-
造数 - 我的理解与落地实践 at 2023年05月05日
"再用造出来的订单号作为造数工厂的数据"
我尝试着理解了一下这句话,
假设我理解的你的场景是这样的,且是正确的:
我现在要进行一个接口测试,这个接口是根据订单号查询订单信息,这个接口会返回订单相关的信息例如,支付金额,优惠券金额,退款金额,还会返回这个订单相关的商品信息,例如商品名称,商品 sku id。在这个场景下,我要进行接口测试,但是我数据库里面没有订单数据,商品数据,甚至订单和商品的关联数据,所以我在接口测试前需要现在数据库中创建这些数据,
所以使用的流程应该是这样的:
1、造数工厂创建商品信息
2、造数工厂在已创建的商品数据基础上,创建订单数据(订单的 id 自定义)、也许你还需要创建订单和商品的关联数据
以上两个步骤在造数工厂中是以任务存在,
3、创建好订单后,这些订单 id 你是知道的,所以这个时候,你就可以将这些订单 id 作为接口的入参了
4、接口运行后,对接口的 response 数据做验证,哪些订单对应哪些商品在你造数的时候你也是知道的,所以校验接口的返回内容也是很方便的 -
造数 - 我的理解与落地实践 at 2023年04月27日
你说的数据校验指的是哪方面的呢
-
【2022 年度】最佳活跃用户、精华贴用户、年终总结征文获奖名单,小伙伴们请扫码进群领取~~~ at 2023年04月03日
进了
-
【2022 年度】最佳活跃用户、精华贴用户、年终总结征文获奖名单,小伙伴们请扫码进群领取~~~ at 2023年03月30日
@Lihuazhang 进不了群呢,现在还来得及吗
-
造数 - 我的理解与落地实践 at 2023年03月30日
不好意思哈,之前截图不是很清晰,
等 2.0 版本吧,到时候会开源出来,网站上会有详细的说明文档
-
造数 - 我的理解与落地实践 at 2023年03月30日
现在在做 2.0 的版本,做好有就会开源出来
-
遇到个问题,涉及到事件回调的功能如何做压力测试 at 2023年03月01日
注意哦
企业微信的回调 API 都是有限流的哦
-
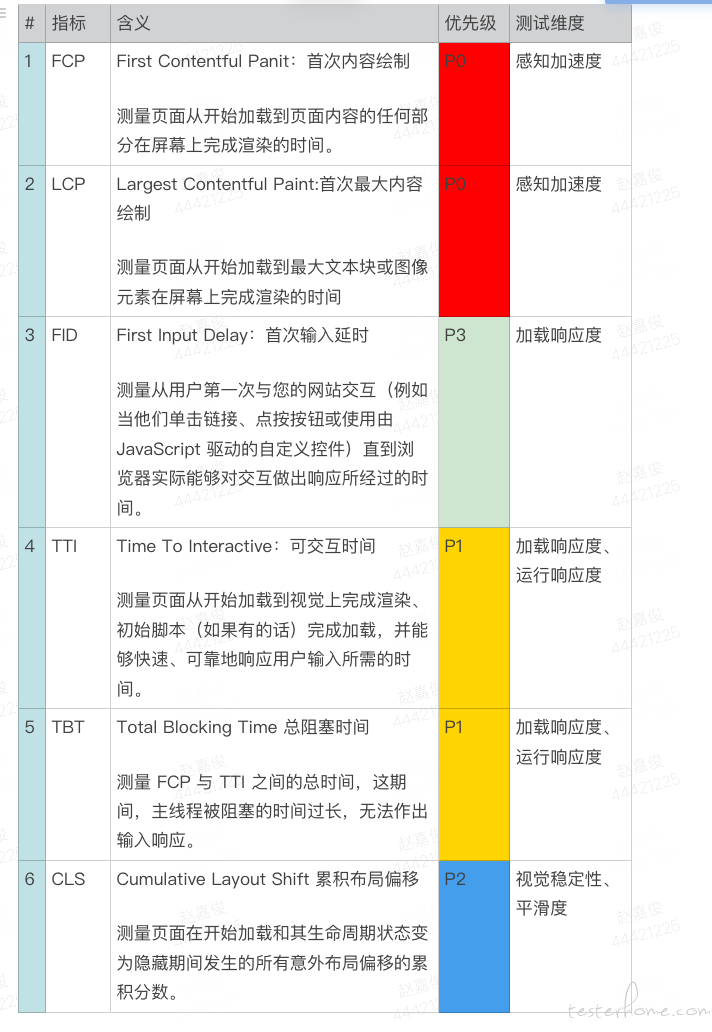
如何有效度量前端性能 at 2023年02月17日
提供两种思路:
1、你可以调查一下 “chrome://inspect/#devices” 和 “微信端调试 H5 页面” 这两个内容
2、文章中其实重点是提供的度量前端性能的维度和指标,所以对于测试人员来说,这里有个很重要的东西就是 “有没有人人能够指出在做前端性能测试的时候应该从哪些维度来度量,这些维度是否合理”,如果这些维度合理的话,至于怎么提取就很容易了,不论是 PC 和移动设备,浏览器内核都是具备调试协议和 SDK 的,可以让开发人员按照你提供的维度在代码中进行提取并上报。
-
造数 - 我的理解与落地实践 at 2023年02月17日
在我的测试团队里面,是要求功能测试人员去参与开发的技术评审,了解开发的设计方案,了解数据结构的。
从数据结构的设计以及数据与数据之间的关联关系反推业务逻辑设计是否合理,是否和 PRD 的功能设计匹配,并寻找业务逻辑的边界场景。
这样下来,测试人员便可以做到熟悉功能的同时对背后的数据结构也非常熟悉。在测试过程中对测试场景的构建才会更加的准确与高效。
-
如何有效度量前端性能 at 2023年02月15日
真丶实践
在时间过程中,其实发现很多前端页面组件加载时序问题. 按照各指标的要求,调整后用户视角的体验提升很多 。
-
造数 - 我的理解与落地实践 at 2023年02月13日
已经 ok 了,谢谢~~
想换几张图片,现在的图片太不清晰了
-
造数 - 我的理解与落地实践 at 2023年02月10日
@chenhengjie123 为啥这边帖子的编辑提交,一直没审核啊
-
如何测量 web 页面加载时间 at 2023年02月10日
-
如何有效度量前端性能 at 2023年02月10日
@chenhengjie123 求加精~
-
造数 - 我的理解与落地实践 at 2023年02月09日
明天更新后回复你
-
如何测量 web 页面加载时间 at 2023年02月09日
现在大多都是前后端分离的,虽然接口的返回时间会影响功能的展示。
但是如果仅仅是从纯前端的性能角度看,需要清除前端渲染的流程,才能测准前端加载的性能好坏,以及哪一个加载渲染环节耗时。
-
如何测量 web 页面加载时间 at 2023年02月09日
建议看一下 google 前端性能指标和对应的提取方法
光看接口返回时间是不够的,前端页面渲染性能和不同组件层级的渲染方式都会影响用户对于页面加载快慢的感知
-
造数 - 我的理解与落地实践 at 2023年02月08日
准确的说是:
开发数据工厂并不需要对测试目标的业务数据结构非常了解,而是需要对测试流程中测试数据的构造方法和造数流程非常熟悉。毕竟数据工厂是一种抽象的数据制造方式,所以数据工厂重点是如何抽象通用的写入业务数据。
使用数据工厂时,才需要对测试目标的业务数据结构非常了解。
例如:
如果测试用例对应的数据场景使用 “接口进行造数”,那么就需要了解此场景下数据对应的接口都有哪些
如果测试用例对应的数据场景使用 “直接向数据库写入数据”,那么就需要非常数据业务数据在数据库中的结构,包括 “表,表与表直接的关联性”
如果测试用例对应的数据场景使用 “消费消息”,那么久需要对消息的消息体内容和上下文非常了解 -
关于页面数据的测试,怎么才能更高效的去完成测试工作 at 2023年02月03日
1、数据项分别有哪些?
2、这些数据项的计算口径是什么?
3、计算口径对应的底层数据来源于哪里,存放于哪里,数据结构是怎样的?
4、底层原子数据到页面展示的口径加工数据之间有几层中间数据?中间数据加工逻辑是什么?底层和中间层的数据是实时加工还是延迟计算。根据以上内容确认测试范围:
1、页面数据展示质量控制维度是哪些?计算准确就行,还是说又要计算准确,又要计算全面,又要计算快速?数据计算的快、准、全
2、根据不同的计算质量控制维度进行质量控制设计。针对底层原子数据,需要保障数据的及时性
例如,如果底层原子数据是有业务系统上报而来,那就需要确认上报方法,例如如果是通过消费消息的方式,那消息是否会在流量高峰期存在积压,系统是否具备高效的削峰能力,一旦积压,前端业务系统计算出的展示数据就会有波动。无论是中间数据的加工计算还是上层展示数据的加工计算:在测试中可以采用以下方法:
1、你在清楚数据项计算口径的情况下,你可以将各数据项的数据根据计算口径转换成 SQL(可以使用 python+sqlachemy+pandas)来做,自己计算出一份数据。
2、自己计算出的数据与页面展示时调用的后端服务接口吐出来的数据做对比。这样就可以进行全口径的自动对比.
-
如何构造数据 at 2023年02月03日
-
造数 - 我的理解与落地实践 at 2023年01月31日
使用接口造数也可以,但有几个问题:
1、你使用的是上层业务结构,还是底层原子接口
2、一个业务场景的数据会涉及到多个结构,因此一个业务场景的造数,使用接口的话,会有多个接口的调用顺序与上下文管理的问题
3、如果造数在中途失败,产生的 “半截” 脏数据应该如何处理
5、接口造数,那么接口的参数如何管理和动态更新维护。
欢迎和我探讨~
-
造数 - 我的理解与落地实践 at 2022年12月16日
@Lihuazhang 申请加个精
-
造数 - 我的理解与落地实践 at 2022年12月14日
是的,易用性在一定程度上面需要提升,我也在考虑提供 SDK 来方便其他框架的调用
-
造数 - 我的理解与落地实践 at 2022年12月14日
针对第 4 点的内容:
在现在的设计中其实已经体现了:
1、数据模板中可以存在多个步骤,每个步骤根据真实情况设置具体的内容,可以是纯生成,可以是还原,等等
2、一个数据工人中可以有多个数据模板,一个生产线中可以有多个功能。随意拼搭。但在我的规划中其实还是希望在数据模板中的多个步骤之间存在语义逻辑处理,可以简单的理解为:if else 或 for 。这样可以更加灵活的处理造数过程中的逻辑

-
造数 - 我的理解与落地实践 at 2022年12月14日
我觉得你的提议很好,和我的规划有不谋而合的地方:
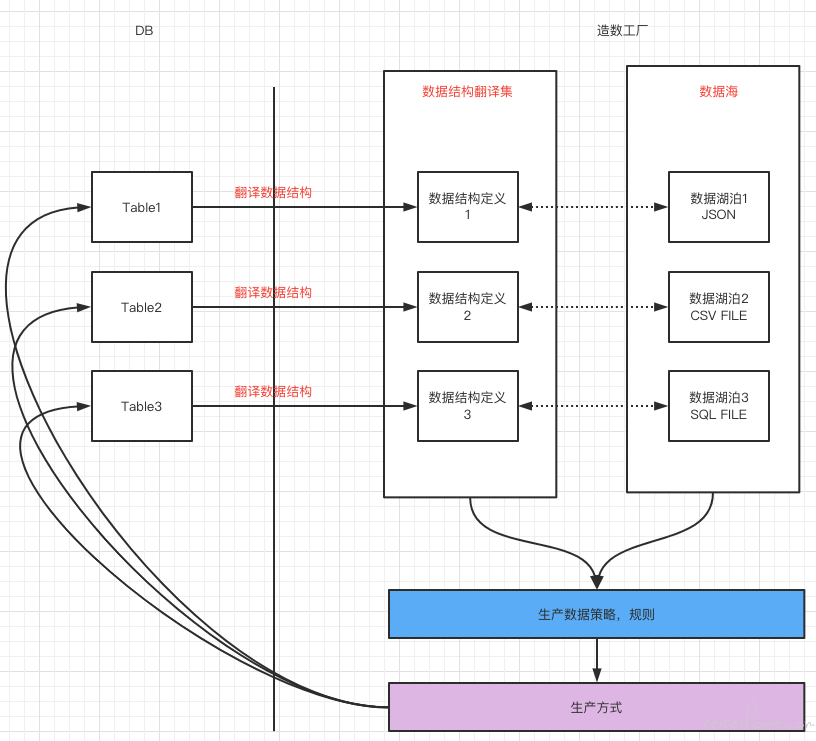
针对 “数据池”:
在现有的功能的中"变量"其实就是狭义的 “数据池”。
但我理解配合 “数据池” 的概念中还需要有两部分内容 “数据结构定义” 和 “使用策略”
在功能层面的理解更类似下图