-
性能测试工具脚本录制及调试方法之 kylinPET at 2023年07月19日
kylinPET 录制的脚本不支持导入 jmeter
-
国产奇林性能测试软件 (kylinPET) 在单台机器上实现百万级别的并发的技术路线 at 2022年06月01日
类似 netty。
-
你的想法很好,几乎不可能。不过奇林测试平台(kylinTOP) 你可以研究一下,录制的脚本中包含元素的所有属性,即使用元素部分属性变更举动影响步骤的执行。也算是一个不错的方案。
-
有没有大佬知道为什么 loadrunner 录制脚本时,网站加载很慢而且录制后只有事务没有脚本 at 2022年05月31日
你是你厉害
-
有没有大佬知道为什么 loadrunner 录制脚本时,网站加载很慢而且录制后只有事务没有脚本 at 2022年05月31日
LoadRunner 录制网站时确实有这个问题。加载的比慢。有时有的网站还打不开。
最好后用老的 ie 浏览器版本。Chrome 会有问题 -
Jmeter 线程模型设计引发的思考 at 2022年05月30日
你提到的用少量的线程实现,高并发的在线虚拟用户模拟的能力,这个功能在奇林性能测试软件(kylinPET) 上已经实现。
在单台机器已经可以实现百万级别的并能力。 -
性能测试过程中如何来体现数据有效性 at 2022年05月27日
其实你没理解提问者的意思。比如脚本中有一个事务,想测试系统允许最大:事务成功数/秒,也就是事务无异常的情况,每秒平均可以处理多少个(最大值,平均值,最小值)。这指标就是系统的事务处理能力。事务中是包含很多的请求,这些请求全部处理成功,那么这个事务就是成功的。问题来了,如判断事务中的请求都是成功的呢?对于大部分的性能测试功工具,你需要对事务中的每个请求增加检查点(也叫断言),否则性能工具无法判断这个请求是成功还是失败。LR 和 Jmeter 需要手工加内容判断的断言。奇林性能测试工具(kylinPET),响应码可以自动判断(如果事务中的请求失败时返回与录制的响应码不一样),这种情况下就不需要增加检查点,工具本身可以自动判断,否则根据需要可以增加:长度检测查、SQL 内容检测查、或响应内容检查等,这些根据你的需要增加。
-
性能测试过程中如何来体现数据有效性 at 2022年05月26日
1、做性能测试过程中,要判断数据有效性,需要做两点:
1)如果接口失败返回的响应码与正常的响应码不一样,那么只要判断响应码是否与当时录制的一样即可。
2)如果接口失败返回的响响码与正常的一样,那么可以判断响应长度( 这种方式节省资源)
或判断内容(这种方式就比较消耗资源),sql 返查询等 -
性能测试工具之的 web 动态请求仿真度对比测评分析报告 at 2022年05月26日
感谢你的回复,试了你的方法才,用 URL 模录制。URL 录制生成的脚本,把页面子了请求都放在脚本中了,相当于脚本中包含了所有请求。对于页面静态请可以生成 web_concurrent_start、web_concurrent_end(并发组函数),我的静态页面包含 8 个请求,录制结果把所有 8 个子请求都放在同一个并发请求组中(与实际不符),导致测试数据比浏览器加载时间小。又试页面动态请求 web_concurrent_start、web_concurrent_end 组,全部按串行处理,导致则试比实际的大。
-
性能测试工具之的 web 动态请求仿真度对比测评分析报告 at 2022年05月24日
kylinPET 支持 HTTP1.1、HTTP2.0 和 HTTP3.0 协议。你可以到官网下载研究一下
-
性能测试工具之的 web 动态请求仿真度对比测评分析报告 at 2022年05月24日
你的问题非常好。
1、使用真实浏览器多次访问同一个被测试对象的 web 网站,因为网络等资源问题,每一次都会不会过多全一样,存在一定的偏差。做为性能测试工具,都是尽可能的去模模拟浏览器的行为。任何一款性能测试工具都无法完全做到一模一样,都是尽可能的模拟。不好的性能测试工具模拟的结果偏差大,好的性能性能测试工具模拟的偏差小。
kylinPET 支持三种仿真能力:
1)根据录制到的请求以及 HTTP 协议的规则去模拟,尽可能的去仿真浏览器行。业界大部分是这种,但是模拟的偏差比较大。Jmeter 就是简单粗暴,全部是串行。最新版本的 LR 对动态请求模拟显得的力不从心,静态请求
2)另一种支持按照录制请求时间间隔下发请求。 3)串行,用户可以强制串行发下请求
2、APP 的请求不一定都是串行的,主要看开发人员的设计。
3、浏览器的加载资源加载顺序不固定,但是是有规律的,你可以仔细观察一下。HTTP1.1 协议最多 6 个并发等规则。
做为一款好的性能测试需要尽可能的模型这些规则。 -
性能测试工具之的 web 动态请求仿真度对比测评分析报告 at 2022年05月20日
你是发散型思维,本文仅限于讨论性能工具对 web 的仿真能力。你非要去讨论系统要怎么测试,要关注什么,哪些场景没有浏览器界面。
-
性能测试工具之的 web 动态请求仿真度对比测评分析报告 at 2022年05月18日
性能测试的并发模型有两种:
1)虚拟用户间的并发模型。也就虚拟用户之间是按什么样的递增或递减的方式并发。
如:有 100 个虚拟用户,按每秒新增 5 个在线用户数的方式递增,直到在线用户数达到 100,保持不变。
2)虚拟用户请求的并发模型。性能测试工具模拟虚拟用户,都是通过一个脚本的方式模似的,性能脚本执行一次相当于完成一次虚拟用户的操作。性能脚本包含多个请求,而这此请求之间的并发关系,就是虚拟用户请求的并发模型。 -
性能测试工具之的 web 动态请求仿真度对比测评分析报告 at 2022年05月18日
1、文章通过单一个虚拟用户在线操作,分析了虚拟用户的行为特征。如果单个虚拟用户在线操作的行为失真,同样,多用户操作的影响也是一样。在任何时间任任何场景,都要求虚拟用户本身的行为(虚拟用户的请求瀑布模型)必须真实的浏览器保持一致,否则会就会导致测试结果失真。
文章最后说系统允许的最大线用户数,是指最大在线操作用户数。要操作哪些要看系统的需求。比如:系统需求是最大线操作用户数 100,且 100 个用户同时在线操作下,系统的性能满足指标要求。那么你需要测试 100 个用户同时登录,并对一些关键的事务(如:系统支付功能等)进行并发操作(这里的并发是指虚拟用户间的并发)。如果这时每一个虚拟用户的行为都与浏览器的行为是相同的,那么整体测试的结果是也是可信的。假定我们测试的是在线支付功能,100 个用户同时点击支付(点击支付我们假定每个用户需要发送 6 个请求,并且是并行的),如果性能工具处理把每个虚拟用户处理成串行的 6 个请求,那么 100 个虚拟用户同时点击,对被系统的压力最大是 100 个并发请求,如果虚拟用户处理为并行的,那么对被测系统的压力就是 600 个并发请求。 -
我想问大家,有没有使用性能测工具,测试达到百万并发的在线用户数,请各位分享一下测试经验 at 2021年11月05日
花了一周时间最终于做到百万级别的性能测试任务
-
我想问大家,有没有使用性能测工具,测试达到百万并发的在线用户数,请各位分享一下测试经验 at 2021年11月05日

-
国产性能测试工具 kylinPET 在统信操作系统(鲲鹏处理器)上的能力测试 at 2021年09月17日
搜索一下 kylinPET 的安装目录,在 kylinPET7.2\lib 目录下的确有一个 okhttp-3.9.1.jar 文件。然后尝试把这个包删除。
发现具然即不影响脚本录制,还不影响性能任务执行,你也可以试一试。 -
国产性能测试工具 kylinPET 在统信操作系统(鲲鹏处理器)上的能力测试 at 2021年09月16日
我感觉我们国人的自信心还没有建立起来
-
国产性能测试工具 kylinPET 在麒麟操作系统上的能力表现 at 2021年09月14日
kylinPET 和 loadRunner 一样,都是商业软件
-
国产性能测试工具 kylinPET 在麒麟操作系统上的能力表现 at 2021年09月13日
kylinPET 是不是 Jmeter 改造,可以从以下几个方面来看:
1、录制功能
kylinPET 创造性使用网络监听与浏览器接口调用 (包括 chrome,firefox,edge,谷歌内核其他浏览器) 方式进行录制,录制信息更加详细精确。甚至录制了浏览器的并发行为,以便在并发用户数时达到模拟真实浏览器行为的能力。
1)kylinPET 的 https 录制使用特殊技术使录制适配所有网站,可以使用 kylinPET 录制 www.taobao.com(淘宝)和 jmeter 录制淘宝网,可以发现 jmeter 录制不了淘宝网站,但 kylinPET 可以,证明我们录制能力强大很多
2)支持 http2 技术录制,目前很多网站已经使用 http2 技术,例如淘宝,阿里云,京东等等。可以使用浏览器 F12 查看 “network” 看到 protocol 列为 h2(http2),而 jmeter 不支持 http2 录制
2 界面功能
1)kylinPET 界面完全跟 jmeter 不一样,只是脚本是树形结构相似,这是因为业界 http 测试工具都是类似这种界面,例如 postman,soapUI;kylinPET 更像 loadrunner,操作更简单,功能更强大。
2)kylinPET 实现自动关联,回放与录制对比,并使用真实浏览器验证脚本多种方式降低用户使用难度,快速编写正确脚本。
3、并发发送请求
Jmeter 使用 apache httpclient 或 java 自带 httpconnection 库 作为 http 并发处理,这些库适合开发者调用,但对性能测试有缺点:http 被库封装了,占用内存大(因为不是专给性能测试用,而是开发者用),无法统计 TCP 指标、首分片不准;而 kylinPET 完全自主研发 http/http2 协议栈,因此支持 IP 欺骗、TCP/SSL/DNS 指标;另外,针对 web2.0 特殊定制内存使内存占用非常小,保障性能测试更加稳定(避免内存溢出、垃圾回收导致时间指标大)以上这些我是从官网上摘抄下来的,希望对你有用。
-
国产性能测试工具 kylinPET 在麒麟操作系统上的能力表现 at 2021年09月13日
你可以到官网上下载试一下,与 Jmeter 有着很大的差异。唯一有点关似的就是脚本的形态都 http 原生脚本,这一点也不是 Jmeter 特有的。
-
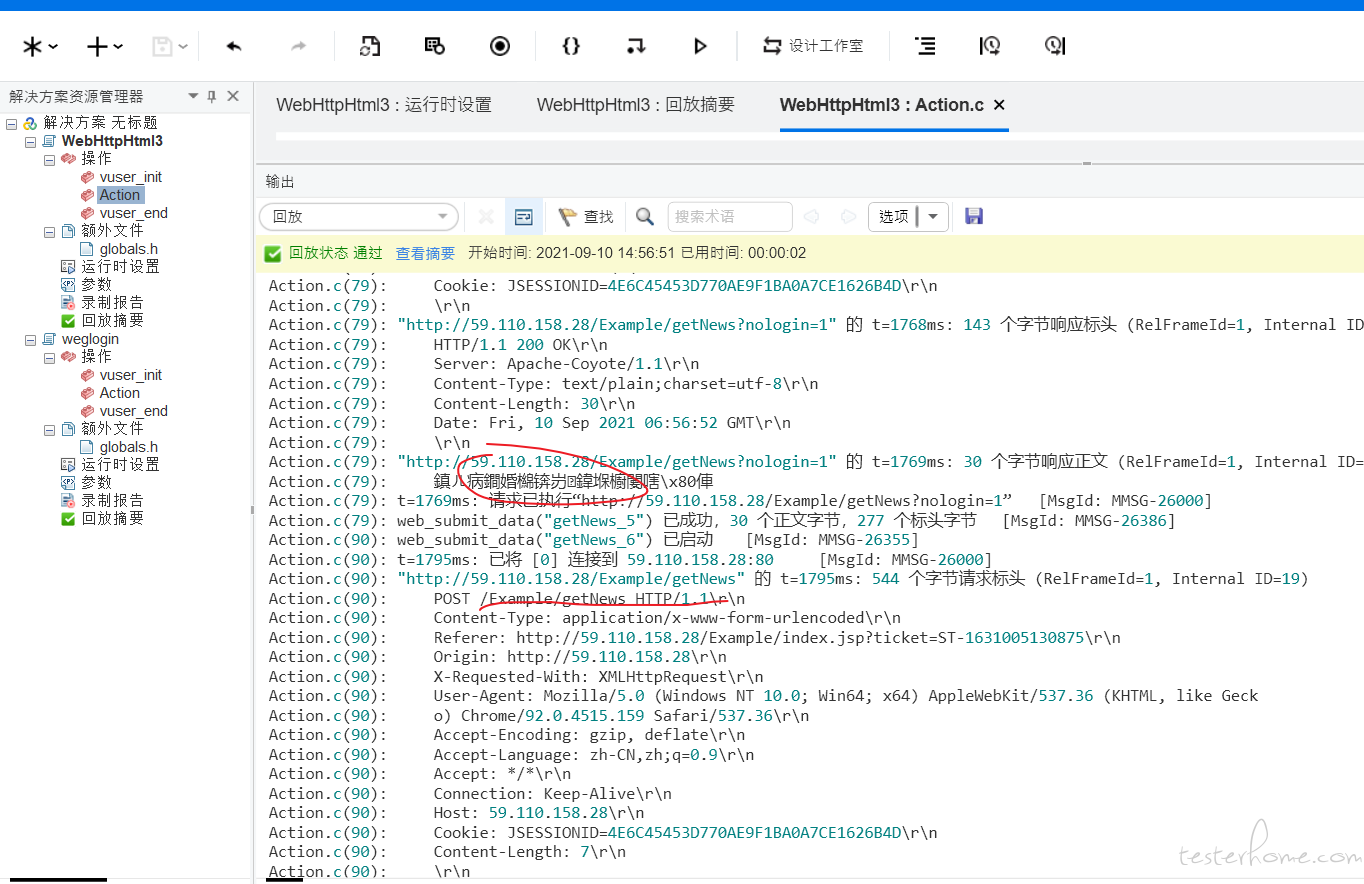
性能测试工具脚本录制及调试方法之 LoadRunner2021 at 2021年09月10日
按照你的设置回放还是比较难发现问题
-
性能测试工具 Jmeter 你所不知道的内幕 at 2021年09月02日
请问线程组设置并行你怎么设置?Jmeter 只支持设置线程数(不同线程组之间并行),并不支持线程组内设置为并行请求,即一个线程组内的请求为并行行为。请算你能设置为并行请求,也与浏览行为不符合。上面的文章已经有浏览的截图,它是有有先有后且有并行。
-
大并发下,jmeter 压测结果与真实的结果差别很大 at 2020年03月21日
这个应当是无解。对于 jmeter 的事务统计,由于的线程组中的所有 HTTP 请求都是线性的(前一个请求返回结果后,再下发下一个请求),而事实上浏览器可以达到 6 个并发。从而导致 jmeter 测试结果会严重不准确,优其是事务统计结果偏差更大