 2021年11月21日
json 本质还是一个树结构呀,参考树的遍历,比较简单的就是使用递归或者栈。