引言
做过接口自动化测试的同学肯定都熟悉在全链路测试过程中,很多业务场景的完成并非由单一接口实现,而是由很多接口组成的一条链路实现。例如你在淘宝上购物场景。
不同于单接口测试,这种链路型的接口自动化测试,由于接口间有参数依赖关系,往往不能将链路中的接口入参固定写死,而是要依赖 “上游” 的响应中的某个字段值,因此需要提取出来动态地传递给下个接口,如下图。

解决链路间参数传递的问题可以简化为解决接口间的参数传递问题。当然我上图举例是比较简单的,下游对上游的依赖关系为 1 对 1 这种类型。实际业务场景中,更多的是多对一这种场景,即下游依赖上游的多个接口的返回结果。
当然,针对这个问题的解决方案,其实还是蛮多的。就以 JMeter 工具为例,它就提供了通过后置处理器的多种参数提取方法。
其解决方案是,通过正则、JSON Extracor 等提取的结果作为变量,动态传递数值给下游(变量)使用。
当然,这种解决方案对于 JMeter 工具来说,是个不错的解决方案,而且这个解决方案也具备普适性,就算你开发自己的接口测试框架,也是可以使用这种解决方案的(实际上,我在前东家参与研发的接口测试框架,当时解决接口间参数传递的问题就是借鉴的这种思路。开发了一个类似 JMeter 正则提取器的正则提取工具包,引用工具包可以允许你输入要提取的字段 key 便可匹配到其字段值 value,如果提取不到就返回默认值,如果有响应体中一个 key 存在多个 value,则返回最后一个匹配到的 value;下游接口则使用 Java replace() 方法替换掉请求体中的 ${xx}。)。
如果只追求可以用,这个方案没问题。但是这个方案缺点就是接口用例开发效率比较低,增加了写接口测试用例的成本。这也是我当时遇到的一个问题,大家写自动化测试用例的时间很大一部分花在接口间参数提取和调试上。此外,这个方案也会增加维护成本,导致用例的 “稳定性” 比较低。是因为如果上游接口的响应体结构变化可能会影响提取结果,下游的接口请求体中的 ${xx}也需要手动维护。总结下来,自动化用例的维护和开发成本主要集中在接口间参数传递的维护上面。
是否有更优的解决方案呢?
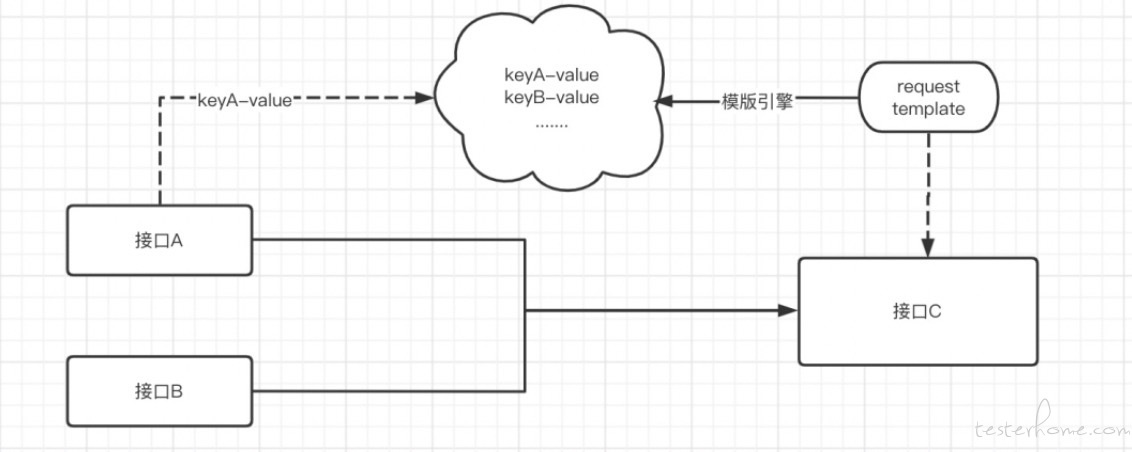
试想一下,我们能否将整条链路可能使用到的字段集合作为一个池子,在上游接口的响应结果提取出 key-value 并扔到池子里。下游的接口 request 体模版化,以 ${xxx}表示需要替换的变量,利用模板引擎 (例如 Java 的 velocity/FreeMarker) 将 ${xxx}替换成 “池子” 中存在的 value。实现的简图如下。
动手做:下面就以 Java 语言实现为例,写两个方法 A、B,且 B 依赖方法 A 的返回结果。
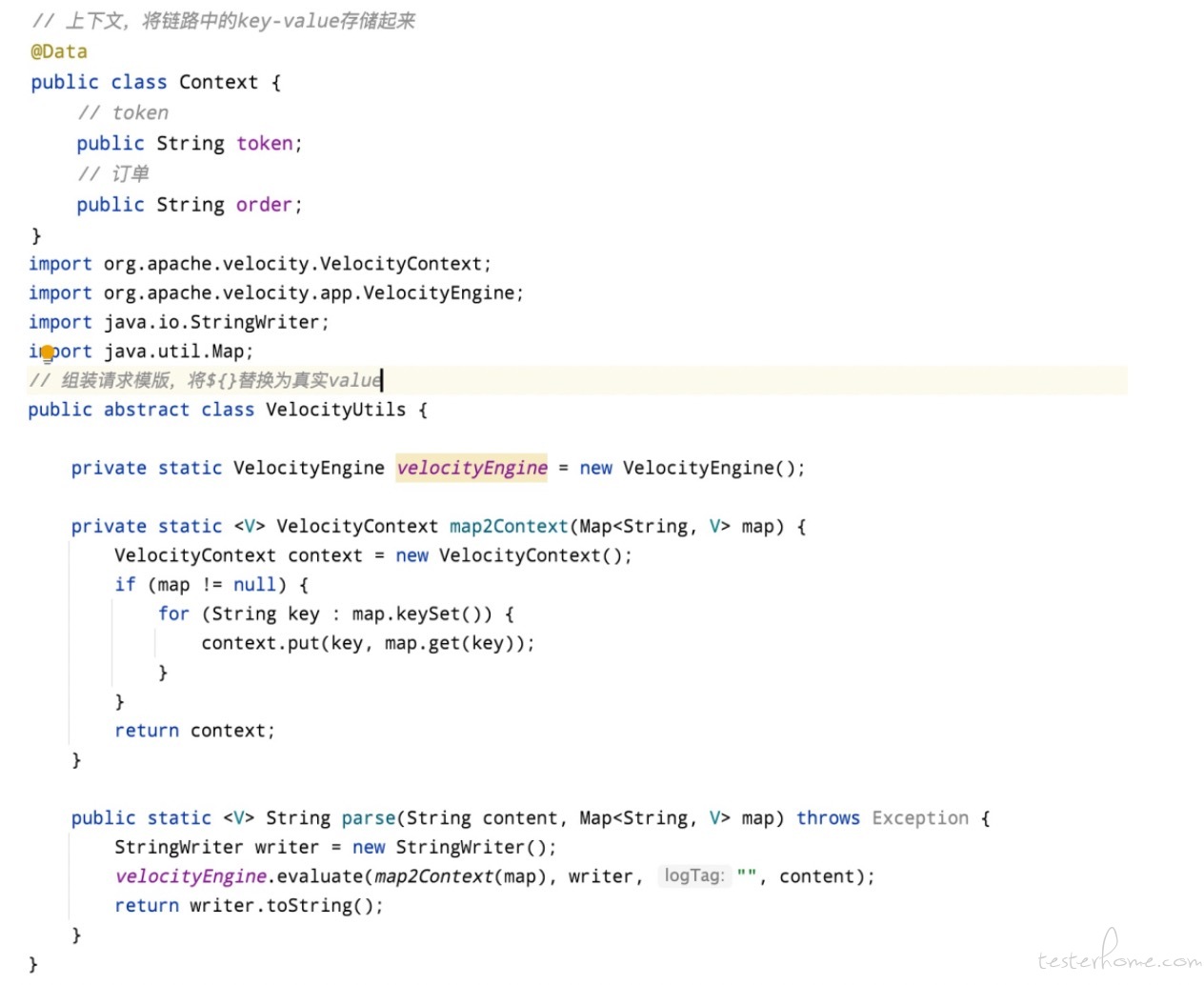
我们只需要开发 上下文类、模版组装工具、模拟场景代码即可。
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.beanutils.BeanUtils;
import java.util.Map;
public class Client {
public static JSONObject login(){
JSONObject result = new JSONObject();
result.put("token","xsjkjdskdjsksjfksjfksjk");
return result;
}
// pay接口,依赖login接口
public static JSONObject pay(String request){
JSONObject result = new JSONObject();
// 就简单写了
if (request.contains("xsjkjdskdjsksjfksjfksjk")){
result.put("order", "122324434335");
result.put("status", "success");
} else {
result.put("status", "fail");
}
return result;
}
// 场景模拟
public static void main(String[] args) {
// 首先调用登陆接口
JSONObject loginResponse = login();
// 步骤1.将结果写入上下文
Context context = new Context();
context.setToken(loginResponse.getString("token"));
// 创建一个pay接口的request模版
String request = "{\"token\":\"${token}\"}";
try {
// 步骤2.利用Apache BeanUtils工具 BeanToMap方法 将上下文转化为keyValues
Map<String,String> keyValues=null;
keyValues = BeanUtils.describe(context);
// 步骤3.组装模版,将${token}替换为上下文中的其key存在的value
String out_request = VelocityUtils.parse(request, keyValues);
System.out.println("组装request请求模版:" + out_request);
// 发起下单支付
JSONObject result = pay(out_request);
// 打印接口返回结果
System.out.println("打印响应结果:" + result.toString());
}catch (Exception e){
System.out.println("异常退出");
}
}
}
这种方案的优点:
我们只需要 care 步骤 1 即可(将上游的响应结果写入上下文),后面的组装模版这些可以写成同样的工具,只需要传入模版 + 上下文内容即可,无需关注其他,能大大节省自动化用例开发和维护的成本。
当然,本文只是抛砖引玉,如果有其他方案,也希望大家多多发散,多多交流沟通。
工具清单:
commons-beanutils
org.apache.velocity
com.alibaba.fastjson
org.projectlombok.lombok
