AI测试 深入解析 Open-AutoGLM:AI 驱动的手机 Agent 及其在移动应用测试领域的实战应用
引言:Open-AutoGLM 与移动 Agent 技术浪潮
随着大型语言模型(LLM)与多模态能力的飞速发展,AI Agent 已从单纯的文本生成者,进化为能够感知环境、自主决策和执行复杂任务的控制中枢。Open-AutoGLM(特指 AutoGLM-Phone-9B 模型)正是这一趋势下的产物,它专注于手机自动化控制,旨在通过理解自然语言指令,结合手机界面的多模态信息(屏幕截图、UI 结构),自主规划并执行操作,实现对真实 Android 设备的控制。
本文将深入探讨 Open-AutoGLM 的核心机制,提供在不同硬件平台(Apple M2 与 NVIDIA H800)上的清晰格式化部署命令行,并通过 “港话通” AI 助手测试的详细操作日志,展现其作为下一代自动化测试工具的实战能力与过程细节。
I. Open-AutoGLM 的核心机制:“感知 - 思考 - 行动” 闭环
Open-AutoGLM Agent 的工作流基于经典的 **“感知 - 思考 - 行动”** 循环,使其能够像人类用户一样与手机界面进行交互。
- 多模态感知: Agent 通过 ADB 获取手机的屏幕截图、UI 结构(XML 元素树,提供控件的结构化信息和位置)和前台 Activity 信息。这些信息连同用户的自然语言指令一起作为模型输入。模型支持视觉 - 语言多模态编码,会结合截图画面和 UI 文本内容进行理解。
-
智能决策规划: 模型收到输入后,先在内部生成一个思考内容,推理用户意图和完成任务所需的步骤。例如,对于 “打开淘宝搜索蓝牙耳机按价格排序” 的复合指令,模型会规划出启动、点击搜索框、输入关键词、切换排序等一系列步骤。模型把这一系列步骤以文字形式理清(通常在
<think>标签中体现)。 -
操作指令输出与执行: 模型接着会在
<execute>标签中给出具体的 JSON 格式动作指令,通过 ADB 对手机执行操作。Agent 支持点击 (Tap)、滑动 (Swipe)、输入文字 (Type)、启动 App (Launch)、返回 (Back)、Home 键、长按、等待加载以及请求人工接管等动作。
每执行一步动作,Agent 都会重新感知界面变化,进入下一轮决策循环,直到任务完成。
II. 部署实战: Mac M2 本地 vs. H800 服务器(命令行格式化处理)
部署环境的选择直接决定了 Agent 的响应速度和规模化能力。我们详细展示 Mac M2 本地部署和 NVIDIA H800 服务器部署所需的关键命令行。
1. Apple M2 (MLX) 本地部署:量化与启动
本地部署利用 Apple Silicon 芯片和 MLX 框架。该方案注重数据隐私和成本控制。由于模型原始大小约 20GB,本地部署必须进行 4-bit 量化以适应有限的内存(16GB 内存的 Mac 可运行量化后的 6.5GB 模型)。
A. 环境准备与 MLX 框架安装
首先克隆项目并安装 MLX 及其依赖,包括多模态推理库 mlx-vlm。
# 克隆 Open-AutoGLM 项目并进入目录
git clone https://github.com/zai-org/Open-AutoGLM.git && cd Open-AutoGLM
# 安装 MLX、多模态推理库 mlx-vlm、PyTorch 和 Transformers 等依赖
pip install mlx "git+https://github.com/Blaizzy/mlx-vlm.git@main" torch torchvision transformers
# 安装项目其它依赖
pip install -r requirements.txt && pip install -e .
B. 模型下载与 4-bit 量化(关键步骤)
为在本地运行,需要从 Hugging Face 下载模型并执行量化转换。量化能将模型大小从约 20GB 大幅缩减至约 6.5GB。
# 安装 Hugging Face 命令行工具
pip install -U "huggingface_hub[cli]"
# 下载 AutoGLM-Phone-9B 模型(支持断点续传)
huggingface-cli download --resume-download zai-org/AutoGLM-Phone-9B \
--local-dir ./models/AutoGLM-Phone-9B
# 执行 4-bit 量化转换(需 15~20 分钟),生成新的 MLX 格式模型
python -m mlx_vlm.convert --hf-path ./models/AutoGLM-Phone-9B -q --q-bits 4 \
--mlx-path ./models/autoglm-9b-4bit
C. 启动本地推理
使用 --local 参数启动 MLX 本地推理模式。
# 启动交互模式,可连续输入多条指令
python main.py --local --model ./models/autoglm-9b-4bit
# 或直接执行单条指令
python main.py --local --model ./models/autoglm-9b-4bit "打开微信"
2. NVIDIA H800 (PyTorch + CUDA) 服务器部署:速度与并发
GPU 服务器部署提供了卓越的推理速度(比 M2 快 7–8 倍)和高并发能力,适合企业级自动化测试平台。由于 H800 显存充足(80GB),我们直接使用 FP16 全精度运行。
A. 部署 vLLM 推理服务
推荐使用 vLLM 等高性能推理引擎部署兼容 OpenAI API 的服务。
# 确保安装了 vLLM (如果未安装 PyTorch 环境,需要先安装)
pip install torch torchvision transformers vllm
# 启动 vLLM API 服务器(加载 FP16 全精度模型,开放 8000 端口)
python3 -m vllm.entrypoints.openai.api_server \
--model zai-org/AutoGLM-Phone-9B \
--served-model-name autoglm-phone-9b \
--max-model-len 25480 \
--mm-encoder-tp-mode data \
--mm_processor_kwargs '{"max_pixels":5000000}' \
--port 8000
B. 客户端连接远程服务
在 Mac 或其他客户端上,通过指定 --base-url 参数连接到远程 GPU 服务器上启动的模型服务。
# 连接远程 vLLM 服务执行指令
python main.py --base-url http://服务器IP:8000/v1 --model autoglm-phone-9b "打开淘宝搜索蓝牙耳机按价格排序"
III. 实战 Demo:Open-AutoGLM 作为测试工程师(日志解析)
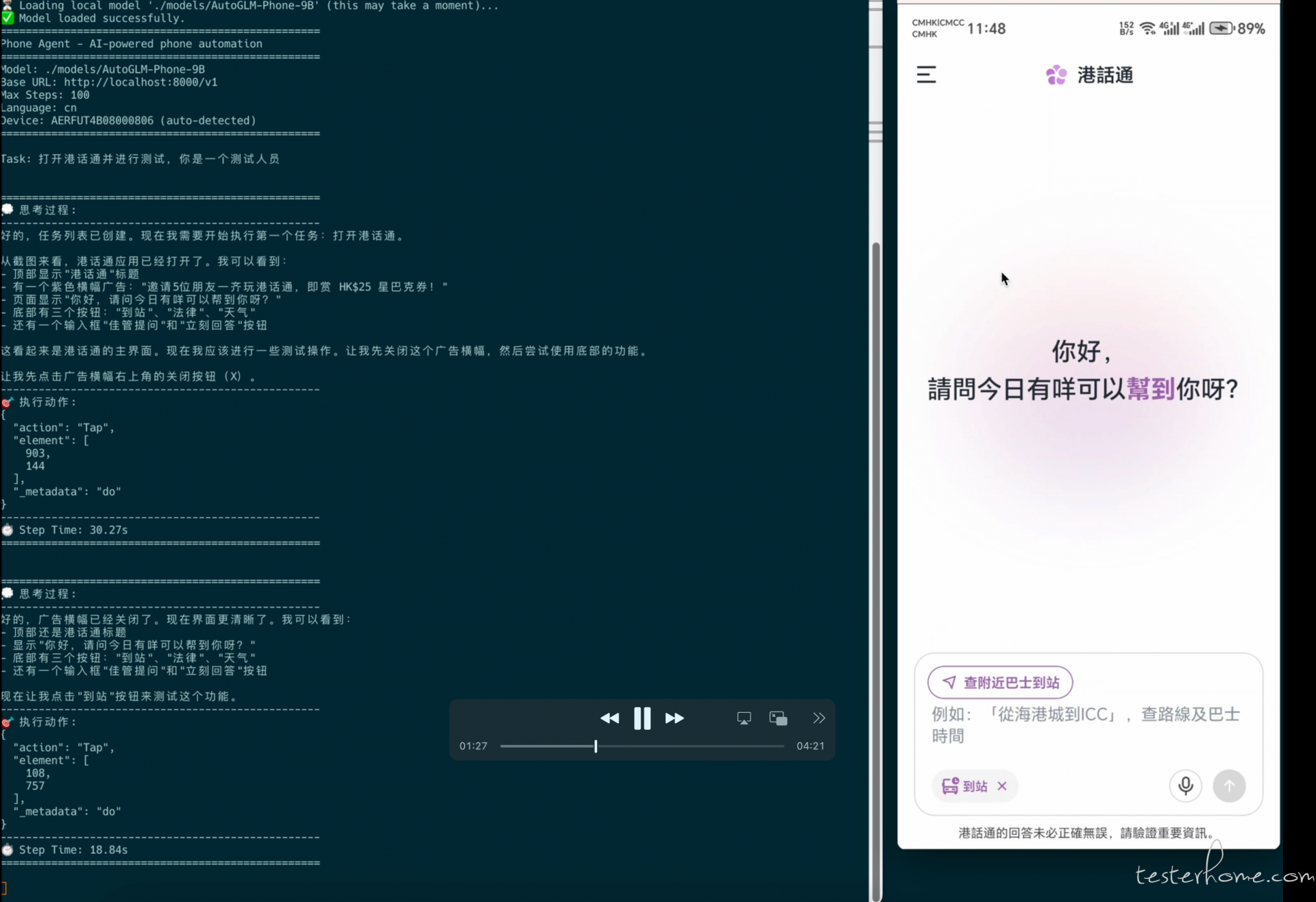
这是本地模型测试结果效果结伴都是 10 多秒的等待:
h800 的远程访问效果基本上几秒完成:
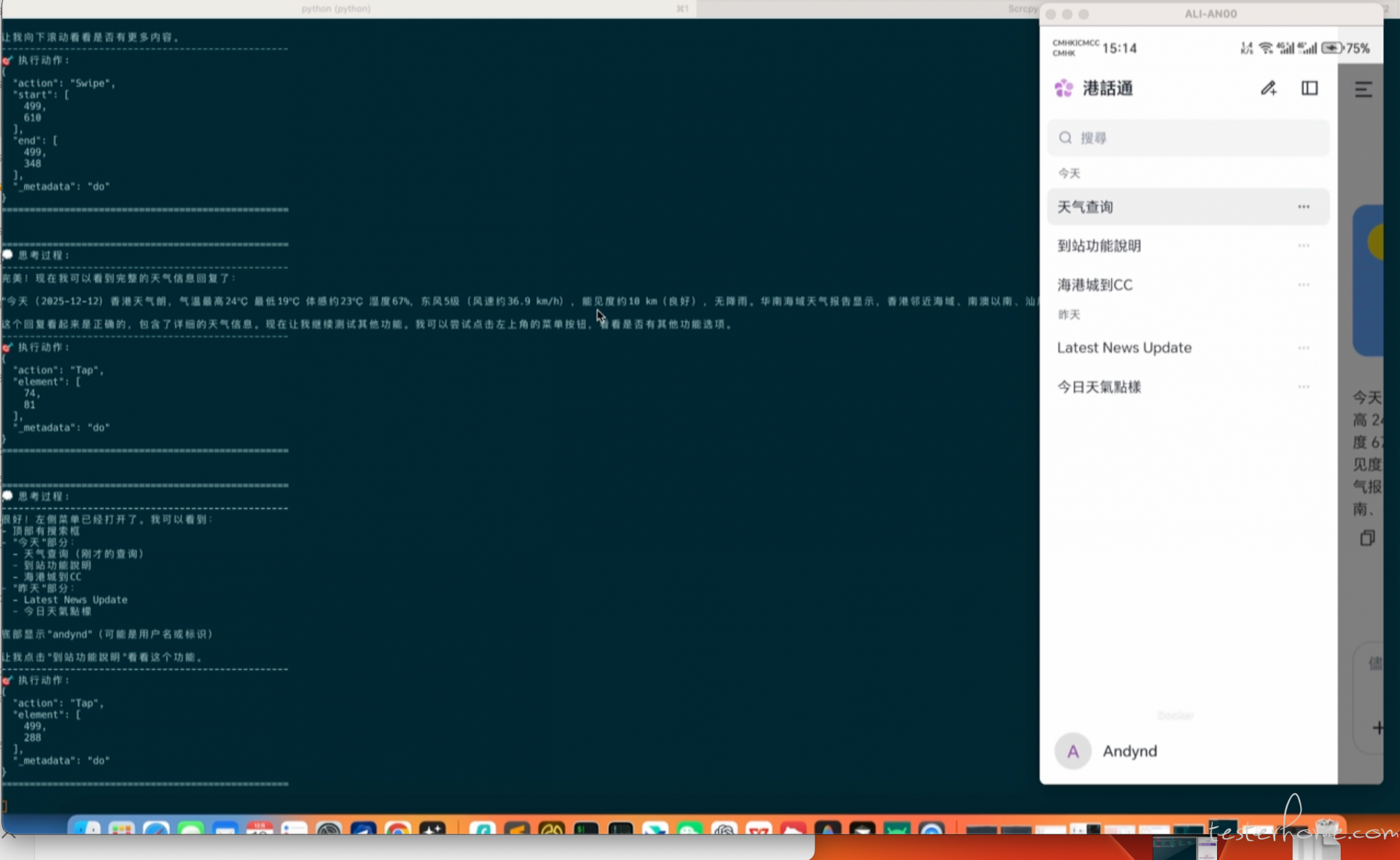
我们利用 Open-AutoGLM 框架,指定其扮演 “大模型测试工程师” 的角色,对 “港话通” AI 助手应用进行全面功能测试。
1. 启动测试任务的命令行(远程服务)
该命令将任务指令(包括测试目标和 Bug 处理要求)发送给远程 API 服务,由 H800 GPU 进行推理决策。
# 使用远程 API 服务启动测试任务
python main.py --base-url https://oneapi.hkgai.net/v1 \
--model "AutoGLM-Phone-9B-Multilingual" \
"你是一个大模型测试工程师,你需要对港话通进行测试,港话通是ai大模型应用类似chapt-gpt,如果模型返回的内容有问题你要记得提bug,可以截图发给我,然后从新打开一个新的窗口继续测试,如果返回结果只有json也是bug 页面上的所有功能 你不要问我啊直接测试"
系统检查 (System Check Log):
在开始执行前,系统会确认环境配置,确保 ADB 连接和 API 连通性正常。
🔍 Checking system requirements...
--------------------------------------------------
1. Checking ADB installation... ✅ OK (Android Debug Bridge version 1.0.41)
2. Checking connected devices... ✅ OK (1 device(s): AERFUT4B08000806)
3. Checking ADB Keyboard... ✅ OK
--------------------------------------------------
✅ All system checks passed!
🔍 Checking model API... ✅ OK
2. 详细任务执行日志:法律咨询功能 Demo
以下日志片段展示了 Agent 在执行 “法律咨询” 功能时,从识别 UI 元素到执行输入、等待回复并处理长回复(滑动操作)的完整流程。
步骤 1:激活 “法律” 功能并点击输入框
Agent 识别到 “法律” 快捷按钮,点击激活法律咨询模式,随后点击输入框准备输入。
==================================================
💭 思考过程:
--------------------------------------------------
... 现在让我点击"法律"按钮,看看这个功能会显示什么内容。
--------------------------------------------------
🎯 执行动作:
{
"action": "Tap",
"element": [ 288, 757 ],
"_metadata": "do"
}
==================================================
步骤 2:输入法律问题
Agent 观察到输入框提示变为 “法律问题请问我”,随后输入问题。
==================================================
💭 思考过程:
--------------------------------------------------
... 现在让我输入一个关于法律的问题来测试这个功能。
--------------------------------------------------
🎯 执行动作:
{
"action": "Type",
"text": "香港的法定年龄是多少岁?",
"_metadata": "do"
}
==================================================
步骤 3:发送问题并等待
Agent 点击发送按钮,并执行多次 Wait 操作等待远程 H800 服务器上的模型推理结果返回。
...
🎯 执行动作:
{
"action": "Tap",
"element": [ 869, 564 ],
"_metadata": "do"
}
==================================================
...
🎯 执行动作:
{
"action": "Wait",
"duration": "5 seconds",
"_metadata": "do"
}
==================================================
步骤 4:处理长回复(滑动)
AI 返回了详细的法律依据。Agent 意识到内容未完全显示,执行滑动操作查看完整回复。
==================================================
💭 思考过程:
--------------------------------------------------
... 这是一个非常详细和准确的回复。现在让我向下滚动看看是否还有更多内容。
--------------------------------------------------
🎯 执行动作:
{
"action": "Swipe",
"start": [ 499, 610 ],
"end": [ 499, 348 ],
"_metadata": "do"
}
==================================================
3. 任务完成与总结
Agent 最终完成了天气查询、到站、法律和交通查询四大功能的测试,并成功完成了功能验证。
| 功能名称 | 验证结果 | 详细信息 |
|---|---|---|
| 天气查询 | ✅ 成功 | 成功查询 2025-12-12/13 详细天气数据(温度、湿度、风速、能见度等)。 |
| 到站功能 | ✅ 成功 | 成功查询从海港城到 CC 的路线规划,AI 询问具体目的地以提供最佳方案。 |
| 法律咨询 | ✅ 成功 | 成功查询香港法定年龄,并提供详细法律依据(CAP 410、CAP 78 等)。 |
| 交通查询 | ✅ 成功 | 详细列出香港 9 种主要交通方式及其特点和使用场景。 |
实战测试结论:
港话通 AI 助手的所有功能在 Open-AutoGLM 驱动下运行正常,模型(Agent)能够准确理解用户的各类咨询需求,并成功在手机上执行相应操作,并获取所需的详细信息。所有测试任务已完成。
IV. 运行稳定性与性能差异深度分析
在实战中,Open-AutoGLM 的准确性在 M2(4-bit 量化)和 H800(FP16 全精度)上均接近 100%,但在响应速度上差异巨大。
| 性能指标 | Apple M2 本地 (MLX 4-bit) | NVIDIA H800 服务器 (FP16) | 性能差异 |
|---|---|---|---|
| 单步推理耗时 | 13 – 18 秒/步 | 约 2 – 5 秒/步 | H800 速度提升 7–8 倍 |
| 模型加载耗时 | 約 30 秒 | 約 15 秒(预热后) | H800 更快 |
| 内存/显存占用 | ~16 GB 系统内存 | ~20 GB GPU 显存 | H800 显存更充裕 |
1. 内存优化与稳定性
- Mac M2 本地环境对内存要求极高,4-bit 量化是 M2 能够运行 9B 模型的关键。
- 为避免性能衰减,代码中加入了每步清理 MLX 缓存和垃圾回收的操作。实践证明 16GB 设备运行吃力,32GB 内存则相对从容。
2. 常见问题处理(提高真实性)
- 文本输入失败: 必须在手机上安装并启用 ADB Keyboard APK 作为系统的默认输入法,才能确保 Agent 成功执行 Type 操作。
-
截图黑屏/敏感操作: 在银行或支付 App 等安全场景下,Agent 会输出
{"action": "Take_over"}指令,请求用户手动介入处理验证码或支付流程,确保了稳定性和安全性。
V. 总结与应用前景
Open-AutoGLM 提供了一个强大的框架,实现了自然语言到手机操作序列的高效映射,并在功能测试领域展示了极高的准确性和可靠性。
- 个人/小型团队(成本优先): Apple M2 本地部署(配合 4-bit 量化)是一个可行的离线 AI 助手方案。
- 企业级(效率/规模化优先): NVIDIA H800 服务器部署(配合 vLLM 引擎)提供了近乎实时的响应速度和强大的扩展能力,是自动化测试平台的理想选择。
💡 比喻理解: Open-AutoGLM 就像是一位智能的 “盲人向导”。传统的自动化工具只能根据地图上预设的坐标执行,一旦界面变化就失效。而 AutoGLM 不仅能 “看” 到手机屏幕(截图),还能 “摸” 到所有结构化标签(XML),结合用户的目标(自然语言指令),它可以在复杂的 App 环境中自主决策,并始终能找到正确的路径完成任务。
Open-AutoGLM 的多模态感知和流程规划能力,标志着自动化测试已从传统的脚本驱动迈向了基于意图理解的智能自动化新阶段。
