Selenium python HTMLTestRunner 中文乱码
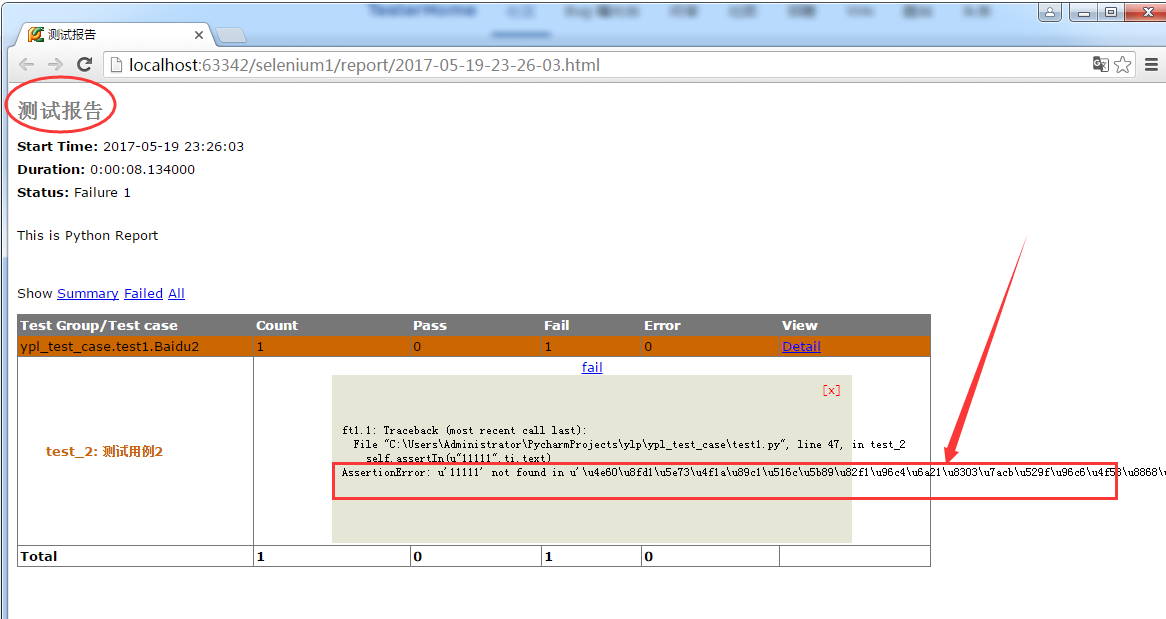
参考网上的方法,在 HTMLTestRunner 源码乱码设置为 utf-8 编码格式,测试报告的标题可以写中文,但是用例断言失败后打印的依然是乱码,求解。怎样才能让断言异常也能输入中文
用的是 python2.7,运行脚本如下:
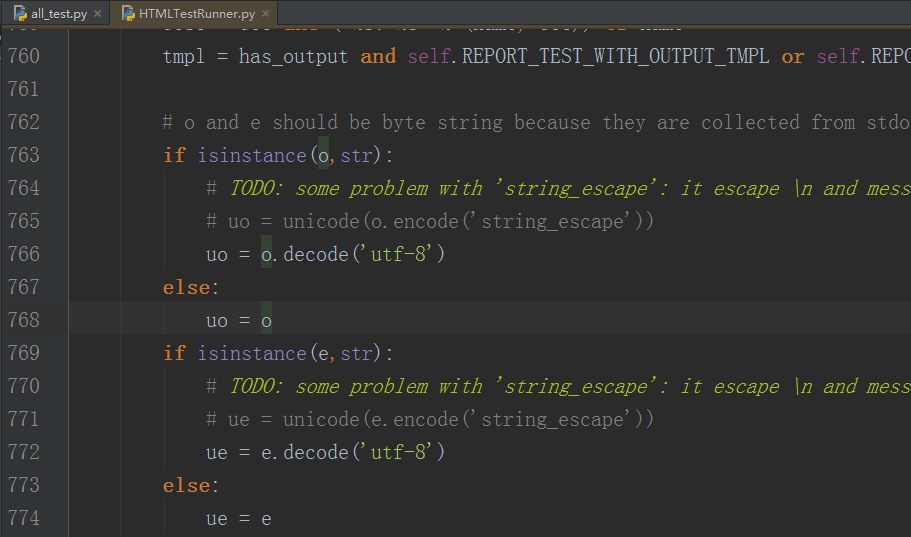
这个需要修改HTMLTestRunner.py里面错误输出进行转码:
773 行左右
if isinstance(o, str):
# TODO: some problem with 'string_escape': it escape \n and mess up formating
# uo = unicode(o.encode('string_escape'))
uo = o.decode('utf-8')
else:
uo = o
if isinstance(e, str):
# TODO: some problem with 'string_escape': it escape \n and mess up formating
# ue = unicode(e.encode('string_escape'))
ue = e.decode('utf-8')
else:
ue = e

我已经设置 utf-8 了。还是乱码。
browser.find_element_by_link_text(u"新闻").click()
sleep(2)
ti=browser.find_element_by_xpath("html/body/div[3]/div[1]/div[1]/div/div[3]/div[1]/div/ul")
self.assertIn(u"11111",ti.text,u"失败了")
我的断言脚本就是进入百度首页,点击新闻,然后判断网页上的文本,断言是我估计让它失败的。但是失败后打印的信息在 HTML 报告或者 pycharm 控制台都是乱码。
 简单的方法是错误原因不加 u...
简单的方法是错误原因不加 u...
def test_112(self):
'''testdesc2'''
print u'测试一下2'
self.assertTrue(False, '错误信息')
加了 u 之后错误信息转码忒复杂,没搞粗来
if isinstance(e, str):
# TODO: some problem with 'string_escape': it escape \n and mess up formating
# ue = unicode(e.encode('string_escape'))
ue = e.decode('gbk', 'ignore')
个人觉得这个不是乱码,而是你的文字是以 unicode 编码值的形式显示出来了。乱码一般是说用了错误的解码器解码,例如用 gbk 解码 utf-8 ,一般特征是长得像火星文,各种未见过的生僻字。你可以在 http://tool.chinaz.com/tools/unicode.aspx 做一下转换,就会发现实际上显示的就是你想用的中文,只是显示形式不对。
我目前了解的会出现这种情况的场景,是用了 repr 方法解析 unicode 字符串:
unicode_str = u'中文'
# 这样就会显示 u'\u4e2d\u6587'
print repr(unicode_str)
建议可以在 if isinstance(e,str): 和 if isinstance(o,str): 加个断点,看下此时中文是否已经变成了 unicode 编码值?
用 py3.x 吧。2.7 已经是历史的遗迹了
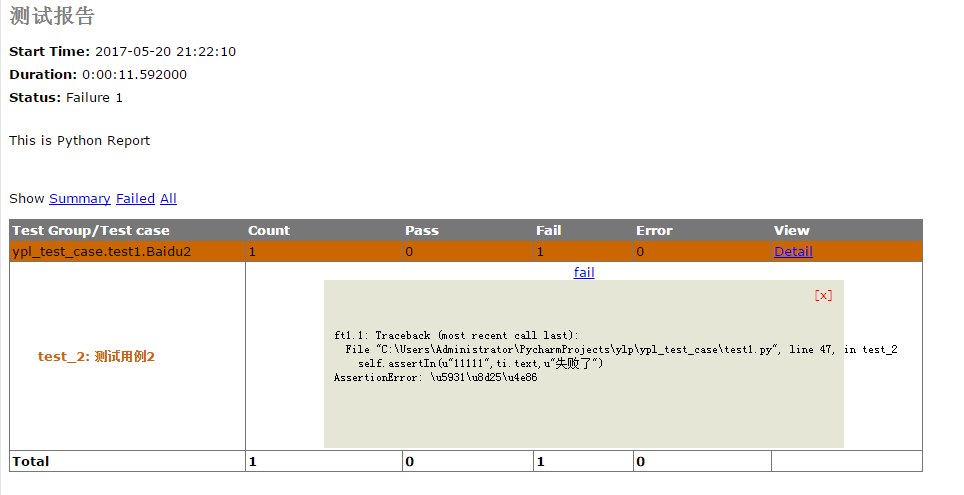
self.assertIn(u"11111",ti.text,"失败了")
这样写确实可以打印中文了,如下图:
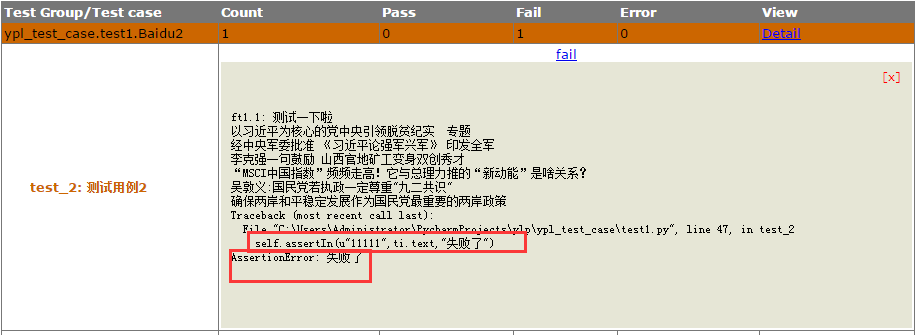
但是如果没有写附加信息时,抛出的异常全是 unicode 编码,怎么破,如下图:

如果文件头使用的 utf-8,建议修改 Python 的默认 encoding 为 utf-8,应该能解决问题。
import sys
reload(sys)
sys.setdefaultencoding('utf8')

啊,被楼上妹子炸出来了,最近想到一个解决方案对字符串编码区分处理
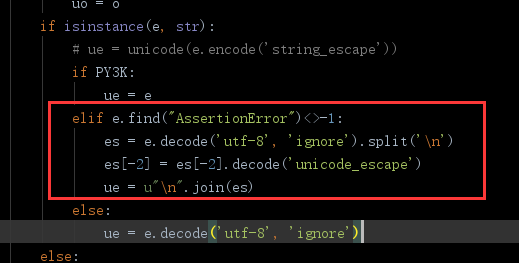
用例:
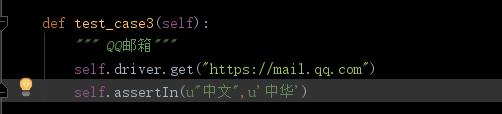
效果:
