-
图像分类、AI 与全自动性能测试 at 2019年08月27日
这种属于业务逻辑,它只负责把阶段区分开
-
图像分类、AI 与全自动性能测试 at 2019年08月27日
其实这种很大程度上跟怎么拍的视频有关系
-
图像分类、AI 与全自动性能测试 at 2019年08月15日
留个联系方式吧.. 这样沟通效率太低

-
图像分类、AI 与全自动性能测试 at 2019年08月13日
内置的话是的。如果要对 cutter 保存的图片进行图像分类,你也可以用其他你喜欢的(例如 keras)。
-
再次利用图像识别与 OCR 进行性能测试 at 2019年08月06日
我觉得用这个可能好一点
https://testerhome.com/topics/19978 -
让所有人都能用图像识别做 UI 自动化 at 2019年08月02日
这个项目没有涉及电脑与手机的概念,只有目标图片与模板图片两种,不太明白你说的转换成手机坐标是指什么?
应用在手机上的话,可以参考这个项目:https://testerhome.com/opensource_projects/https---github-com-williamfzc-fitch -
图像分类、AI 与全自动性能测试 at 2019年07月30日
是什么商业软件能透露下吗

-
图像分类、AI 与全自动性能测试 at 2019年07月30日
是的,如果要精确一般都是通过摄像头来确保帧率的稳定。软件层面的话,至今我也没找到一个很好的解决方案。
-
图像分类、AI 与全自动性能测试 at 2019年07月30日
是有的,我感觉跟录制的方式也有关。像是手机摄像头、高速相机就比较正常,软件方式录制出来的视频就怪怪的。
-
图像分类、AI 与全自动性能测试 at 2019年07月29日
加了你 QQ~
-
图像分类、AI 与全自动性能测试 at 2019年07月29日
首先呢,设计的初衷是希望能尽可能找出所有分类的,因为需求不唯一,例如有些人的测试主体就是轮播图。在此基础上,开发者可以通过修改配置来定制自己的功能。
如果要拟合的话,有两种方式:
- 降低阈值,使得轮播过程不被认为处于变化中。但这种方式会影响其他阶段的识别,并不推荐
- 手动调整切割结果,重新训练模型。
正常切割之后会生成一系列分类好的图片,如果你希望将 2 阶段与 3 阶段拟合,你可以将 3 中的图片丢到 2 中,然后将 3 文件夹删除。这样做之后分类器会将他们分为同一类。
当然,这个过程显得很不智能。但是在训练完成后,你大可以将训练好的模型保存下来。以后你可以直接用这个模型来分析视频,而无需前置的切割过程。
-
图像分类、AI 与全自动性能测试 at 2019年07月29日
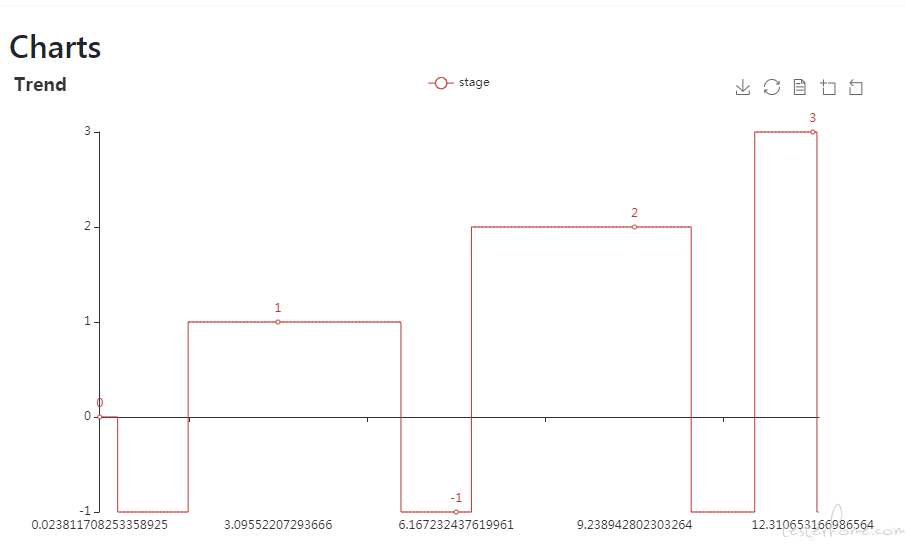

轮播图是可以的。图好像被压缩了,传不了 html 将就着看看吧

补两个大图
-
图像分类、AI 与全自动性能测试 at 2019年07月29日
能举个例子吗?因为动态加载这个概念还挺泛的,我不知道你具体指的是哪一种
-
图像分类、AI 与全自动性能测试 at 2019年07月25日
既然所有的信息都来自于视频,那么这个工具自然是不可能得到超出这个视频的信息。所以你提到的内因确立不属于这个工具的范畴内了。当然,以 android 为例,你可以在录制过程中同步记录日志去进一步定位问题所在,或者别的你喜欢的方式。
可以从导出的视频中,找到哪里可能存在性能问题吗?
用途的话,在上面的应用举例应该说得挺清楚的,这取决于你怎么使用了。性能方向的话我觉得比较适合做性能数据采集跟 benchmark,定位问题的话光视频不是很够。最好是跟 app 自身的埋点或者日志结合起来用。
-
图像分类、AI 与全自动性能测试 at 2019年07月25日
动画是个比较难解决的问题,现在的容错机制可以满足一些比较常规的动画(例如跑马灯)。
如果应用页带有比较复杂的动画(例如有视频插入),最佳方案还是手动采集一些图片去训练模型,然后再用模型来分析视频。 -
让所有人都能用图像识别做 UI 自动化 at 2019年07月24日 很好的思路,之前有稍微考虑过但是在选型这一块没决定好,后面再看看吧~
-
图像分类、AI 与全自动性能测试 at 2019年07月24日
这完全取决于训练集的大小跟你选择的特征。
现在的 SVM 分类器用的是 sklearn 的版本,理论上性能与 sklearn 是一致的,我没有测过 GPU 的(对于单视频来说训练速度已经很快了,感觉没有测的必要),你可以试试看呢。https://scikit-learn.org/stable/modules/classes.html#module-sklearn.svm -
基于图像识别的 UI 自动化解决方案 - FITCH at 2019年07月24日
这个是 warning 忽略就好了
里面内置了 OCR 模块,如果要用的话要装 tesseract 的 -
图像分类、AI 与全自动性能测试 at 2019年07月23日
-
再次利用图像识别与 OCR 进行性能测试 at 2019年07月07日
加你 QQ 啦,大概率是因为传入高精度图片或者一次加载了太多模板图片,暂时还没解决这个问题
-
再次利用图像识别与 OCR 进行性能测试 at 2019年07月04日
嗯嗯,这一块的话我是觉得现在还做得不够好,有些问题还没有解决,所以没写太多。
等解决楼上提的问题之后可能慢慢会开始写一些实践 -
再次利用图像识别与 OCR 进行性能测试 at 2019年07月04日
感谢耐心,卡住这个问题我知道的,不过我还没注意放久了居然可以跑完
具体方案我在 github 上回你啦,谢谢反馈已经建了 issue 跟踪:https://github.com/williamfzc/stagesep2/issues/7
-
让所有人都能用图像识别做 UI 自动化 at 2019年06月10日
- 我不觉得很低哈,如果是内部项目做简单适配我觉得没毛病,作为公开项目要适配全引擎我觉得工作量太大。
- 当然做游戏的 UI 自动化当然以操作控件 Object 为上策哈,这个我不反对,也欢迎你把上面提到的开源方案分享出来学习下。但是业界会流行图像识别另一方面的原因是,我们一度怀疑这种 object 断言是否真正能够代表了界面的渲染效果。这是 airtest 一直很火热的原因。另外,这个项目并不只是针对游戏来做的,这里就不再过多地具体讨论游戏细节了。
- 特征提取方面后面会有改动,但是最近没有时间。
- 模板匹配方面并没有牺牲正确性啊,为什么会有这个想法
-
让所有人都能用图像识别做 UI 自动化 at 2019年06月10日
模板匹配做了很多适配用来提高鲁棒性,目前面对不同分辨率的识别效果并不差了。
你可以看看这个项目的特征匹配就是用的 SIFT/SURF 来做的,实际上效果不一定比优化后的模板匹配来得更好。
你说的 gameObject 取件需要引擎商配合或提供方法,而我们不可能要求所有引擎商都配合。