-
各位工作中,线上事故或者责任划分是如何? at 2026年02月10日
谁写的代码谁负主要责任。测试用例评审的时候大家就已经对其了测试范围,如果漏了那也是所有人都漏了。但如果用例没执行到位那就是测试的主要责任了
-
如何将 AI 扫描代码 应用于 CI/CD 的 at 2025年12月25日
一般每次提交代码的时候用 AI Review 吧
-
想学点东西,但不想学测试了,应该学点啥呢 at 2025年10月29日
学修理机器人
-
如何应对 35 岁乃至 40、50 的职业危机? at 2025年10月16日
先考个保安上岗证,现在能抵一点个税,以后能养老

-
糟糕的数字 at 2025年08月22日
福报
-
stagehand 有体验过的吗 at 2025年08月19日
playwright 也刚开始用,以前 cypress 用得多点,跑用例飞一样的感觉。
但感觉未来还是 playwright 的天下,因为他也很快,并且支持多语言,多浏览器,还自带并行执行,web 测试首选 -
stagehand 有体验过的吗 at 2025年08月18日
确实,体验下来,感觉这类大模型的自动化始终存在两个问题不适合在 CICD 中使用
- 不稳定性:就算这里拆成单步操作,但也会存在不确定性
- 时间长:执行时间远比直接用 playwright 长
-
stagehand 有体验过的吗 at 2025年08月15日
我是自己部署的 deepseek,跑起来没问题的
你是用 deepseek 官方的 api,还是自己部署的 deepseek 哦?我看 stagehand 底层用的 litellm,可以参考这个配置使用官方 api: https://docs.litellm.ai/docs/providers/deepseek
如果是自己的部署的,模型名字前面加 litellm_proxy/
-
stagehand 有体验过的吗 at 2025年08月15日
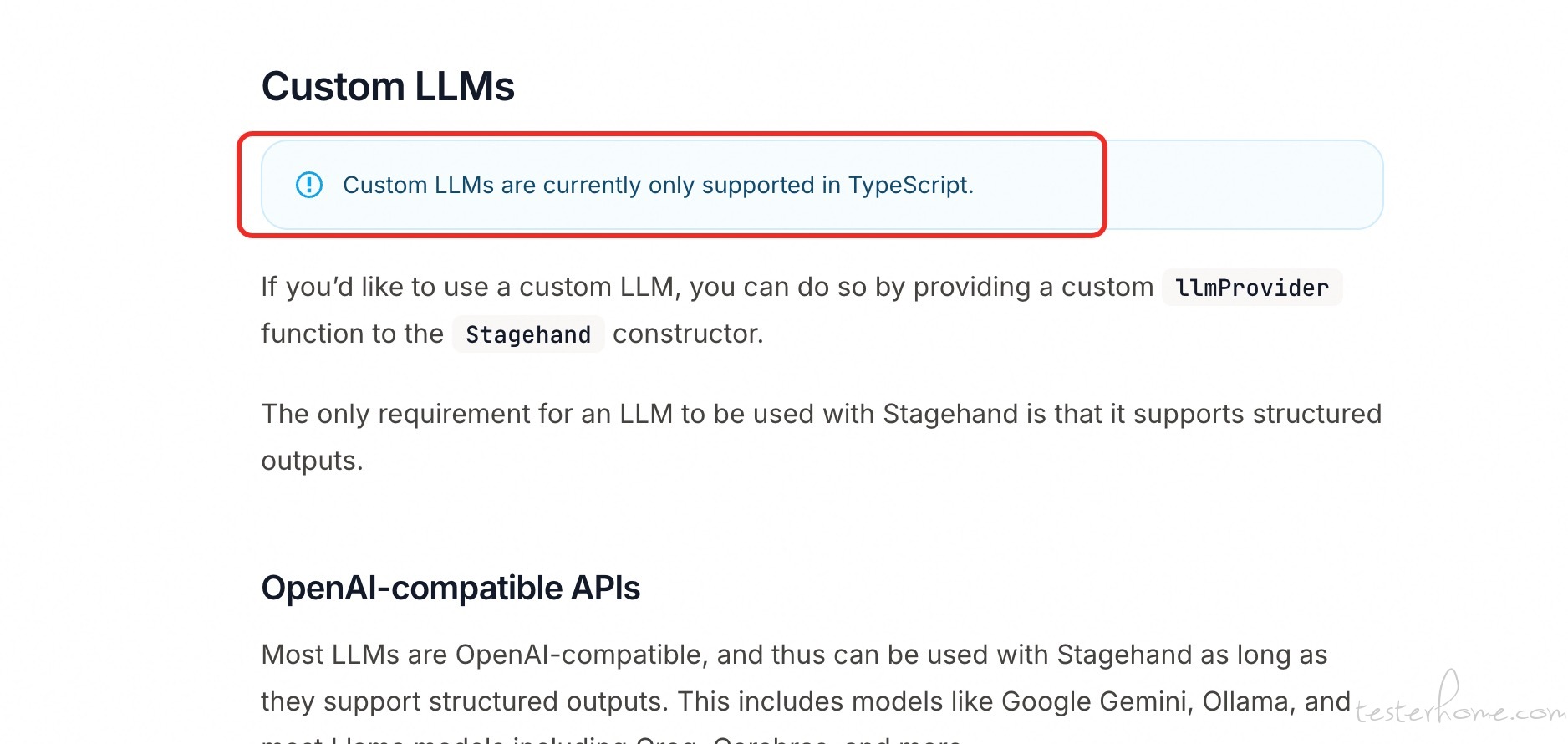
这是他文档里面写的。这里指的是自己部署的模型,不是各个官方渠道的公共模型
-
stagehand 有体验过的吗 at 2025年08月14日
看官方文档说只支持 TypeScript 配置自定义模型。试了一下 Python 也能够设置自己的模型,只是有点 hacky
config = StagehandConfig( env="LOCAL", model_name="litellm_proxy/custom_deepseek_model_name", model_api_key=os.getenv("MODEL_API_KEY") ) stagehand = Stagehand(config) stagehand.llm = LLMClient( stagehand_logger=stagehand.logger, api_key=stagehand.model_api_key, default_model=stagehand.model_name, metrics_callback=stagehand._handle_llm_metrics, api_base="https://opt.mydeepseek-inc.com/deepseek/v1/", **stagehand.model_client_options, ) -
python 读取 csv 文件出现解码失败,请问这是什么原因呢,求指点 at 2025年07月30日
按说指定了 utf8 不应该再提示 gbk 编码问题,是否有其他地方的代码在读文件,仔细看看完整的 stacktrace 看是否是这一段代码报错的呢。或者单独把这一段拿出来运行试试。
-
社区管理员召集令!跟帖回复即可 at 2025年07月29日
跟帖
-
python 读取 csv 文件出现解码失败,请问这是什么原因呢,求指点 at 2025年07月29日
看错误提示不是 gbk decoder 在解析文件吗。是不是 csv.read 也需要设置编码哦
-
到底什么是反向用例? at 2025年07月29日
各种环境异常的用例更像是稳定性测试用例的范围
-
作为测试负责人接手一个新业务,怎么干? at 2022年07月15日
又清晰又全面,赞~
-
开启移动专项之旅 (android 客户端性能-cpu) at 2016年08月16日
后台持续占用,直接 traceview 拉一把 trace 不就知道了吗
-
Android 性能测试实践 (四) 流量 at 2016年04月13日