title: Python 网络爬虫 (二)
date: 2016-04-13 12:47:44
tags: Python
< Hi , 大家好,我是 Raymond 。 应广大同学要求, 今天加更一波。 有没有 surprise ! >
承接上一章 ,回顾一下上节内容
练习一:
获取任意 TesterHome 的文章 (这里用上一章的 url 地址)
import requests # 导入requests模块
request_url = 'https://testerhome.com/topics/4621' # 请求的url是 上一章的url地址
response = requests.get(request_url).text # 请求并返回结果
print(response) # 打印返回结果
如果你熟练掌握了这一步, 那么,我想如果没有一些 python 爬虫基础的话, 爬取知乎的时候,我猜你肯定遇到困难了。
别着急,我们来简单的学习一些 html 的解析, 从而完成知乎的爬取吧。
BeautifulSoup4 模块
Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup 会帮你节省数小时甚至数天的工作时间.
传送门 :BeautifulSoup4
这个模块的主要作用,是将我们抓取回来的 html 解析之后,提取出有效的数据进行存储。
Python Re 模块
正则表达式(RE)模块的功能主要是设置一个字符串并搜索其中的字串;这个模块的功能让你检查一个特定的字符串,匹配给定的正则表达式(或正则表达式匹配特定的字符串,它可以归结为对同样的事情,一般情况下,NFA 引擎是由表达式主导,而 python 的 re 正是 NFA 引擎,从引擎的机制上来描述,应该是理解为拿正则表达式匹配特定的字符串;DNF 引擎反之,详细可参考精通正则表达式一书关于正则引擎的章节)。
传送门 :Python Re
我们在这里不对 Re 和 BeautifulSoup 这两个模块进行比较 , 我们先从最简单的 BeautifulSoup 的 Html 解析开始
第一次使用 BeautifulSoup4
我相信大家在看 Bs4 的中文文档的时候, 也上手进行了编码 ,那么,快点开始吧!
首先! ,我们将昨天的代码拿出来改一下
import requests # 导入requests模块
from bs4 import BeautifulSoup as bs # 从bs4 模块中导入BeautifulSoup模块并命名为bs
request_url = 'https://testerhome.com/topics/4621' # 请求的url是 上一章的url地址
response = bs(requests.get(request_url).text , 'lxml') # 返回一个bs对象 ,格式为lxml
print(response) # 打印返回结果
好的, 我们成功的接受到返回的页面,现在这个返回的对象, 类型是 bs 对象的类型,我们对返回的 html 进行解析
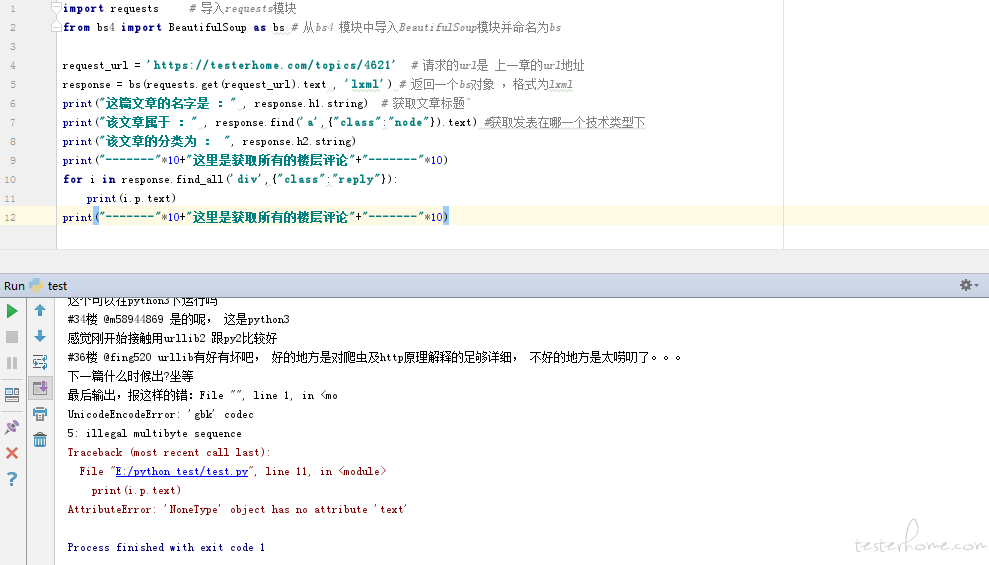
import requests # 导入requests模块
from bs4 import BeautifulSoup as bs # 从bs4 模块中导入BeautifulSoup模块并命名为bs
request_url = 'https://testerhome.com/topics/4621' # 请求的url是 上一章的url地址
response = bs(requests.get(request_url).text , 'lxml') # 返回一个bs对象 ,格式为lxml
print("这篇文章的名字是 :" , response.h1.string) # 获取文章标题˜
print("该文章属于 :" , response.find('a',{"class":"node"}).text) #获取发表在哪一个技术类型下
print("该文章的分类为 : ", response.h2.string)
print("-------"*10+"这里是获取所有的楼层评论"+"-------"*10)
for i in response.find_all('div',{"class":"reply"}):
print(i.p.text)
print("-------"*10+"这里是获取所有的楼层评论"+"-------"*10)
# 见证奇迹的时刻到了!
运行一下代码,看看结果如何!
这篇文章的名字是 : Python 网络爬虫 (一)
该文章属于 : 其他测试框架
该文章的分类为 : tags: Python
----------------------------------------------------------------------这里是获取所有的楼层评论----------------------------------------------------------------------
是准备用 urllib 还是直接用 scrapy 啊
#1 楼 @jphtmt 不用框架, 自己写轮子,后续讲分布式,这部分其实主要的用意是让大家写出 pythinic 的代码 , 熟悉并习惯 python 的代码形式
#2 楼 @raymond 那解析呢,用 bs4?这些天一直在尝试写一个爬虫,卡在验证码了
#3 楼 @jphtmt 验证码部分现在通常的做法是将验证码拉回本地,手动输入,如果你想程序自动识别图像,这个太困难了
#4 楼 @raymond 我就是拉回本地的, 但是手动输入后就出了问题
#5 楼 @jphtmt 可否发给我看一下
#6 楼 @raymond 代码还在远程服务器上,得回去找找,希望能写个处理验证码的例子,嘿嘿
#7 楼 @jphtmt 下一章会放两部分的爬虫内容, 一个是 html 的简单解析,第二部分,是应用的模拟登录, 你说的内容, 可能会在第三章中放出来, 结合第二章的内容, 用 python 实现登陆 TesterHome
#8 楼 @raymond 好,我之前尝试的是豆瓣,我找时间尝试下登录 testerhome 试试
感谢楼主的技术分享,小白第一步就卡住了,py2.7 并不包含这些模块,可否另开一个传送门引导?
#10 楼 @jamesparagon pip 大法
#9 楼 @jphtmt TesterHome 的登陆, 有_xsrf 验证 包含了 bs4 的解析模块还有你提到的验证码
#12 楼 @raymond 嗯, 我看到了,知乎也采用了 xsrf 验证,每次抓取 xsrf 值就好了吧
#10 楼 @jamesparagon requests 需要安装,pip 一下吧
#13 楼 @jphtmt 对 每次登陆获取一次就好了。前两天我还在群里说。。TesterHome 的登陆验证方式,和知乎很相似啊
成功了,不过小白作死尝试了一下 www.baidu.com 电脑直接蓝屏了
给煎饼怂恿下这么快就出来了,把一系列的都写出来吧,看样子不错
#17 楼 @darker50 哈哈, 好的, 得向煎饼多学习 , 这套系列 预计是分 5 章写完, 初级的 python 爬虫造轮子系列
zan
你这文章这么短, 差评啊.
#20 楼 @seveniruby 不短点留点神秘,怎么拉起人的好奇心呢
#21 楼 @raymond 作业已完成 期待老师的新课
#17 楼 @darker50 哈哈,幸福
坐等连载~
#24 楼 @jianjianjianbing 嘿嘿。这部分还是比较简单的,后面如果大家都感兴趣,再开一片多线程消息队列的
#23 楼 @jianjianjianbing 下次看你分享,你懂的好像更多。
已关注大神,默默等待更新
期待更新,一直想尝试爬虫
慕课网有 nodejs 写的爬虫
期待后续内容
----------------------------------------------------------------------这里是获取所有的楼层评论----------------------------------------------------------------------
既然我们已经了解 Bs 模块, 那么大家或许在昨天的练习中发现,获取知乎的文章,好像需要登陆啊?可是。。我们如何登陆呢? -- 这是一个问题啊!
通过 Python 进行一次简单的登陆行为
话不多说, 上代码
import json
import requests
#这是基于闪送app的api实现的模拟登陆
def login():
get_cookies = 'http://www.ishansong.com/web/admin/order/list'
r = requests.get(get_cookies)
cookies = r.cookies
headers = {
"Host":"www.ishansong.com",
"Origin":"http://www.ishansong.com",
"Referer":"http://www.ishansong.com/user/login",
}
url = 'http://www.ishansong.com/user/doLogin'
data = {"service":"","tab":"tab2","username":xxxx,"password":xxxx}#注册后,在这里把username、password的参数修改成自己的用户名和密码即可
r = requests.post(url ,data = data ,headers = headers , cookies = cookies )
print (r.text)
if __name__ =='__main__':
login()
根据我们上一章所讲,在 requests 模块中用到 post 方法,并实现登陆完成 ,大家需要多练习。
那大家肯定问我,为什么会知道登陆成功了呢?
很简单啊 你用 Bs4 模块解析一下这个返回的 html 看看是不是成功了呢 ?
留下一些练习:
- 使用 bs4 对闪送 app 进行解析
- 尝试使用 requests 方法 获取一张图片 (可以但不限于,把图片保存在本地)
那么今天我们分享的内容就到这里啦
希望大家多多练习!
再进行代码编写的时候,如果遇到问题,要及时查看官方 Api 以及 Google ,这里我们就不对模块的使用进行深入解析了,如遇到问题 可在 TesterHome 官方测试群中 @BJ-行者