老板最近分了任务,想要我研究 AI 本地知识库的落地可行性
目前公司有部署到本地的 chat,embedding 和 rerank 模型,而且公司大部分的文件均为 pdf 格式,且 pdf 文件内容格式不太统一,大部分为金融产品介绍文件
我本地 docker 部署了 RAGFlow,使用了其自带的 General 分块方法,发现分成的文本块效果不太好,而且检索成功率不够高。
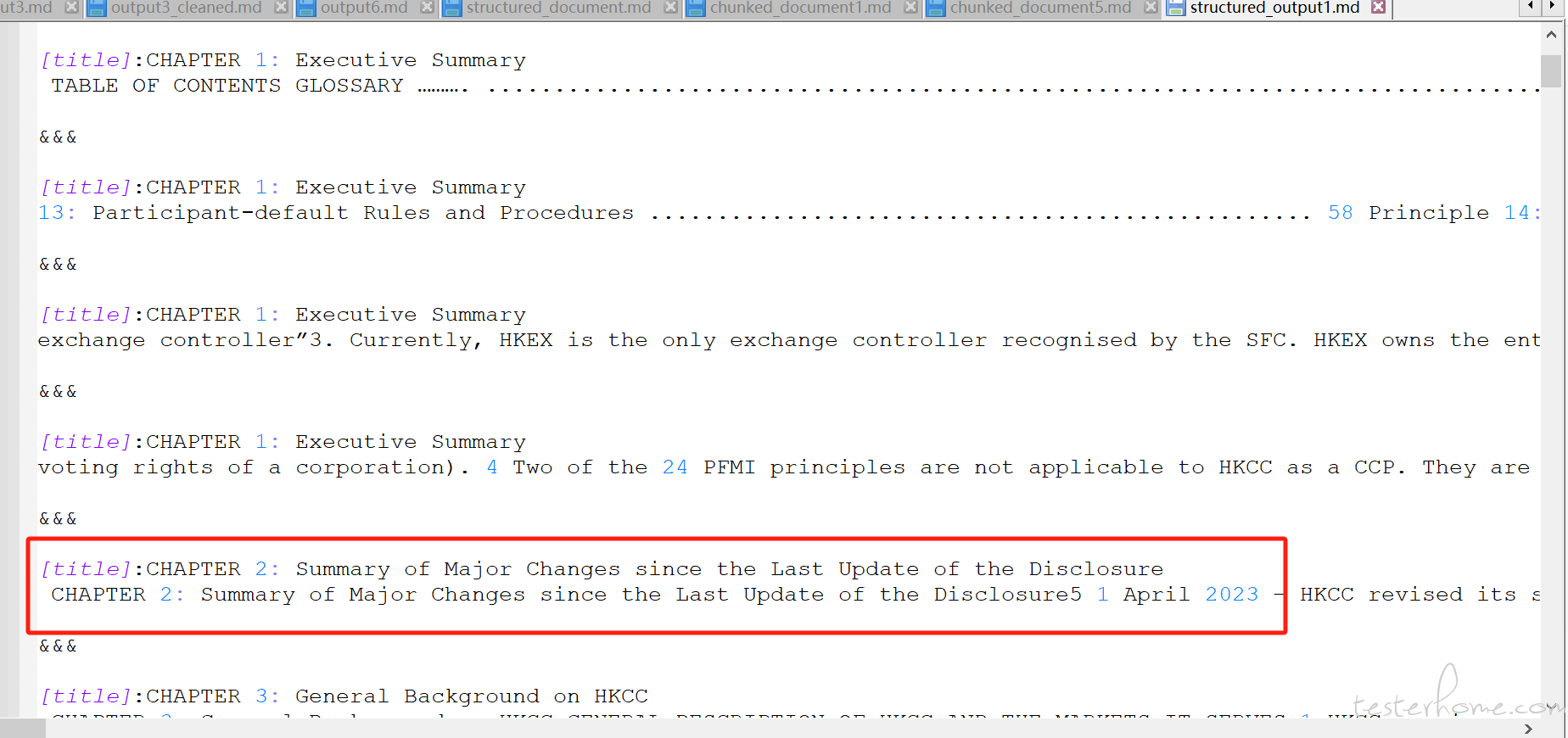
看了下 ragflow 自带的分块效果不太好,而且我一开始也没做文本数据清洗
结合网上提供的分块策略,配合 ds 生成代码,先将 pdf 杂乱数据清洗,然后再分块处理后生成 markdown 文件,再传到 ragflow,感觉效果也不算特别好
所以在这想问下大家:
1.市面上有比较好的知识库解决方案吗,开源或者付费的都可以
2.文本分块有比较成熟的解决方案吗
欢迎大家探讨
谢谢
「原创声明:保留所有权利,禁止转载」