-
第四范式 招聘 测试开发工程师 at 2018年11月02日
关于第二个职位的要求~~ 关于机器学习算法和深度学习, 也只是说了了解就可以。 有相关经验的优先。 并没说你一定要拿机器学习搞过什么高大上的事情。 因为我们这边测试的产品是一个机器学习平台。 所以了解一些机器学习的知识是加分项。 关于分布式存计算。 这块由于我们这边很多的测试场景都跟大数据相关。 所以懂大数据的,用过分布式计算框架做过事情的,肯定也是优先的。 但也没要求你精通, 只是熟悉即可。 而且这个职位面向的是 T6 T7 的岗位, 所以要求是高了一点哈。 不过也不仅仅是只招聘这么高的职位的。 大家觉得自己差不多的,都可以来试试。 我这里只是把 JD 贴过来而已
-
第四范式 招聘 测试开发工程师 at 2018年11月02日
额。。。为啥我再就不敢来。。。 我又不会吃人。。。
-
Selenium 怎么能够做到将不同的测试用例,分发到不同的平台同时执行呢 at 2018年10月15日
python 的我就不太熟悉了
-
Selenium 怎么能够做到将不同的测试用例,分发到不同的平台同时执行呢 at 2018年10月15日
利用 testng 的并发能力就可以了。 如下:
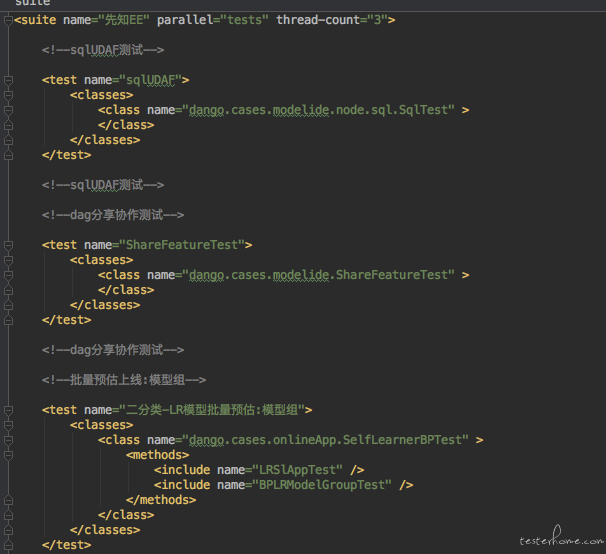
它会把不同的 case 分发到不同的浏览器上去
-
测试开发之路 -- 希望你们在新家过的更好 at 2018年09月28日
我觉得不发表意见对自己不好。 因为会太没存在感, 很难让人认可你,现在的人都喜欢能提出有价值的观点的人。 可能很多人都是没有自信吧。
-
测试开发之路 -- 希望你们在新家过的更好 at 2018年09月27日
其实你这样的想法是满正常的, 现在的人很多都背着房贷, 我也背着房贷, 而且因为要带孩子我媳妇辞去了工作。 所以家里只有我一个人挣钱。 年轻的时候跳跳曹来涨工资也是挺普遍的想法, 我觉得挺好的,也是挺现实的做法。 如果是为了钱跳槽,我个人觉得是无可厚非的。 只不过我到不会选择隐忍, 团队有不好的地方我就会指出来, 其实我再 58 的时候就是这么跟我老大闹翻后来导致离职的。 来到现在这个公司我也没改了这个脾气, 只不过这里的团队很好, 老大人也不错。 不会我因为我冒犯他就给我穿小鞋, 而我也确实比较争气, 做出了一些比较让他满意的成果,所以虽然我怼过他很多次,但是他反而更器重我了。 所以有时候我再这边还真是怼天怼地怼空气的架势,当然被怼的次数也不少。 这个看所处的团队吧和个人性格吧。我们这边是非常喜欢能提出自己意见的人,并且愿意给他们机会是实践自己的想法。
-
测试开发之路 -- 希望你们在新家过的更好 at 2018年09月27日
其实我没觉得他们浮躁, 他们走我也觉得也没啥问题,我们团队里也确实在那个时期出现了这样那样的问题,这些问题本身可能就足够导致人选择离开。
-
UI 自动化技能可能被 UI 录制替代 at 2018年09月27日
恩,大型企业软件的自动化体量和复杂度都跟是很高的。 那么多优秀的工程师都选择了自己写代码来完成自动化而不是录制回放是有原因的。 其实 ariba 在 06 年的时候就由美国的工程师 2 次开发了 selenium IDE 来完成 UI 自动化,类似楼主这样的思路的,录制回放加调优, 但是一段时间以后大部分时候 daily run 都是一两百的失败 (不稳定),每天我们 team 的人都要专门去一条一条的查看是为什么失败的,但发现绝大部分失败的 case 都不是 bug 引起的,而每天我们都得用好几个人来花起码半天的时间来一个个的查看, 实在太浪费人力,后来为了维持稳定性删除了 1000 个左右的不稳定 case,跑了一段时间后还是觉得不行。 而且录制回放生成的代码冗余度太高。有时候只是更改 UI 上的一个小需求,比如在访问较多的页面上加了一个小输入框。 就又是一两百 case 的失败,又得一个个的去改脚本,要是碰见前端重构,那就是灾难了,后来产品的前端玩起了响应式设计,后端应用了异步调用和异构的系统,一下子就更难玩了。 最后无奈之下我们放弃了这些自动化的 case, 老老实实的写代码了。 诚然录制回放可以很快的堆积起大量的 case 数量, 像是 ariba 在比较短的时间内靠着录制回放让 case 达到了数千, 但自动化从来都是创建容易维护难。 起码以目前的自动化录制工具而言,是无法应用在大型企业级产品上的。但在移动互联网玩玩小型 APP 还是可以的。 很多人是没有见过这样的复杂度所以才认为录制回放可以解决一切问题,就像很多没见过 TB 级数据量的人很难理解使用 hadoop 有啥好的,我以前一个客户都会问你们这分布式计算有什么优势么, 我问你们有多少数据量, 他说一百来万左右, 我说那没啥优势了, 可能比你跑在 mysql 里还慢呢。 其实在自动化上国外的很多企业都是领先于国内的, 他们有大量优秀的测试工程师,甚至是有多年开发经验的工程师来写自动化工具,有些场景他们没有选择使用录制回放自然是有原因的,尤其是在 TO B 的外企里,有些时候再我们眼里他们使用的技术是过时老旧的, 觉得他们都是 low b, 但就是这些 low b 搞出来的软件质量好的让咱们所有人羞愧。不是他们玩不转新技术,也不是他们故步自封。 这帮子 principle 员工里动辄就是麻省理工学院或者斯坦福出来的人, 没什么技术是他们学不会的,他们只是选择了更安全和更稳定的做法。 稳定性是大型 TO B 企业最重要的质量指标, 因为体量太大,即便是自动化测试,一个不稳定就带来很大成本。 在这里做自动化, 写那些什么登陆页面,首页等等这些基础页面的 page object 的人都必须起码是 principle 的测试开发人员。 因为这些页面太常用了,被大部分 case 使用。 如果不稳定会出现巨大的问题, 所以都由实力最强的人来写。 有些时候我们必须承认他人比我们优秀, 他们的做法比我们优秀, 不要以为他们都是傻子。
-
测试开发之路 -- 那些年总结出的学习经验 at 2018年09月24日
多谢支持~~ 这久的文章了还有人继续留言~
-
UI 自动化技能可能被 UI 录制替代 at 2018年09月21日
嗯嗯。你觉得对就行。 我们谁也说服不了谁。就此打住吧。 各自做自己觉得正确的事就好了
-
UI 自动化技能可能被 UI 录制替代 at 2018年09月21日
算了不跟你犟了,你先去大型 to b 企业里见见像样的 UI 自动化是怎么做的吧。去看看 ibm,微软这些公司怎么搞的。 就是我在一家叫 ariba 的这种小型的 to b 企业里, UI 自动化也不是你这么做的。等你理解了自动化是怎么回事以后再聊吧
-
UI 自动化技能可能被 UI 录制替代 at 2018年09月21日
楼主可以了解一下 to b 企业中动辄数百甚至数千的 UI 自动化的 case 体量下, 你这套理论还管用不管用。 UI 自动化的难点从来都不在工具上。而是代码设计能力,在 to b 企业中,面对复杂的业务逻辑,海量的测试用例,大量的异步调用和异构系统中。 如何能使用代码把业务逻辑组织起来,稳定,高效,简洁的运行下去才是难点。 并且 to b 企业中产品维护多个版本。我以前的公司同时维护 50 个版本。 50 个 UI 自动化的 daily run,并且还要对一些重要环境进行 UI 自动化的巡检。 试问构建这个级别的 UI 自动化测试,谁敢用录制回放。 都是自己哭哈哈的写代码,一个 case 的不稳定都会带来巨大的人力成本。海量的 case 下, 如果代码设计的不好,一个需求变动对测试来说都是灾难级的影响。 大量的异步调用和异构系统。需要写代码轮询数据库,中间件,各种集群来判断任务执行状态和结果。所以楼主有机会去大的 to b 企业做做看,就会有不同的收获的
-
还是删了吧,低调。有什么问题可以留言问。 at 2018年09月02日
什么情况?
-
测试开发之路--k8s 下的大规模持续集成与环境治理 at 2018年08月28日
负责用户的模块会提供 API 对用户进行 CURD 的, 其他模块是不准许直接访问其他模块的数据库的
-
测试开发之路--k8s 下的大规模持续集成与环境治理 at 2018年08月28日
我们使用 mysql,一个服务一个数据库。 微服务么, 应该都这么玩把
-
对测试人员会一点技术说句中肯的话 at 2018年08月27日
怎么说呢, 每个人成长的方式不太一样, 也可以说每个阶段的成长方式可能都是不一样的。但是土壤这个东西是在每个阶段都需要的, 即便是大牛,也需要一个土壤来发挥自己的价值。 只是对于每个人来说,土壤是不太一样的,有的人需要好的平台好的师傅来带自己,有的人需要完善流程,架构,业务来让自己专心的攻坚技术和业务。有的人则相反需要什么都不完善的情况下,为自己争取到更多了机会,因为什么都完善了,机会就相应的变少了,所以你给他特别完善的平台他反而不开心。 所以有些时候是不是好的土壤,可能在不同的人眼里看法是不一样的。
如我来说,正因为当初没有运维和研发做 k8s 的事情, 我才争取到了这个机会,虽然我之前没玩过 k8s,但是从 0 开始自学我坚持下来了。 而且自己从头一步一个坑的学来的东西和在有一个完善的体制下从别人学来的东西是不一样的。 相同的还有深度学习方向的测试 owner, 也是我花了数个月的学习后才拿到了这个机会,当初只是看到 tensorflow 的一个 roudmap 我就跑去开始学习了,但是直到提测的时候我也只是能写一个简单的 DNN 而已,是又花了近一个礼拜的时间才写出来 CNN。 如果之前就有这方面成熟的测试体系和人才的话,还轮的到我么? 如我来说,虽然当初来这的时候这里一穷二白的,没人教没人带,连 QA 也只有两个 (包括我)。但这里就是我比较好的土壤。而我也习惯了没人教没人带,靠自己学习的环境了。
-
测试开发之路--UI 自动化设计军规 at 2018年08月14日
在没有实际应用的前提下, 深度掌握 是不太可能的。 技术的深度取决于遇到问题的复杂度。 如果连问题都没有遇到过~~ 那就没什么深度造诣了
-
测试开发之路--UI 自动化设计军规 at 2018年08月14日
这个是 selenide 的方法, 就是个以 $ 命名的方法,然后用 static import 引入过来的而已
-
测试开发之路--k8s 下的大规模持续集成与环境治理 at 2018年08月13日
我们公司自己机房,自己搭建的服务
-
8.14 为了联盟 at 2018年08月13日
这是什么梗,有电影要上映还是?
-
测试开发之路--k8s 下的大规模持续集成与环境治理 at 2018年07月29日
我在第四范式工作, 有兴趣加我微信 ycwdaaaa
-
测试开发之路--k8s 下的大规模持续集成与环境治理 at 2018年07月24日
暂时没有这种强需求,但是正在调研中
-
测试开发之路--k8s 下的大规模持续集成与环境治理 at 2018年07月18日
个人准备加机会吧。 我当初也是没机会碰整个 CI 系统的。 但是我来公司早, 我是 28 号原来。我来的时候还没有运维呢。 然后我自己学习了一段时间以后就把活接了。 对于 QA 来说, 有些时候真的是个人努力加机遇。
-
测试开发之路--k8s 下的大规模持续集成与环境治理 at 2018年07月16日
就是避免环境冲突的。 有产品给客户用来演示的 demo 环境, 有给公司内部试用的环境, 有培训用的环境。 有给不同的研发团队搭建的环境。有给技术支持用来复现问题和做验证的环境。 在测试组内部也会针对不同的目的搭建不同的环境。 有做性能测试的, 有做兼容性测试的,有做功能测试的, 也有针对不同的产品版本搭建不同的环境。
-
MTSC-2017 演讲稿 -- 人工智能产品的测试探索 at 2018年07月15日
加我微信,ycwdaaaa。或者 qq 号 446051551