AI测试 GUI 测试智能体框架 Scoutron 2.0 | 从技术构造到工程落地拆解
0.为什么需要 Scoutron2.0
只需一句 “对浏览器和相机进行冒烟测试”,AI 就能自动执行完整流程?
当你看完下面的视频后,就会相信它是真实的。
https://v.qq.com/x/page/m3093ai2k7f.html
过去,我们在为各种场景反复编写脚本,为跨平台 UI 适配熬红了双眼。
现在,凭借多模态 LLM 的颠覆性能力,Scoutron2.0 试图为测试工程师去构建一个全新图景:“无需逐行编写流程化脚本,一句自然语言指令,Agent 即可从界面解析到缺陷检测,完成全流程测试。”
本文将揭示其核心技术密码——从简单的计算器 “1+2” 交互,到复杂业务场景的自动化攻坚,带你一览 AI 如何重塑 GUI 测试的未来。
1.Scoutron 2.0 的基石:基于多模态 LLM 的 GUI 自动化
我们先从一个简单的 GUI 示例入手,看看多模态 LLM 如何实现 GUI 交互自动化。
下图展示了一个简易计算器,只支持数字 1 和 2 的加法运算。

如果希望 GUI 交互自动化 Agent 执行 “完成一次 1 + 2 运算” 任务,基于多模态 LLM 可以通过以下四个步骤实现:
第一步:调用纯视觉 GUI 感知智能体(例如 OmniParser V2),获取当前界面的全部视觉信息,包括元素类型、文本内容、位置、可交互性等。如图所示,将计算器界面图像输入 OmniParser V2 后,它会生成一段文字,完整描述所有视觉识别结果。
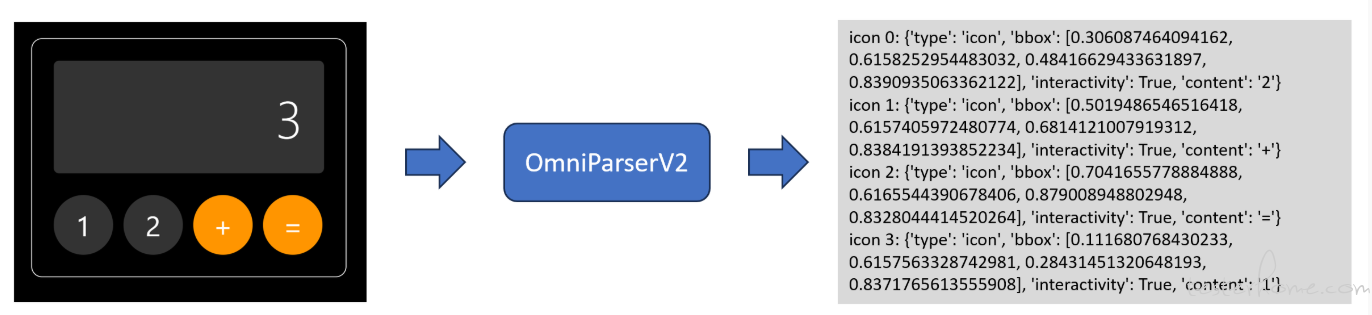
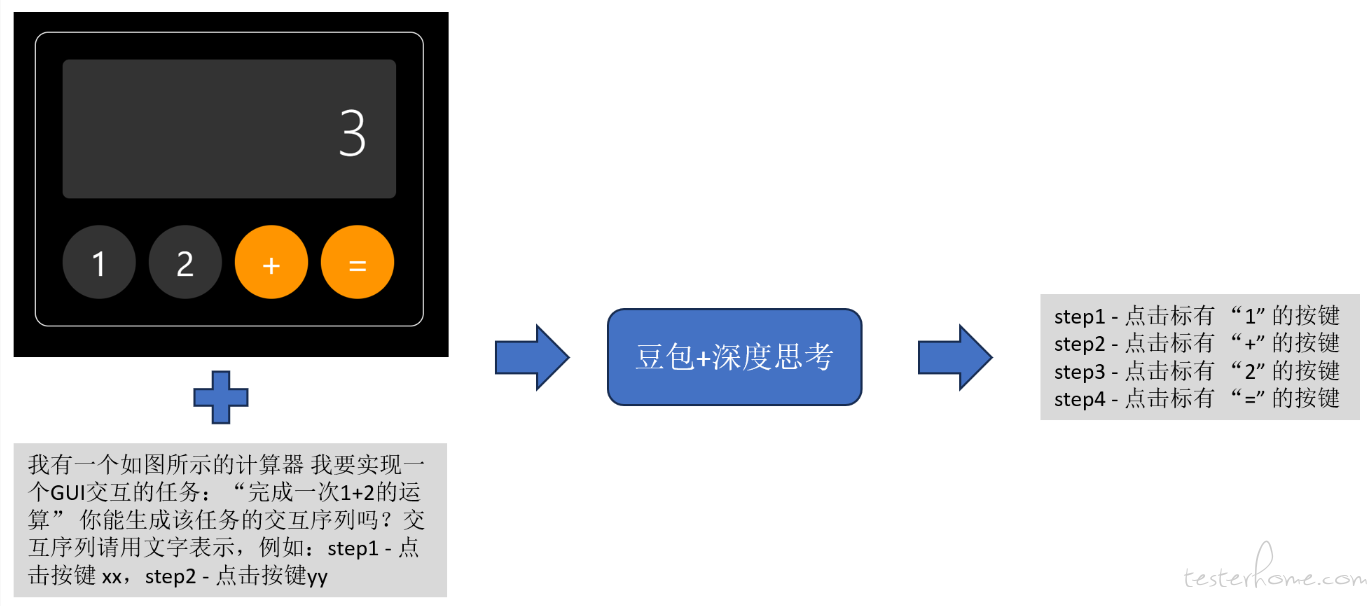
第二步:调用多模态 LLM(例如 “豆包 + 深度思考”),将任务 “完成一次 1 + 2 的运算” 与界面截图一起输入,让模型规划具体交互步骤。如下图所示,输入图像与文字 Prompt,模型即可输出完整的四步操作流程。
第三步:调用 LLM(例如 ChatGPT),将 GUI 内容知识与交互规划步骤同时输入,让模型生成可执行的操作序列。 模型会基于界面元素信息和先前规划,输出具体命令序列,以完成 1+2 的运算。

第四步:调用设备输入模拟智能体(Screen Input Agent),将生成的操作命令转换为实际的触控或点击命令,在真实设备屏幕上执行,从而完成界面交互任务。
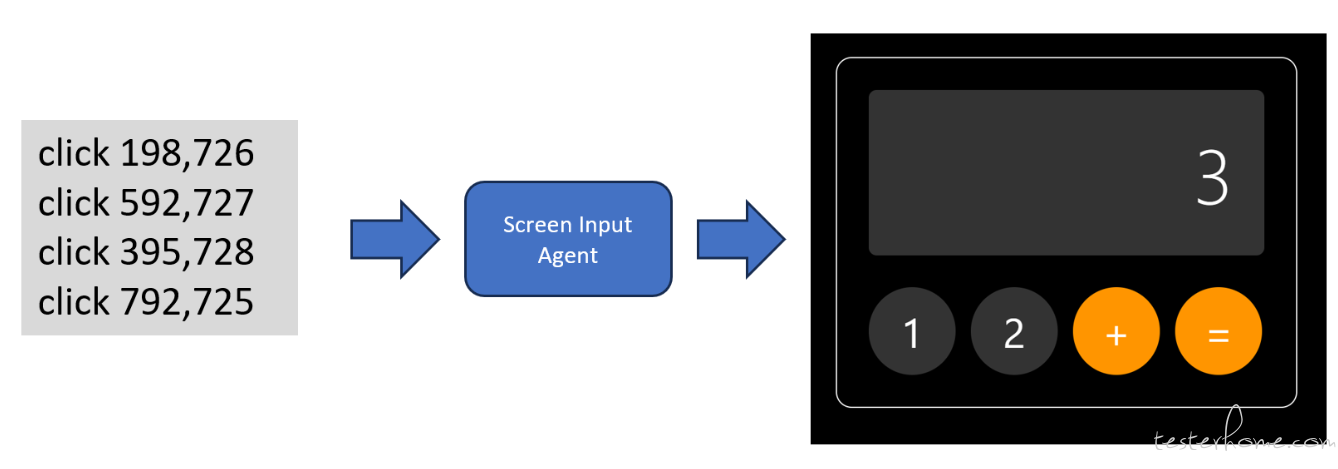
如果将上面四步整合在一起,然后基于当前流行的模型上下文协议(MCP),就可以实现一个微型的、端到端的、GUI 交互自动化了。如下示例代码:
##################### server.py(MCP Server) ####################
from fastmcp import FastMCP
import openai
from omnimcp import OmniParserClient
from gui_controller import GUIController
mcp = FastMCP("12CalcGUIAgent")
# Step 0:截屏工具
@mcp.tool(title="Capture Screenshot", annotations={"readOnlyHint": True})
def capture_screenshot() -> bytes:
gui = GUIController()
return gui.screencap()
# Step 1:解析界面
@mcp.tool(title="Parse GUI Screenshot", annotations={"readOnlyHint": True})
def parse_gui(image_bytes: bytes) -> dict:
"""
返回结构示例:
{
"elements": [
{"type": "icon", "content": "1", "bbox": [x1,y1,x2,y2], "interactivity": True},
...
]
}
"""
return OmniParserClient().analyze(image_bytes)
# Step 2:生成高阶 Plan
@mcp.tool(title="Generate Plan Steps", annotations={"readOnlyHint": True})
def generate_plan(gui_info: dict, task: str) -> list[str]:
resp = openai.ChatCompletion.create(
model="bean-thinker",
messages=[{"role":"user","content":f"GUI info: {gui_info}\n任务: {task}\n输出日程步骤"}]
)
return resp.choices[0].message.content.strip().splitlines()
# Step 3:Plan Step → 低阶动作
@mcp.tool(title="Plan Step to Actions", annotations={"readOnlyHint": True})
def step_to_actions(gui_info: dict, step: str) -> list[dict]:
resp = openai.ChatCompletion.create(
model="gpt-4o",
messages=[{"role":"user","content":
f"GUI elements: {gui_info['elements']}\nStep: {step}\n"
"针对单步生成 JSON list,每个包含 type: 'click' 或 'type', x, y, text (如果 type='type')"}]
)
return openai.util.parse_json(resp.choices[0].message.content)
# Step 4:执行低阶动作
@mcp.tool(title="Execute Actions", annotations={"readOnlyHint": False})
def execute_actions(actions: list[dict]) -> bool:
gui = GUIController()
for act in actions:
if act["type"] == "click":
gui.click(act["x"], act["y"])
elif act["type"] == "type":
gui.type_text(act["text"])
else:
raise ValueError(f"未知动作类型: {act['type']}")
return True
if __name__ == "__main__":
mcp.serve()
#################### client.py(流程调度器) ####################
from fastmcp import MCPClient
import time
client = MCPClient()
def run_task(task: str):
plan_steps = client.call_tool("Generate Plan Steps", gui_info={}, task=task)
print("Plan:", plan_steps)
for step in plan_steps:
print("执行步骤:", step)
img = client.call_tool("Capture Screenshot")
gui = client.call_tool("Parse GUI Screenshot", image_bytes=img)
actions = client.call_tool("Plan Step to Actions", gui_info=gui, step=step)
success = client.call_tool("Execute Actions", actions=actions)
if not success:
print("执行失败,停止流程")
return
time.sleep(0.5)
print("所有步骤执行完毕")
if __name__ == "__main__":
run_task("完成一次1+2的运算")
如何扩展到更复杂的场景中呢?这需要从四个方面进一步展开讨论:探索 (Exploration)、感知 (Perception)、推理与规划 (Reasoning & Planning)、以及交互 (Interaction)。
以前述的计算器案例为基础,重新设计后的 GUI 自动化 Agent 架构如下所示:
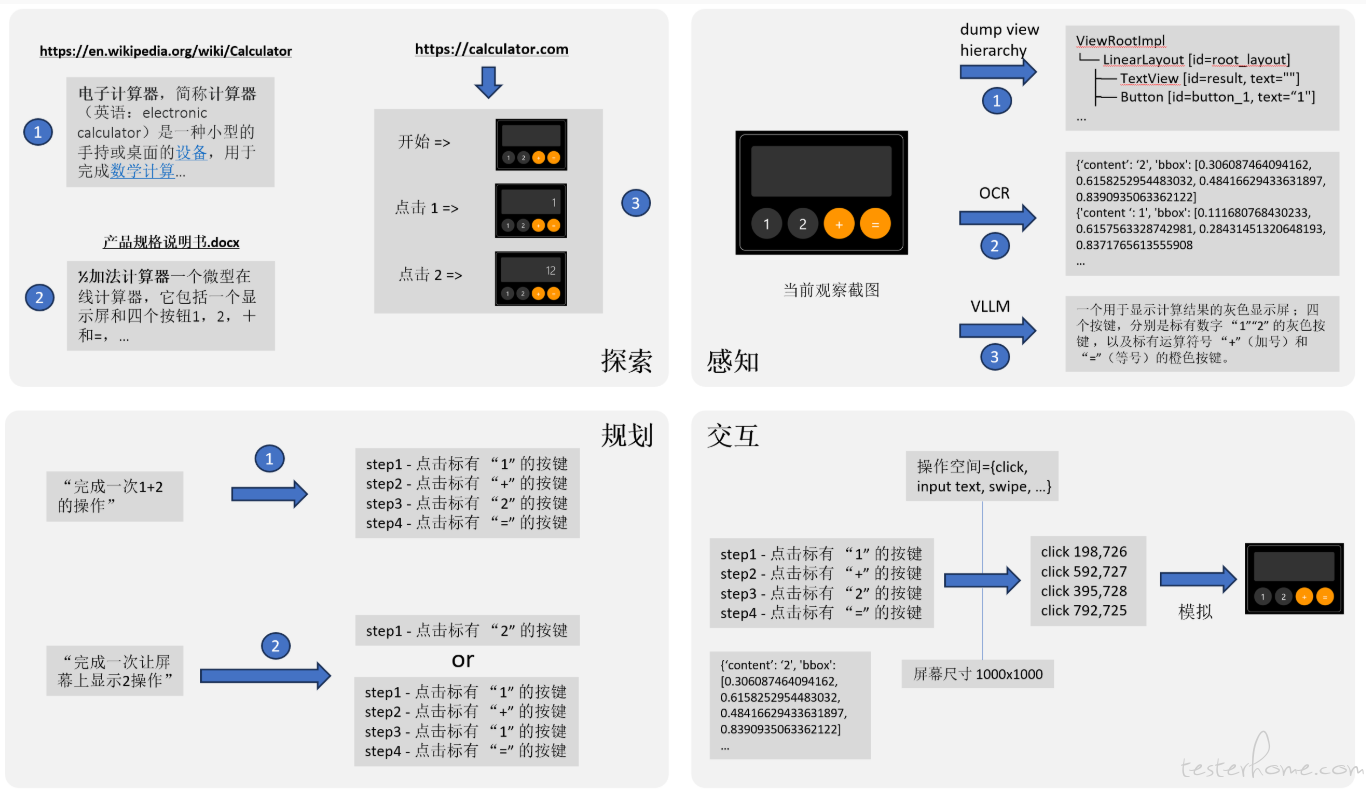
探索(Exploration):知识的获取与管理对高效的 GUI 自动化至关重要。当前的多智能体系统已经构建了涵盖内部理解(如 UI 功能、元素属性)、历史经验(任务轨迹、技能库)和外部信息(API 文档、Web 资源)在内的全面知识库。然而,如何高效地组织与检索这些知识以辅助决策,仍然面临诸多挑战。
推理与规划(Reasoning & Planning):高阶推理框架的引入显著增强了智能体处理复杂任务的能力。现代方法结合了多种思维链技术和响应策略进行系统性规划。但依然存在挑战,主要包括远距离规划、错误恢复能力、以及在多交互路径中保持一致性的难题。
感知(Perception):智能体对界面的理解能力已从早期的文本解析发展为复杂的多模态感知。近年来的感知能力提升体现在两方面:一是基于文本的解析(如 DOM/HTML 结构),二是多模态理解(如基于多模态 LLM 和专用 GUI 模型的处理)。不过,在精确元素定位、动态内容跟踪和分辨率适配等方面,仍有不少技术难点。
交互(Interaction):动作空间已从基础的 GUI 操作扩展至复杂的 API 集成,且更强调执行过程的安全性与可靠性。当前智能体采用多种策略生成并执行动作,越来越重视安全控制与异常处理机制。
这四个模块形成一个集成的流水线,使得 GUI 自动化 Agent 能够处理自然语言指令,理解界面上下文,规划合理动作并安全地执行。这一架构已在多种应用中被验证有效,尽管各组件仍不断面临挑战,也正是这些挑战推动了持续的研究与实践。
2.Scoutron2.0 的架构解析——走上不完美的最后一公里
也许你刚刚下载并配置好了一个 GUI 自动化 Agent(例如 omniparser‑autogui‑mcp),运行 “打开 YouTube,搜索 MrBeast,并播放第一个视频” 这一指令时,发现它执行得异常丝滑。
于是你接着输入:“打开 QQ 音乐,搜索邓紫棋,播放第一首歌”,却发现智能体卡住了。
为什么会这样?我们该怎么办?
而作为测试人员的我们,甚至还期待它能完成更高阶的任务——比如 “测试 QQ 音乐的搜索功能”。把这样的需求交给智能体,是否太过理想化了?
Scoutron 2.0 的引入,正是为了和我们一起探讨:它是如何寻找解决方案,并努力高效地走完那 “最后一公里”。
Scoutron 2.0 是一个框架,提供了完整的软件架构与方法指引,帮助我们根据自身的实际情况提出可落地的专属方案。这包括:
将在特定数据集/场景中训练过的 AI 模型和多智能体能力,泛化到实际领域
加入对 “测试” 这一目标的明确支持,而不仅仅是任务执行
在可靠性、效率与成本之间寻求一种务实的平衡
2.1.从启动实际业务泛化开始

左图一眼看去,我们就知道它是一个计算器(尽管现实中很少有这种样式的计算器),这是因为我们脑海中已有对 iPhone 计算器的印象,并进行了智能的分类与联想。人类具备这种直觉式的迁移学习能力,而 Agent 也同样具备。
互联网上存在大量与计算器相关的图像和知识,它们早已被用于训练各类大语言模型。因此,当我们看到市面上某些炫酷的 Demo,展示 Agent 多么智能、仿佛能替代人类,其实本质上只是再次验证了大语言模型训练机制的有效性——尤其归功于那些高质量的训练数据与任务设计。
而右图呢?如果我们同样认为它 “看起来也像某种计算器”,并再次交由同一个 Agent 处理,结果往往令人失望。就像一个盲人在屏幕上,基于原始的色彩刺激,进行无序、低阶的条件反射。
右图背后的 “真相” 我们自己心里清楚。因此,若仅因 AI 的识别失败就指责它产生 “幻觉” 或表现 “不理想”,显然对 AI 并不公平。
要让 Agent 真正具备对被测试环境的准确理解,我们必须赋予它两类关键信息:
视觉认知标注:告诉它屏幕上绿色、红色的方块分别代表什么
业务规则声明:说明按照某种顺序点击这些方块后,所出现的数字意味着什么
视觉认知标注
首先,我们需要以某种形式对以下知识进行标注——即建立空间结构与文字之间的映射关系。接着,通过视觉模型的训练,实现目标对象的准确定位。
目前,一些视觉感知智能体采用了单一或组合的方法(例如 OCR 与 DOM 树结构结合),但这些方法依然存在诸多限制和适应性问题,例如:某些按钮是图片形式,不包含文字;多个按钮使用相同的 ID 或 Label,导致歧义。
因此,视觉认知标注仍然是当前乃至未来相当长一段时间内无法绕开的关键环节。为了应对 GUI 的持续演进,这一过程通常需要投入大量成本,并进行长期维护。
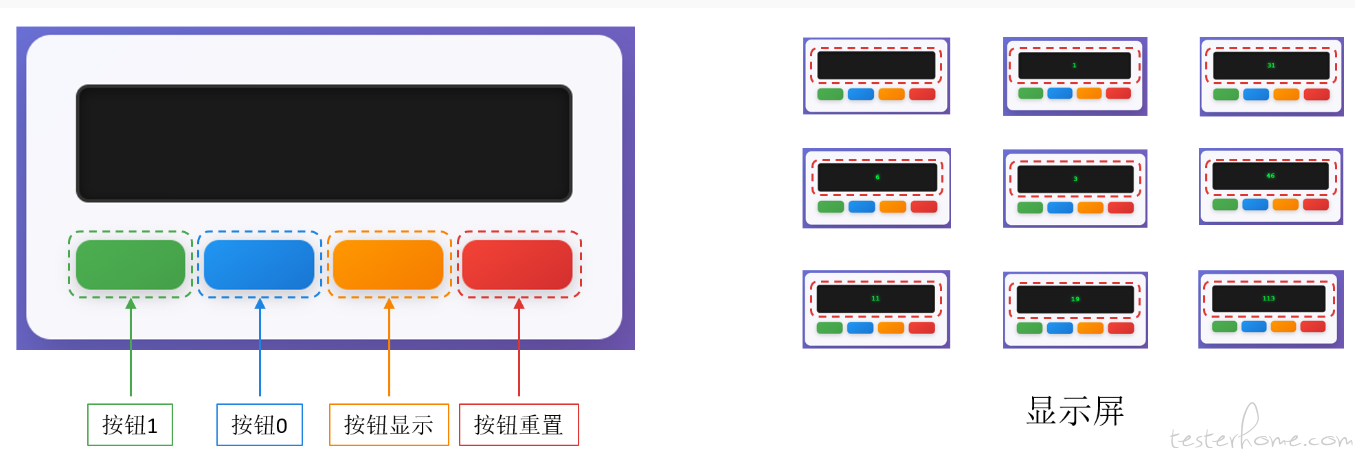
图左展示了对每个彩色方块的标注。由于这些图像的颜色和形状相对固定,所需的标注量相对较少。而图右展示了 “显示屏” 这一对象的标注,由于其内容随数字变化,我们需要准备大量样本来泛化出统一的定义——无论屏幕上显示何种数字,都应被识别为 “显示屏”。
业务规则声明
在完成视觉认知标注之后(或基于这些标注训练出某个视觉/多模态模型),下一步就是构建业务规则,也就是所谓的自有知识库(可以是纯文字,也可以是多模态形式)。
我们可以为上述测试环境定义如下业务规则:
这是一个计数器应用程序。它包括一个显示屏和四个按钮:1、2、显示、和重置。点击按钮 1 一次,内部计数器自增 1;点击按钮显示,显示屏上出现对应计数器的数值;点击按钮重置,内部计数器清 0。
现在,我们终于开始搞清楚,这个程序到底在做什么了。
最后,只要视觉认知标注与业务规则声明被准确提供,并能被智能体有效访问,那么具备领域泛化能力的智能体就可以被构建起来,从而完成诸多 GUI 自动化任务,例如 “在显示屏上显示数字 5” 或 “在显示屏上依次显示数字 1 到 5”。
2.2.别忘了我们是在测试
GUI 交互自动化与 GUI 测试自动化是两个不同的概念,这种差异从目标定义开始就已经显现出明显的不一致性(测试技艺 | AI 赋能 GUI 自动化测试的挑战中也有以及)。
举个例子,如果你给一个智能体下达这样的任务:“帮我在支付宝上给我的手机号充值 50 元”,那么它的唯一目标就是找到一条路径——从启动支付宝 App 到成功接收到 “50 元充值成功” 消息。在这个过程中,智能体可能会遇到异常,但它可以尝试重试、跳过、甚至绕行。与 “充值成功” 无关的状态和信息,它完全可以忽略。
为了实现这个目标,许多智能体采用强化学习策略,奖励机制侧重于结果的达成和路径的最短性。
然而,如果我们要实现的是 GUI 测试,情况就完全不同了。此时,智能体需要接收的是另一个任务:“帮我快速遍历支付宝充值的核心功能,并报告其中的 GUI 缺陷”。这个目标不再追求效率或结果达成,而是强调广度搜索与交互质量的验证。
智能体在这里的职责是探索尽可能多的状态路径,观察界面在不同条件下的响应是否一致、合理,是否存在视觉或功能缺陷。它的奖励机制需要围绕覆盖率、异常发现能力、验证效果来重新设计,模型的权重和算法参数也应据此优化。
那么,如何才能实现从 GUI 交互自动化到 GUI 测试自动化的跨越?接下来的部分,我们将从两个关键方面展开讨论:搜索和覆盖、发现缺陷。
搜索和覆盖
基于 GUI 的测试环境可以被简化为一个输入–响应系统,尽管在某些情况下它也会表现出一定的不可预测性。GUI 交互自动化的构建,正是基于输入与响应之间的因果规则链。因此,GUI 测试同样可以在这一逻辑基础上进行建模(具体将在第 3 章进一步展开讨论)。
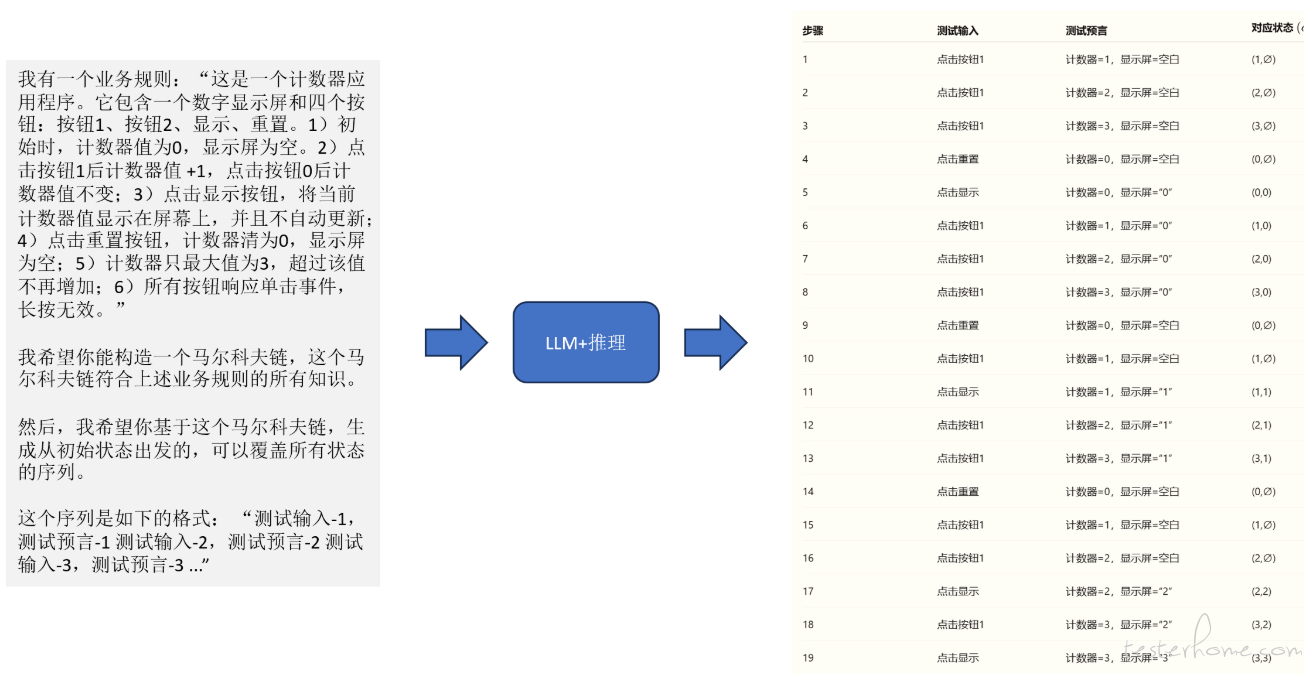
GUI 测试的可以按照如下的测试输入和预言序列(这和 GUI 交互自动化只是生成交互序列有所差别)去执行:
测试输入-1,测试预言-1
测试输入-2,测试预言-2
测试输入-3,测试预言-3
...
这个序列从何而来?只能源自对被测试环境的描述,也就是前文提到的业务规则声明。
当业务规则声明具备完备性、无二义性和可测试性时,就可以借助大语言模型(LLM)的推理能力,生成相应的被测试环境测试模型。
我们再次审查一下前文提到的业务规则:“这是一个计数器应用程序,包括一个显示屏和四个按钮:1、2、显示、和重置。点击按钮 1 一次,内部计数器自增 1;点击按钮显示,显示屏上出现对应计数器的数值;点击按钮重置,内部计数器清 0”,发现它可能是一个逻辑不严谨的描述,有不少问题:
按钮 2 的功能没有任何描述,是无效按钮?还是类似于按钮 1 那样自增 2?
当应用加载以后,内部计数器的初始值是几?
当应用加载以后,最初显示器显示数值吗?
点击按钮重置后,显示器还显示数字吗?
计数器是否有计数上限未说明?超过上线后又该如何?
点击 “显示” 后是否自动更新还是一次性显示?
有时我们抱怨 LLM 生成的测试用例不够准确,其中一个原因是业务规则的描述不够完备,存在前后矛盾,或信息不足,无法支持生成有效的测试输入和预期结果。这样就可能导致 LLM 在生成测试输入和预期序列时产生所谓的 “幻觉”。
要消除这种幻觉,必须提供更加高质量、准确且一致的业务规则定义。
下面给出一个更高质量的业务规则声明示例,能够有效减少测试生成中的幻觉现象:
这是一个计数器应用程序。它包含一个数字显示屏和四个按钮:按钮 1、按钮 2、显示、重置。1)初始时,计数器值为 0,显示屏为空。2)点击按钮 1 后计数器值 +1,点击按钮 0 后计数器值不变;3)点击显示按钮,将当前计数器值显示在屏幕上,并且不自动更新;4)点击重置按钮,计数器清为 0,显示屏为空;5)计数器只最大值为 3,超过该值不再增加;6)所有按钮响应单击事件,长按无效。
基于这个高质量的业务规则,我们可以借助马尔可夫链来构建相应的测试模型。
具体来说,我们构造一个状态空间及其状态转移模型。然后,只需为该模型输入覆盖条件,例如 “找到一条覆盖所有状态的路径” 或 “找出若干条覆盖所有状态转移的序列集合”,借助 LLM 的推理能力,就能生成对应的测试输入和预期序列。示意如下图:
发现缺陷
GUI 的测试过程主要暴露两类缺陷:业务缺陷(基于页面间状态迁移)和显示缺陷(基于页面内视觉感知)。

业务缺陷指的是观察到的实际 GUI 显示与测试预言不符,且问题源自页面之间的状态迁移。
如左图所示,最终屏幕显示数字 3 是否正确,依赖于初始状态 “显示 1”,以及先后点击 “按钮 1” 和 “按钮显示” 的操作。根据前文的业务规则推理,显示屏此时应显示 2 而非 3,因此明显存在错误。单凭当前的显示状态(最后显示的 3),无法断定其正确与否。
发现业务缺陷的关键在于利用生成的 “测试输入与预言序列”,对每一步测试输入,比较预言结果与实际状态即可。
相比之下,显示缺陷的发现更为复杂。
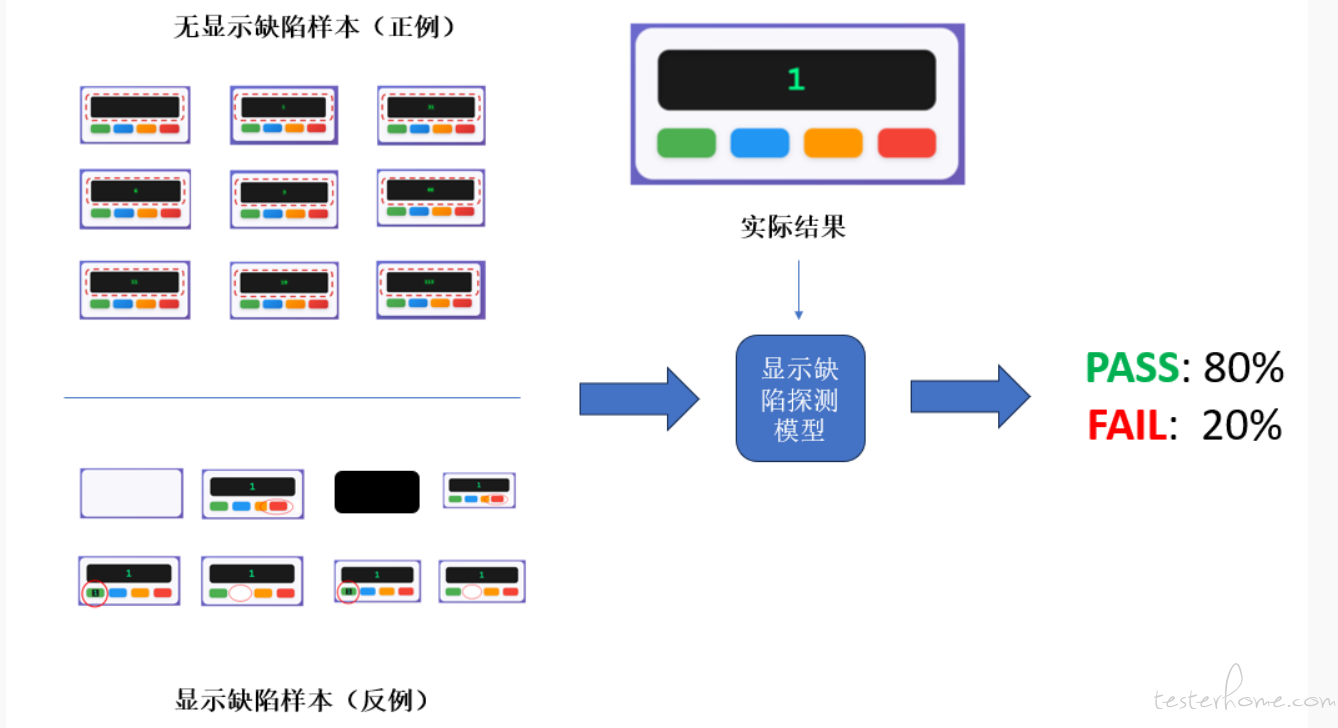
右图展示了四种显示缺陷示例:
图 1:白屏(内部计数器为 1,但界面未显示任何内容);
图 2:“按钮重置” 左移,遮挡了 “按钮显示”;
图 3:“按钮 1” 按钮上出现了 “1” 字符(而设计中按钮上不应显示任何文字);
图 4:“按钮 0” 按钮未显示。
显示缺陷影响用户对 GUI 状态的视觉理解,如何对其做出明确且统一的定义较为困难。借助视觉大语言模型(视觉 LLM)能力,我们可以构建一个显示缺陷样例库,其中包含正例和反例。正例涵盖视觉感知上被认可为正确的 GUI 界面,反例则涵盖各种可能的异常样本,如下图左侧所示。
由于不同领域对同一图像的标注可能完全不同,且与多数人的视觉认知存在差异,因此建立统一的视觉模型来区分 “看起来正确” 与 “看起来错误” 显得尤为重要。
构建好这样包含正反例的样例库后,通过多模态 LLM 训练显示缺陷检测模型,再将实际界面图像输入模型,就可以获得一个 Pass/Fail 的概率预测,用于判定是否存在显示缺陷。
2.3.权宜之计
数据集 vs. 基于规则
当前我们讨论的 AI,基本都建立在机器学习之上。机器学习成功的关键公式是:有效的模型架构 + 高质量的数据 + 高效的训练。构建专属的 GUI 测试 Agent,也遵循这一公式。
我们可以利用强大的多模态大语言模型(MLLM),并投入资源搭建训练环境。但若要真正实现基于机器学习的解决方案,必须建设专属的、高质量的数据集(知识库)。
基于 Scoutron 2.0,首先应考虑构建或迁移现有知识库,覆盖前文提到的三类数据——视觉认知标注、显示缺陷样本库及业务规则声明,以满足 GUI 测试 Agent 的训练与执行需求。但若时间、人力和资金不足,只能退回基于规则的算法设计,或采取混合策略,寻求折中方案。
视觉认知标注——理想中,我们期望打造一个 “超级模型”,能识别所有 GUI 元素、控件、图标及文字,并准确定位。但至今尚无此类模型诞生。因此,我们需研究现有可用模型(如 OmniParser、GPT-4、豆包等)的能力边界,评估其准确率和召回率,再针对泛化能力弱的部分进行标注、调优和新模型训练。若无法接受商用模型的延时和 API 调用成本,或难以承担运行/训练开源模型的硬件成本,只能退而求其次,采用基于控件 DOM 树、OCR、OpenCV ROI 定位等规则算法。Scoutron 2.0 将上述方法整合,提供时间、成本与效果的权衡方案。
显示缺陷构造——构建正例与反例数据集,机器学习模型才能学习显示缺陷模式,进而给出分类预测。所需样本量和基于多模态 LLM 微调的成本没有统一标准。与视觉认知标注类似,当成本成为障碍时,只能退而采用 “错误规则” 编程(如检测异常颜色、元素缺失或分析 Crash 日志等)。Scoutron 2.0 同样将这些备选方案纳入,支持权宜之计切换。
业务规则声明——Scoutron 2.0 定义了一个简单的业务规则声明验证器,用于评估现有知识库是否满足无二义性、可测试性及可导出马尔可夫链的要求。只需在 LLM 中运行该工具,即可辅助评审并发现不合规项。当然,基于 Scoutron 2.0 重新开发业务规则声明,是构建新智能体的最佳路径。验证提示词虽能辅助检查,但无法确保知识库完备,尤其是对那些只存在于大脑中的系统预期描述。这些描述若为常识,或许现有 LLM 已掌握;但若属于领域知识,则必须明确声明。Scoutron 2.0 建议尽可能创建完善的业务规则声明,若因成本原因放弃,最终只能导致效果欠佳,幻觉现象迟早会影响测试生产。
基于对话框和状态回滚的兜底设计
Scoutron 2.0 还提供了一种兜底机制——基于对话框交互确认与状态回滚。当资源有限,无法构建完善知识库和数据集、或是无力训练私有模型时,智能体执行时出现不可预期错误(即幻觉)就无法避免,这时人工兜底就可以触发。
一种方案是弹出提示框或发送即时消息,暂时由测试人员接管 Agent,调整测试环境至正确状态,或忽略错误,让智能体继续执行。
另一方案是 Agent 状态机回滚至初始状态,自动重试。该设计不属于正常执行流程,但在数据集构建与兜底方案之间寻求平衡,可助力智能体持续优化。
通过冗余机制和投票提升可靠性
Agent 可靠性受限于自身复杂度及集成的工具稳定性。为了实现高准确率和召回率的 GUI 测试过程,架构设计必须精心规划。
鉴于不同 LLM 的性能存在差异(如调用时延和生成内容),Scoutron 2.0 在关键环节(视觉认知、测试规划)并行调用三种不同 LLM,通过规则算法进行投票决策(一种方法是计算结果间距离,再从距离较近的两者中随机选取一个),选出最佳结果。这种冗余和投票机制最大限度降低了幻觉发生概率。
但冗余必然带来成本上升,且投票机制无法保证总是选出最优结果,如何权衡使用仍需在实践中不断调整。
总之,Scoutron 2.0 不鼓励一开始就退回权宜之计,但也无法明确何时该权衡取舍,因此它教会我们直面现实,接受不完美的 AI 系统。这或许就是测试中的权衡艺术,也是 AI 在短期内难以完全取代人的原因所在。
2.4.Scoutron 2.0 的架构设计和流程剖析
在资源有限的情况下,权宜之计是一种必要的妥协,但 Scoutron 2.0 的架构设计依然追求更系统化、全面的解决方案。
将前两章的所有讨论进行抽象,形成了如下的 Scoutron 2.0 架构。
Scoutron 2.0 并未绑定于任何特定工具或框架,而是致力于提供一个灵活且可参考的架构体系。
这种设计使得该方案能够更好地泛化,适应复杂多变的广泛场景。基于这一架构,我们才能构建出专属的、端到端的、基于 GUI 的测试 Agent。
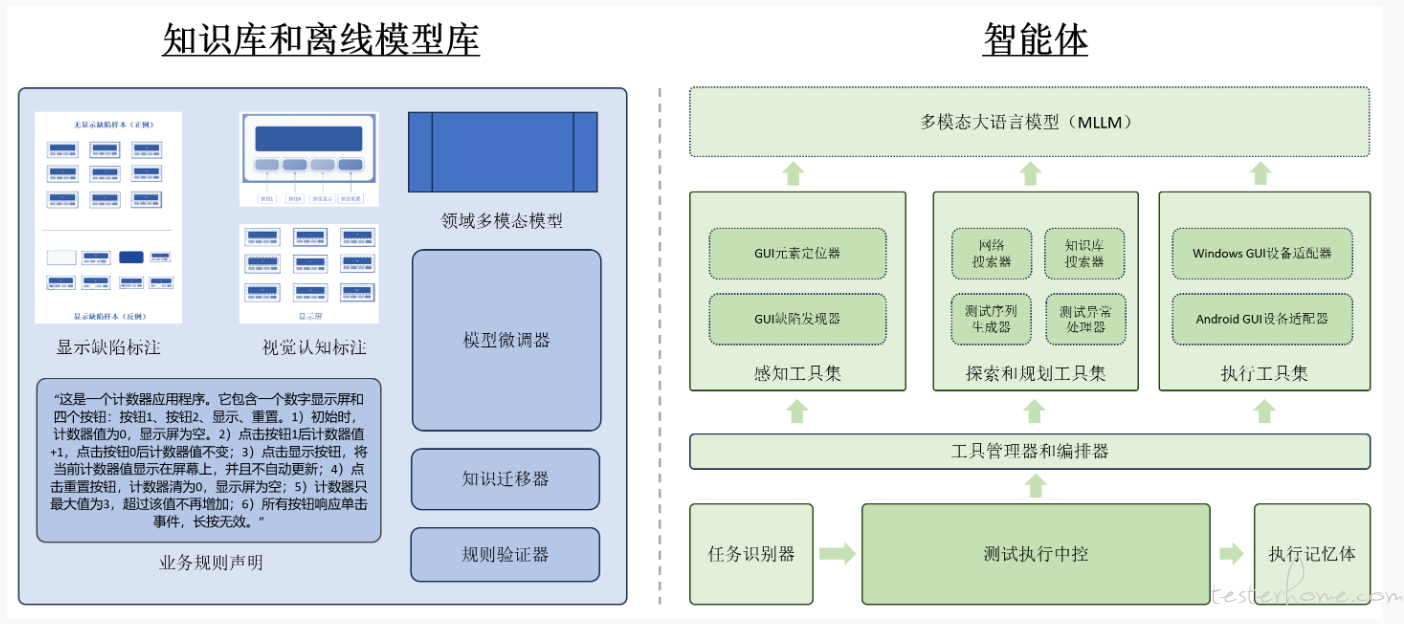
该架构不仅阐明了智能体自身的组成部分,还特别强调了知识库的构建与离线模型的训练(通过工具集的支持实现)。
下图以计数器应用程序为案例,展示了智能体如何借助多个工具协作,共同完成在 Android 设备上对计数器的测试执行。
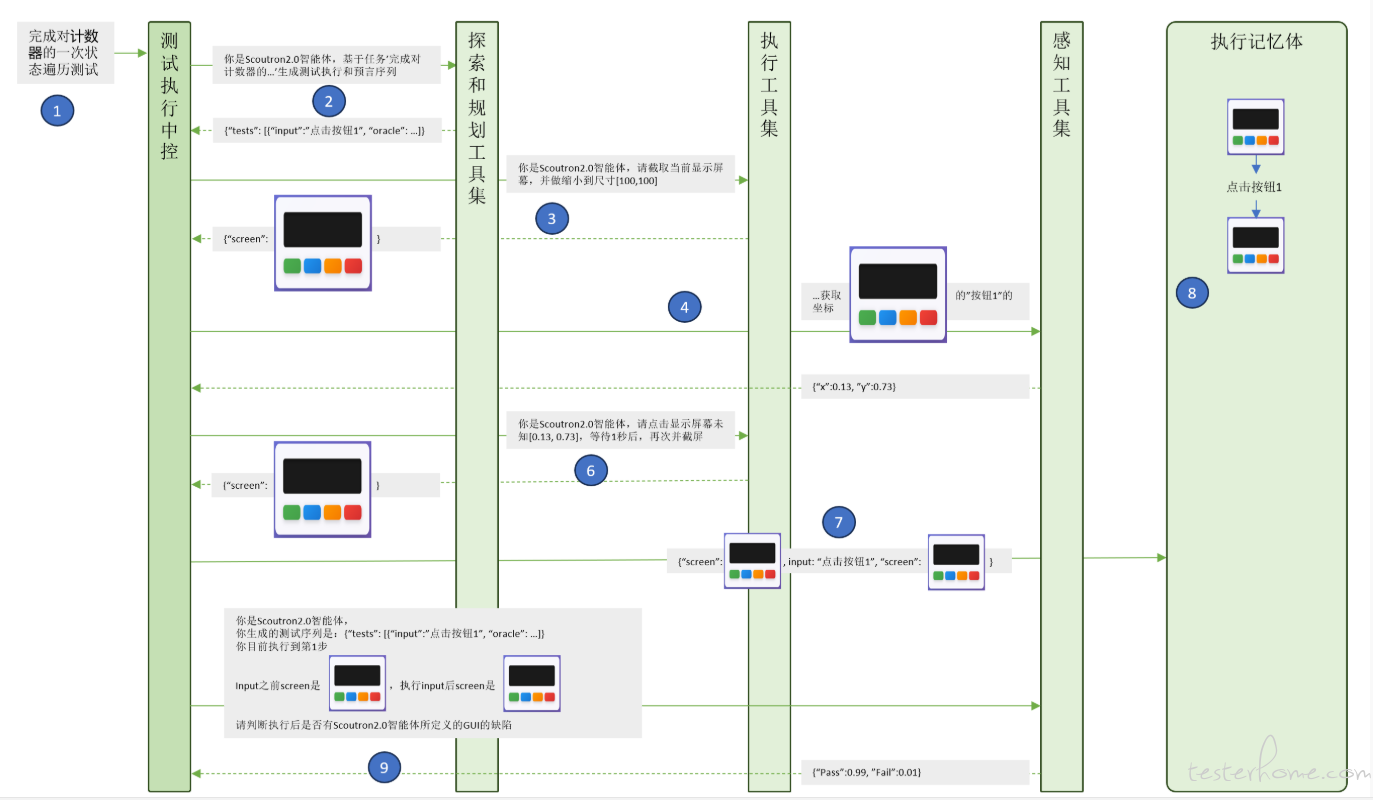
3.Scoutron2.0 的根基——数学模型和局限性
讨论 Scoutron 2.0 所依赖的数学模型是十分必要的,这有助于明确其能力边界和局限性。保持严谨的态度,有助于更好地规避风险并寻找合理的权衡方案。
文献 [1]《GUI Agents: A Survey》对 GUI 智能体的定义及数据表达已有较为系统的论述。但鉴于 GUI 测试与 GUI 交互自动化存在差异,我们需要对文献中的表述进行调整,使其能够涵盖 “测试” 这一概念,构建适用于测试场景的数学模型。
数学定义
Scoutron2.0 是这样一种测试智能体的:
GUI 测试 Agent 是一个能够操作 GUI 环境(比如点击按钮、输入文本等)并实现缺陷(显示缺陷和业务缺陷)识别任务的智能体,而这个问题可以形式化为一个变种的 POMDP(部分可观测马尔可夫决策过程)上。
变种 POMDP 是一个六元组 (U, A, S, O, T, P):

GUI 测试 Agent 被定义为π,它是一个策略:
π : O → P, A
意思是:Agent 根据当前观察到的 GUI(观察的状态 o),确定测试结果 r,以及决定接下来的动作 a。其中 p 是一个概率,a 是动作空间 A 中的一个值。
而构造 GUI 测试 Agent 就是要确定一个奖励函数 R,使得每一步 t:
智能体从 GUI 中观察到当前信息 o ∈ O。
用策略 π 预测出要执行的动作 a ∈ A。
环境根据状态转移函数 T(s, a) 跳转到一个新的状态 s′。
如果设计了奖励函数 R,那么智能体会得到一个奖励 r = R(s, a, s′)。奖励函数 R : S × A × S → ℝ 表示从 s 执行 a 到达 s′ 后能获得的奖励。
在 GUI 自动化的定义中,奖励函数 R 被设置为指向任务完成为最大奖励的。但是在 GUI 测试的问题中,奖励函数 R 就变成了对测试覆盖行为(覆盖状态、覆盖变迁、或者按照风险执行测试等)的奖励。
假设与局限性
基于 Scoutron 2.0 构建的系统,依据上述数学模型,可以将测试环境抽象为一个马尔可夫决策过程(MDP)。测试执行过程即是在某种策略和奖励机制指导下,遍历该 MDP 的过程。基于此,产生了以下假设:
测试环境可以被描述为一个马尔可夫决策过程,且不存在随机事件的发生。
按照马尔可夫决策过程模型,测试执行可以在离散时间序列上顺序进行环境的操作和观察,并得到确定的测试通过率。
然而,这些假设与实际情况存在较大偏差:
现有业务规则常存在大量不一致、前后矛盾或模糊表述,导致其在数学上难以完全等价于一个标准的马尔可夫决策过程。要应用 Scoutron 2.0 架构,必须对业务规则进行修正,使其符合 MDP 模型的要求。
实际测试环境往往包含许多随机事件,例如应用中的随机弹窗、事件推送通知等。再如家庭 WiFi 路由器断连直接影响相关软件系统行为,但路由器状态通常未包含在业务规则声明中。这些随机因素降低了 Scoutron 2.0 的可靠性,且难以自动纠正。
有时对测试环境的输入和观测无法实现严格串行化。例如,在 Android 手机上长按按钮时,持续按压和界面上的动画效果是两个并行发生的任务,将其简化为时间上的先后顺序不够现实。
除此之外,实际应用中还存在许多情况导致 Scoutron 2.0 架构无法完全适用。此时,需借助基于规则的方式,对 GUI 测试过程进行建模或修正。例如针对随机事件,可以设计独立的并行事件处理线程加以应对。
4.面向未来趋势的持续重构
以上提到的 Scoutron 2.0 仅是一个概念性和逻辑性的设计框架,未涉及具体实现甚至源代码,因为那样做意义有限。
当前 Agent 领域日新月异,这背后依赖于多模态大语言模型(LLM)的快速迭代。因此,固定某一套工具集组合策略,做出一两个 Demo 就妄言定论,并非 Scoutron 2.0 所倡导的路径。事实上,一旦新的多模态 LLM 版本发布,整个 Agent 的工作流和工具链可能会发生巨大变化。这种动态演进与传统基于规则的软件开发范式截然不同,也使得我们很难进行长期、精准的规划。
然而,我们可以谨慎乐观地期待,多模态 LLM 在视觉认知(如具备空间理解能力)和推理能力(解决更复杂工程问题)方面的突破就在眼前。届时,我们无需再依赖那些折中的、基于规则的解决方案,多模态 LLM 也能轻松迁移至各种垂直领域和专属系统。
正如计算器案例所揭示的:从 “1+2” 到复杂业务流程的飞跃,从来不是简单的代码行数堆积,而是认知范式的跃迁。下一代 Scoutron,很可能隐藏在某个多模态模型的下一次迭代中,或诞生于测试工程师与 AI 协作编写的第一行 “非权宜之计” 的代码之中——这,正是我们今天依然坚持打磨每一条标注、每一条规则的理由。
5.参考文献和开源项目
GUI Agents: A Survey, https://arxiv.org/pdf/2412.13501
A Survey on (M) LLM-Based GUI Agents, https://arxiv.org/pdf/2504.13865
GUI Testing Arena: A Unified Benchmarkfor Advancing Autonomous GUI Testing Agent, https://arxiv.org/pdf/2412.18426
AUITestAgent: Automatic Requirements Oriented GUI FunctionTesting, https://arxiv.org/pdf/2407.09018
OmniParser for Pure Vision Based GUI Agent, https://arxiv.org/pdf/2408.00203
OS-ATLAS: A FOUNDATION ACTION MODEL FORGENERALIST GUI AGENTS, https://arxiv.org/pdf/2410.23218
UI-TARS:Pioneering Automated GUI Interaction with Native Agents, https://arxiv.org/pdf/2501.12326
Seeing is Believing: Vision-driven Non-crashFunctional Bug Detection for Mobile Apps, https://arxiv.org/pdf/2407.03037
mobile-next/mobile-mcp, https://github.com/mobile-next/mobile-mcp
张昊翔
2025/06/25

WeChat: hzhan11
QQ: 22321262
Email: xjtu_xiangxiang@hotmail.com
LinkedIn: https://www.linkedin.com/in/hzhan11/
 借助大佬的思路,做了一个类似的,已经跑通一些业务场景。感谢
借助大佬的思路,做了一个类似的,已经跑通一些业务场景。感谢