性能测试工具 Jmeter 线程模型设计引发的思考
0.Jmeter 多线程模型引发的思考
作为测试同学,在日常的性能测试工作中,常用的测试工具是 Jmeter,对于日常的业务接口基准性能测试需求,几台云主机压测机一般能搞定,但是当面临电商秒杀瞬时并发场景的时候,可能需要上百台 4C8G 的云主机设备来支撑。JMeter 的单机版本在一般的压力机 4C8G 配置下,因为受限于 JMeter 其本身的多线程模型机制和硬件配置,最多可以支持几百至一千左右的模拟请求线程。规模再次扩充后,容易造成卡顿、无响应等情况。如下图所示是 Jmeter 多线程模型,其优势就是可以在操作系统支持的情况下可以使用到多核处理器的多个核。但是随着性能测试需求的增多,JMeter 为了能满足更多的需求,也在不停地更新其功能和增加其插件,比如支持分布式来解决单机性能不足的问题,支持更多的扩展脚本来满足自定义需求等等。但是其基础并发模型一直沿用多线程模型,导致其单机并发性能没有办法进一步提升,这种并发模型是一种典型的阻塞 IO + 多线程的实现方式。
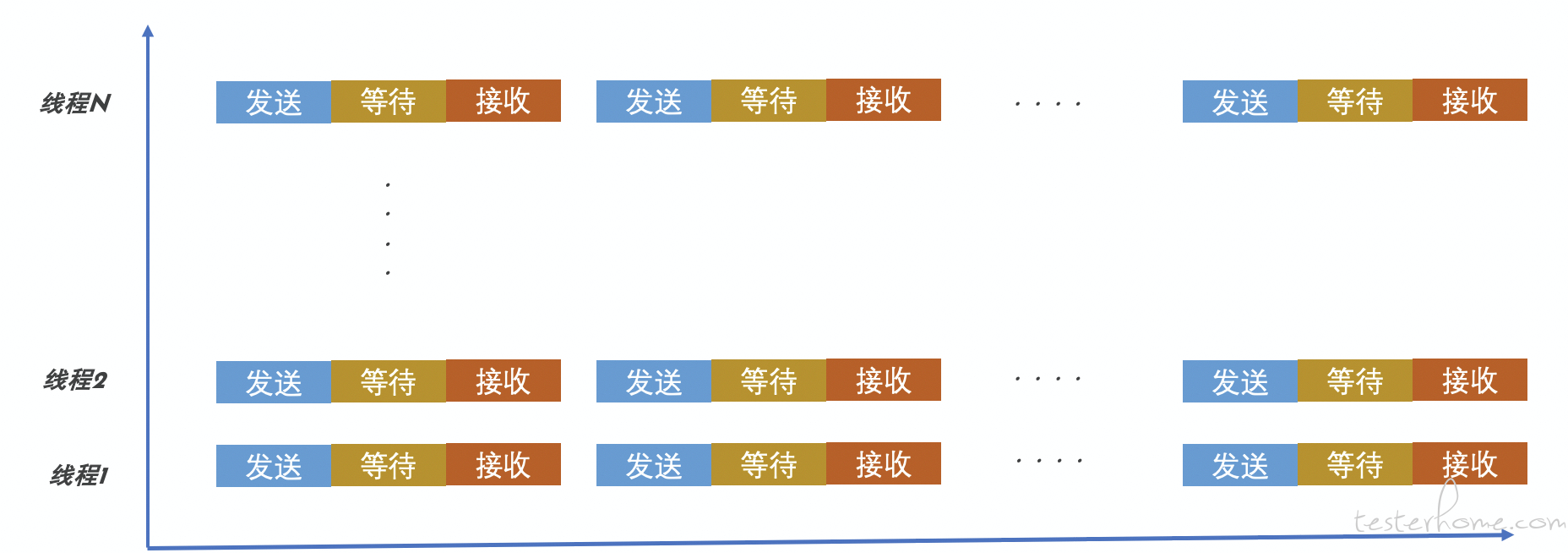
既然有瓶颈,必然有演进,从 Jmeter 的多线程模型瓶颈出发,我们可以再来看这么几个问题:
1)如何用少量的线程支撑大量的连接?
2)Tomcat BIO 与 NIO 模式到底谁的性能更优?
3)为什么大家都在用 netty 作为业务高性能开发的基础网络框架?
这些问题的本质回归到典型的两个性能指标:吞吐量(QPS/RPS/TPS)、响应时间(RT),用个大白话来讲就是 “能够足够快的正确处理大并发流量请求”。首先来看下一个请求常规的三件事情:
- 客户端连接及事件管理
- 处理 IO 事件响应
- 业务逻辑处理
来看这么一道算术题:1 个请求需要(1 个连接,1 个线程),1 万个请求就需要(1 万个连接,1 万个线程),如此可以思考一个问题:如果这 1 万个请求并发过来需要处理,那么就需要同时处理 1 万个连接,需要同时开启 1 万个线程来处理,显然这不是一个好的做法。这呈现了一个经典的问题:C10K 问题,C10k 是用于同时处理一万个连接的表达。请注意,并发连接数与每秒请求数不同,尽管它们很相似:每秒处理多个请求需要高吞吐量(快速处理它们),而大量并发连接则需要高效的连接调度。换句话说,每秒处理请求量与处理请求的速度有关,而能够处理大量并发连接的系统不一定必须是快速的系统,只需要确保在有限的时间 (不需要固定) 内可以返回每个请求的响应即可。也就是说 C10K 问题是能够处理好 “客户端连接” 及 “IO 事件处理” 这两件事情,要想能够实现 “足够快的正确处理大并发流量请求”,还要围绕 “业务逻辑” 展开优化,当然本文只讨论前者。
为此,本文主要着手于 IO 的视角分析关于高性能应用框架在处理高并发连接调度的设计演进,回溯的演进过程如下图所示,着手于以下几个方面:
1) 阻塞 IO->非阻塞 IO->IO 多路复用
2) IO 多路复用的演进
3) Reactor 模型的 3 种模式
4) 主流高性能应用服务器的设计

1. 阻塞 IO->非阻塞 IO->IO 多路复用
一个典型的请求链路是 nginx->tomcat->server
nginx->tomcat(CS 模式)
tomcat->server(CS 模式)
两者都是 server-client 模式,采用 TCP 协议,底层采用 linux socket 通信,如下是一个典型的 CS 实现

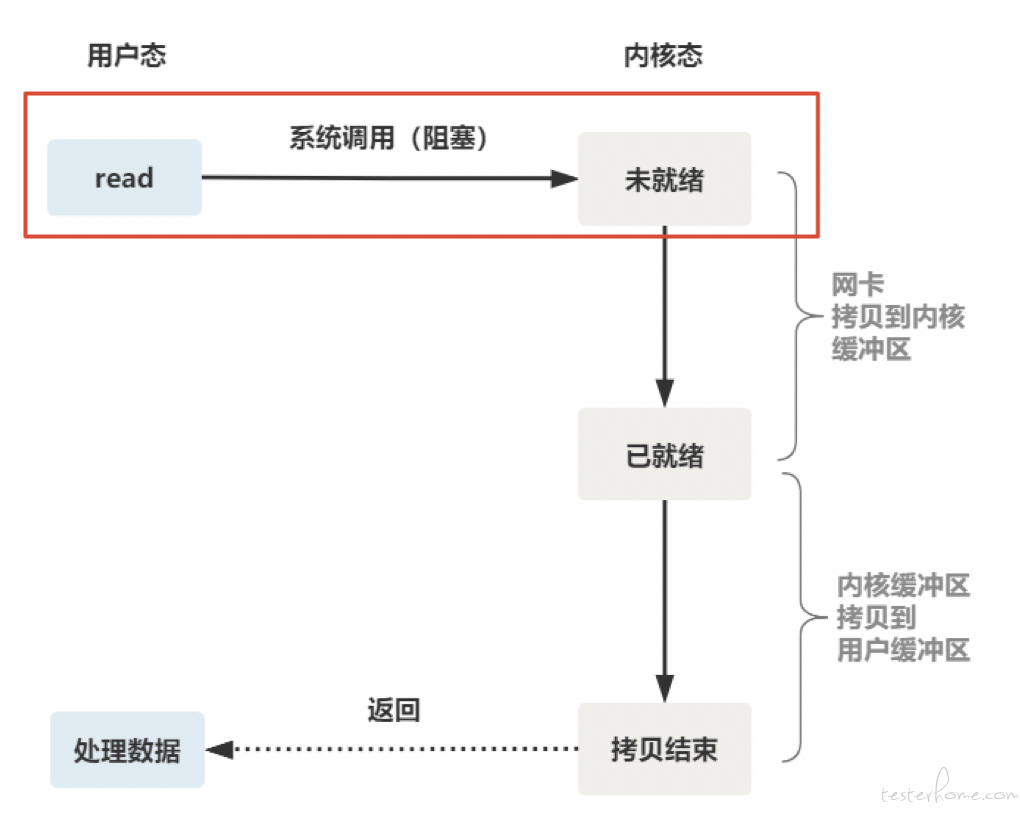
服务端的线程会有两个阻塞点:一个是 accept 函数(等待连接建立),一个是 read 函数(等待数据到达)。
【传统的阻塞 IO】如果这个连接的客户端一直不发数据,那么服务端线程将会一直阻塞在 read 函数上不返回,也无法接受其他客户端连接。
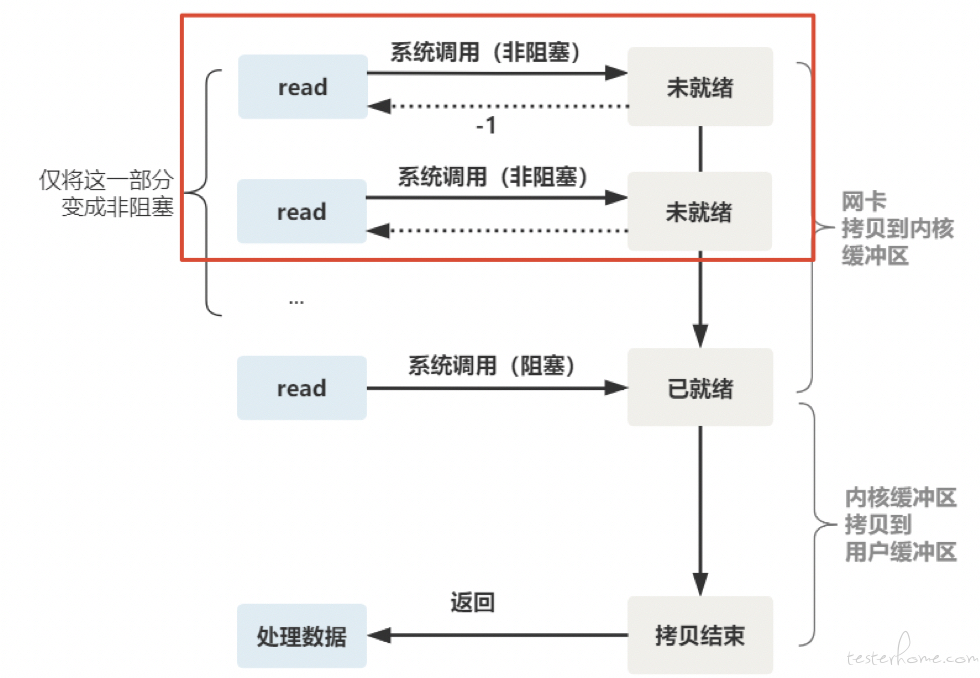
【非阻塞 IO(演进)】:将 read 变成为非阻塞调用,如果未读取到数据,read 系统调用返回-1,操作系统为我们提供一个非阻塞的 read 函数,通过设置属性 O_NONBLOCK。这个 read 函数的效果是,如果没有数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。非阻塞的 read,指的是在数据到达前,即数据还未到达网卡,或者到达网卡但还没有拷贝到内核缓冲区之前,这个阶段是非阻塞的。当数据已到达内核缓冲区,此时调用 read 函数仍然是阻塞的,需要等待数据从内核缓冲区拷贝到用户缓冲区,才能返回。如下图所示
2. IO 多路复用演进
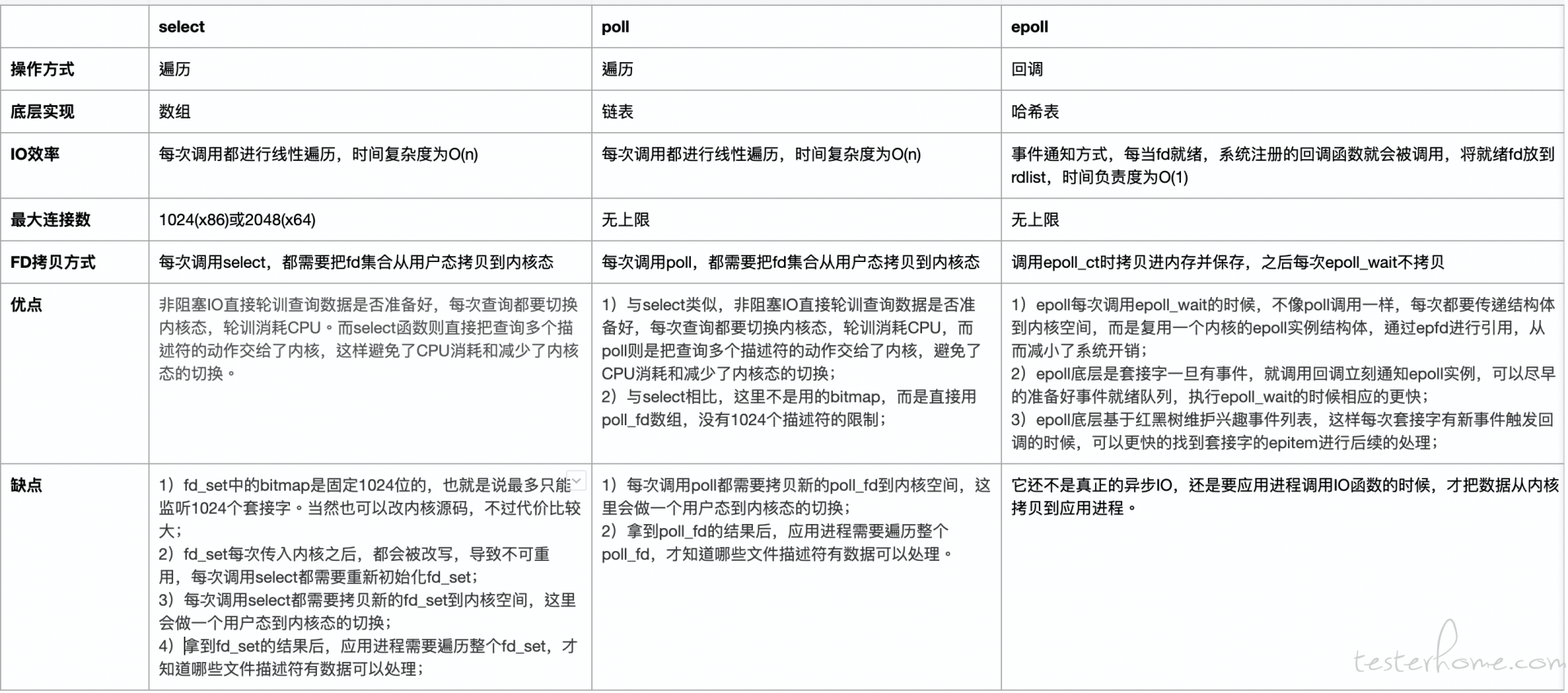
I/O 多路复用 (I/O multiplexing),指的是通过一个支持同时感知多个描述符的函数系统调用,阻塞在这个系统调用上,等待某一个或者几个描述符准备就绪,就返回可读条件。
(多路复用的演进目标是减少系统调用,以及用户空间和内核空间的交互。操作系统提供了这样的系统调用从 select->poll->epoll,使得原来的 while 循环里多次系统调用,变成了一次系统调用 + 内核层遍历这些文件描述符)
其演进过程为:select->poll->epoll
3. Reactor 模型的 3 种模式
Reactor 反应堆模型,属于 I/O 事件驱动模型,我们也称为Event Loop 模型。
Event Loop 是一个程序结构或称为设计模式,是事件驱动模型的一种实现。Event Loop 通过向某个内部或外部 “事件提供程序” 发出请求(通常会进入阻塞状态)来工作,拿到结果后,调用相关的事件处理回调程序。
Event Loop 一般设计为如下的分层架构:
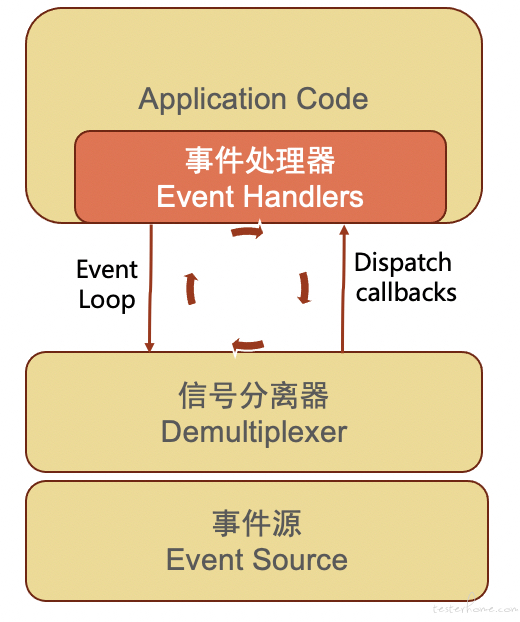
- 事件源:产生一连串的事件,如界面上的按钮是一个事件源,能够产生点击事件;
- 信号分离器:主要职责是等待事件在事件源集上发生,然后将其分派到其相关的事件处理程序回调;
- 事件处理器:执行应用程序指定的响应回调。
其核心处理是: I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程进行业务处理。我们来看下一个请求的三件事在 reactor 模型中是怎么分配协作完成的。通常 Reactor 线程负责监听和分发事件,事件类型包含连接事件、读写事件;处理资源池(worker)负责处理事件,如 read -> 业务逻辑 -> send;
典型的 3 种模型:单线程版本的 reactor、单 reactor + 多线程(worker)、主从 reactor + 多线程(worker),接下来看下这三种模型
3.1 单线程版本的 reactor
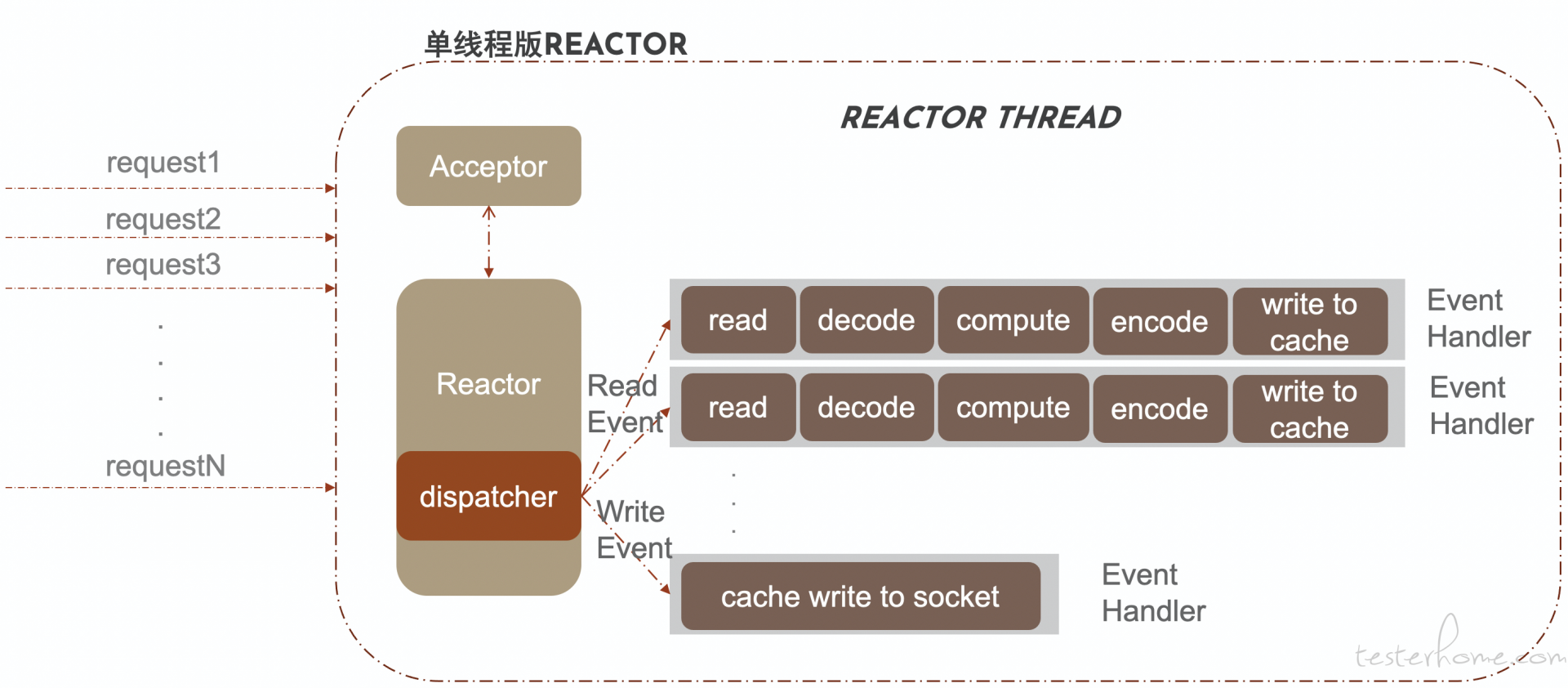
Reactor 线程处理了所有的事情,包括:
- Accept 接收新连接,把新连接 IO 读写事件注册到同步事件多路解复用器;
- 执行 dispatch 调用多路解复用器阻塞等待 IO 事件;
- 分发事件到特定的 Handler 中处理;
缺点:单线程版本中的 Handler 处理会阻塞 Reactor 的 Event Loop 线程的 IO 轮询
3.2 单 reactor + 多线程(worker)
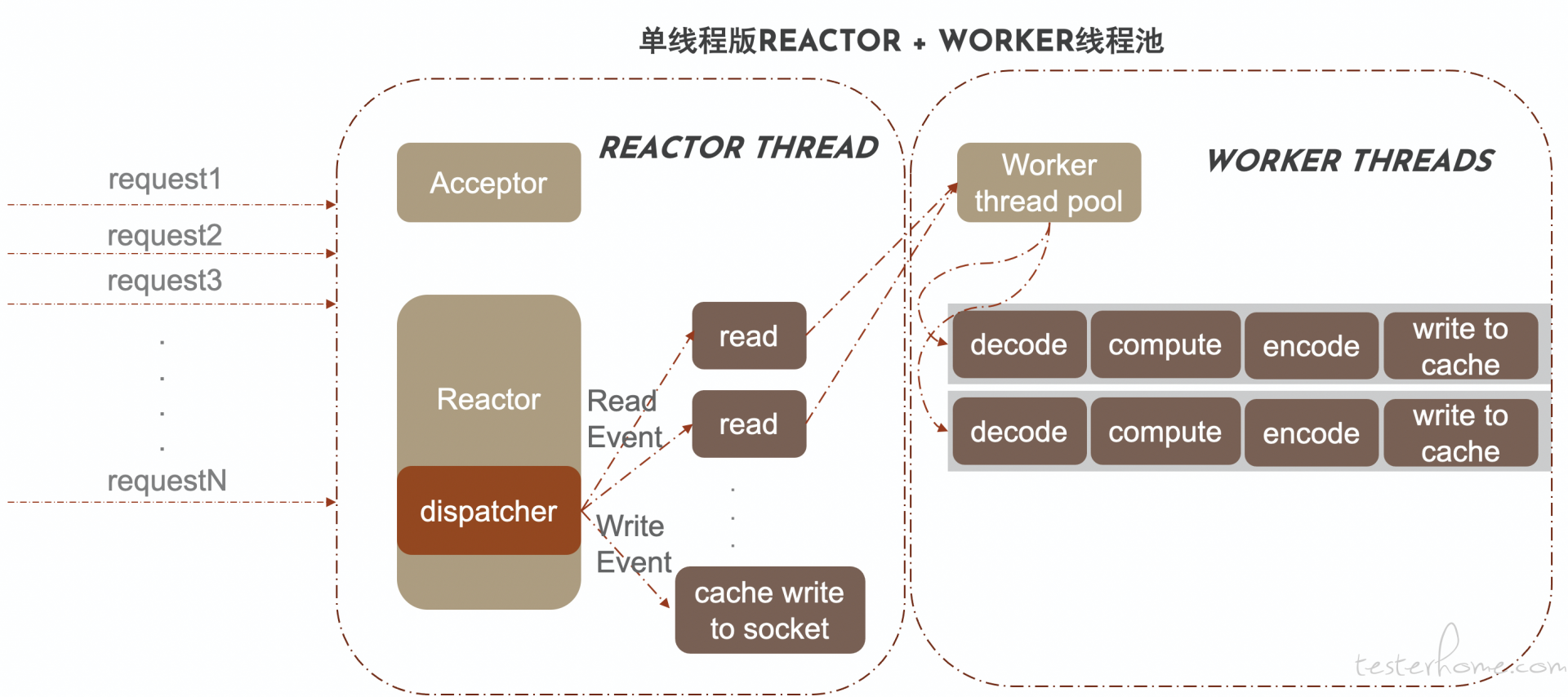
缺点:单线程版本的 Reactor 可能因为 Event Handler 处理速度太占用 CPU 时间,导致新请求进来的连接套接字不能及时通过 Reactor 注册到 Synchronous Event Demultiplexer 中进行 IO 轮训,相关 IO 事件得不到处理,简单来说就是新的连接服务器不能及时处理,也就是 IO 分发效率不高。
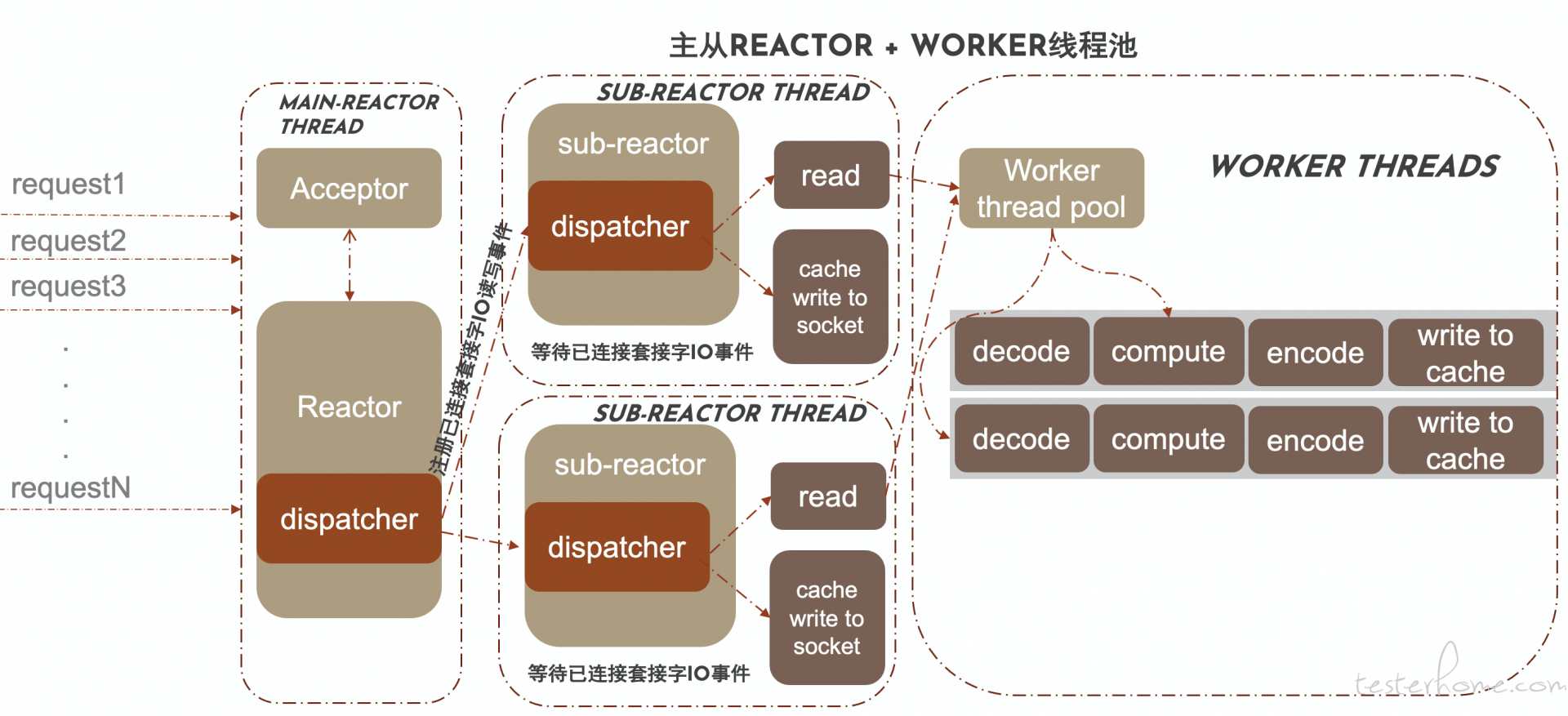
3.3 主从 reactor + 多线程(worker)
通过使用多线程技术,可能更有效的提高 CPU 资源的利用率。我们可以同时创建多个 Reactor 线程,一个线程处理监听套接字的连接事件,作为主 Reactor,其他线程处理已连接套接字的 IO 事件,作为从 Reactor
4.主流应用服务器的应用
部分主流应用服务器的线程模型设计,参考了 reactor 模型的设计理念和模式,例如 netty 是采用的主从 reactor + worker 线程池的模型,redis 采用的是单线程 reactor + IO 线程池的模型,nginx 是采用的是单线程 reactor + worker 线程池的模型。具体参考:https://www.itzhai.com/articles/how-sql-works-understand-the-essence-of-tuning-by-the-execution-principle.html8 大主流服务器程序线程模型,这篇文章里的内容介绍得非常到位了,整体介绍了 :Node.js,Apache,Nginx,Netty,Redis,Tomcat,MySQL,Zuul
回到性能测试工具这件事情上来讲,Jmeter 的阻塞 IO+ 多线程模型应该是存在历史原因的,它的发布是从 1998 年开始。后面出来的性能测试工具,如 Locust 它选择了 EventLoop 模型,wrk 为了提升吞吐能力,使用基于 epoll 的 IO 复用模型。本篇文章不在于对比选择哪个性能测试工具,而是仅从线程模型设计的维度去研究整个的演进过程。从应用的视角来讲,无论是企业内部的自研压测平台还是外部开源的 MeterSphere,Jmeter 一如既往的被青睐,因为它成熟而强大,他通过分布式的能力来增强它的高并发压测需求,无非是多费点压测机器(富有)
References
1)https://www.itzhai.com/articles/high-performance-network-programming-paradigm.html
2)https://k6.io/blog/comparing-best-open-source-load-testing-tools