其他测试框架 [已解决] 根据 raymond 大神的 python 爬虫写的作业,有两个问题请教!
@raymond 大神的文章https://testerhome.com/topics/4637
原文是 2016 年时的,现在按照文章中的代码就找不到同一个标签了,于是又写了一遍。
写完后有两个问题,怕时间久远大神没有关注原贴,重新发帖,如果有明白的童鞋也希望不吝赐教!
# -*- coding: utf8 -*-
import requests
from bs4 import BeautifulSoup as bs
request_url = 'https://testerhome.com/topics/4621'
#response = requests.get(request_url).text
response = bs(requests.get(request_url).text, 'lxml') #返回一个bs对象,格式为lxml
print("这篇文章的标题是:",response.h1.text)#文章标题
#print("这篇文章属于话题:",response.find('a',{"class":"node"}).text)#文章分类
print("这篇文章属于话题:",response.h1.span.text)#文章分类,两种方法都可以找到分类
print("这篇文章的作者是:",response.find('a',{"class":"user-name"}).text)#作者名字
print("----------这是获取所有的文章评论----------")
for i in response.find_all('div',{"class":"reply"}):
print(i.p.text)
print("----------获取所有的文章评论完毕----------")
问题 1:获取文章标题时,通过 text 拿出来的结果是其他测试框架 Python 网络爬虫 (一),希望只取到Python 网络爬虫 (一),不知道怎么办到。截取源码:
<div class="navbar-topic-title">
<a href="#" class="topic-title pull-left" title="Python 网络爬虫 (一) " data-type="top">
<h1><span class="node">其他测试框架</span> Python 网络爬虫 (一) </h1>
</a>
</div>
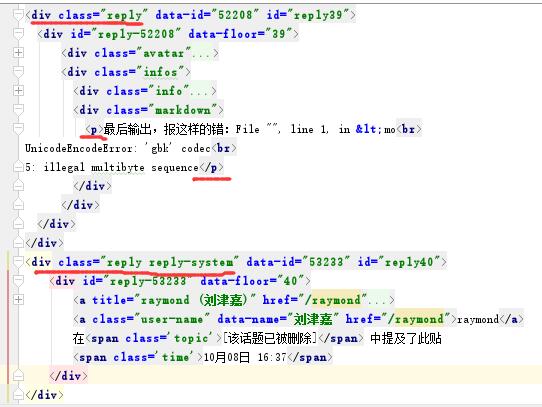
问题 2:最后取到的评论到 39 楼就停止了,截取部分评论结果和报错:
#36楼 @fing520 urllib有好有坏吧, 好的地方是对爬虫及http原理解释的足够详细, 不好的地方是太唠叨了。。。
下一篇什么时候出?坐等
最后输出,报这样的错:File "", line 1, in <mo
UnicodeEncodeError: 'gbk' codec
5: illegal multibyte sequence
Traceback (most recent call last):
File "C:/pyspace/pachong/test_pachong.py", line 14, in <module>
print(i.p.text)
AttributeError: 'NoneType' object has no attribute 'text'
我看 39 楼(5: illegal multibyte sequence)后是一个 class:"reply reply-system"的标签 “raymond 在 [该话题已被删除] 中提及了此贴”,可是 class 不一样,应该可以跳过的啊?为什么会报错呢?
为了好观察,把源码整理成以下:
----------------------------------------------解决手动分隔线-----------------------------------------------------
问题 1:
文章名字 name=response.find('a',{"class":"topic-title pull-left"})["title"]
问题 2:
由于删除状态那句话的class="reply reply-system",也就是说 reply 也是匹配的,这样的 p 标签是没有的,也就是 i.p 是可能为空的,不为空的才是我们想要的。所以加一个 if 判空语句。
最终修改为以下代码:
# -*- coding: utf8 -*-
import requests
from bs4 import BeautifulSoup as bs
request_url = 'https://testerhome.com/topics/4621'
response = bs(requests.get(request_url).text, 'lxml') #返回一个bs对象,格式为lxml
name=response.find('a',{"class":"topic-title pull-left"})["title"]
print("这篇文章的名字是:",name)
print("这篇文章属于话题:",response.h1.span.text)#文章分类
print("这篇文章的作者是:",response.find('a',{"class":"user-name"}).text)#作者名字
print("----------这是获取所有的文章评论----------")
for i in response.find_all('div',{"class":"reply"}) :
if i.p != None:
print(i.p.text)
print("----------获取所有的文章评论完毕----------")




