-
记一次郁闷的面试经历 at 2020年03月05日
这就是 公式化 的回复罢了,实际肯定不是这个原因挂的
-
记一次郁闷的面试经历 at 2020年03月05日
嗯,这个知道了。但还是会有那种被逼着不说实话的感觉,很不舒服。
-
记一次郁闷的面试经历 at 2020年03月05日
正经的离职原因只有两种,其他的建议就不要说了:
1、发展和公司、平台的匹配度不对了,也就是传说中寻求更好的机遇;
2、家庭,比如定居了、子女读书了,等等等等,凸显稳定性加固的理由。 -
记一次郁闷的面试经历 at 2020年03月05日
老实人,也可以说是傻,哈哈😂
-
记一次郁闷的面试经历 at 2020年03月05日
离职原因都敢实话实说,你是心真大呀
-
记一次郁闷的面试经历 at 2020年03月05日
嗯,这次打击后暂时想着今年一边等待机会,一边把数据结构和算法、设计模式、pytest 源码看懂了,然后再去面试一次这家公司。下次有可能再提离职理由,就是有更好的发展机会了。
-
记一次郁闷的面试经历 at 2020年03月05日
小公司希望员工有个性,大公司希望员工螺丝钉。
-
记一次郁闷的面试经历 at 2020年03月05日
有时候觉得,渐渐被磨平了棱角,圆滑了起来。大公司难道都不希望员工有个性吗
-
记一次郁闷的面试经历 at 2020年03月05日
有些东西自己心里知道就可以了,没必要讲出来,你这个败在面试技巧不是败在技术上。
-
记一次郁闷的面试经历 at 2020年03月05日
当时没想那么多,想着实话实说,的确就是那样,而且公司里很多人都这么想的,所以整个开发和测试都比较散。主要是外行领导内行,而且做销售的来当项目经理。
-
记一次郁闷的面试经历 at 2020年03月05日
"离职原因主要是答得跟领导做事、做人理念不一致",你也太实在了
-
记一次郁闷的面试经历 at 2020年03月05日
可能介意的是你的离职原因,拒绝理由只是随便说说。
-
记一次郁闷的面试经历 at 2020年03月05日
-
吐槽下我那神奇的上司 at 2020年03月02日
匿名还确实联系不方便。加个 QQ?
-
吐槽下我那神奇的上司 at 2020年02月29日
造数据这个,做了一次后其他就还好了。测试可能比较少接触模板吧,可以多了解下开发技能。
-
吐槽下我那神奇的上司 at 2020年02月28日
怎么联系啊 我在南京
-
吐槽下我那神奇的上司 at 2020年02月28日
好好搞啊 说不定你就是下一个研发老大
-
吐槽下我那神奇的上司 at 2020年02月27日
因为我写好后还没发出去,,还躺在草稿箱里。本来想开个帖子的,但是觉得好像也没太大事情。职场上不是说自己一腔热血就能有同样的对待的。
-
吐槽下我那神奇的上司 at 2020年02月27日
先按照你的理解弄呗 先弄出个 123 再说
-
吐槽下我那神奇的上司 at 2020年02月27日
这种领导需要学习下管理 也可能是情商不够高
-
吐槽下我那神奇的上司 at 2020年02月27日
你这个文章,怎么搜索不到呀?小板凳都搬来坐等了。不是所有 leader 都能处事不惊,许多 leader 和 goverment 公务员似的,遇到下面的问题不敢往上报,遇到其他部门的反馈,当做打压下属的板子。搞得所有人都带上面具。真正好的领导,是能消除部门墙,勇于直面问题,躬身入局的。来南京吧。我们公司领导都不错
-
吐槽下我那神奇的上司 at 2020年02月27日
我是楼主,6 楼的机器学习的很多帖子我都看了,我还关注了你的。围观下大佬

-
吐槽下我那神奇的上司 at 2020年02月27日
我是楼主,谢谢大家的关怀。再补充下,要求造的数据的千万行的银行数据,好用来训练,要用类似银行的字段造,不能用 sklearn 的 api 造那种全是数值型的数据,老板说这样太不正规了。楼主撸代码水平渣渣,实在是臣妾做不到。
-
吐槽下我那神奇的上司 at 2020年02月27日
可以跟帖表达一下玻璃心么

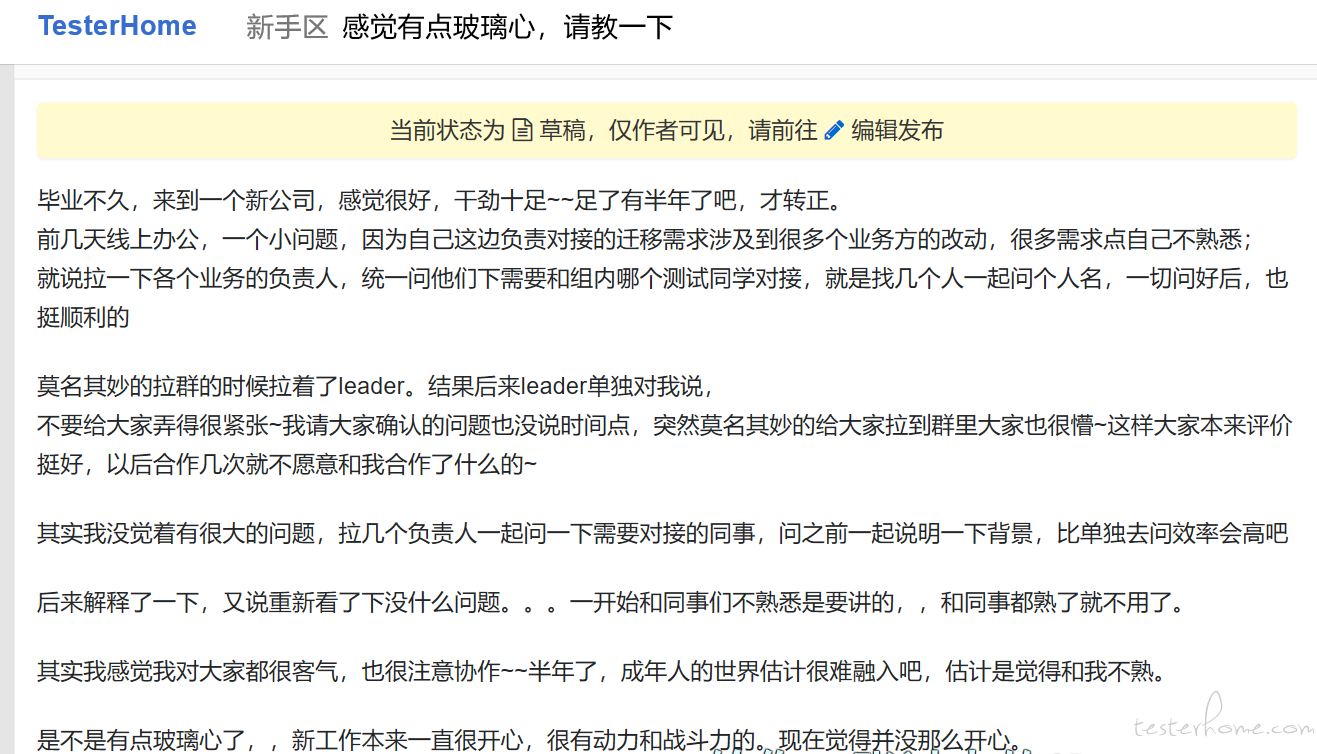
-
吐槽下我那神奇的上司 at 2020年02月27日
建议多了解下需求,我也碰到过这样的问题。下放任务的时候需求描述不清晰,导致员工一脸为难的看着我,也说过:这个很简单,你想的太复杂了。手把手带他做了开头之后,后面工作开展就没问题了。