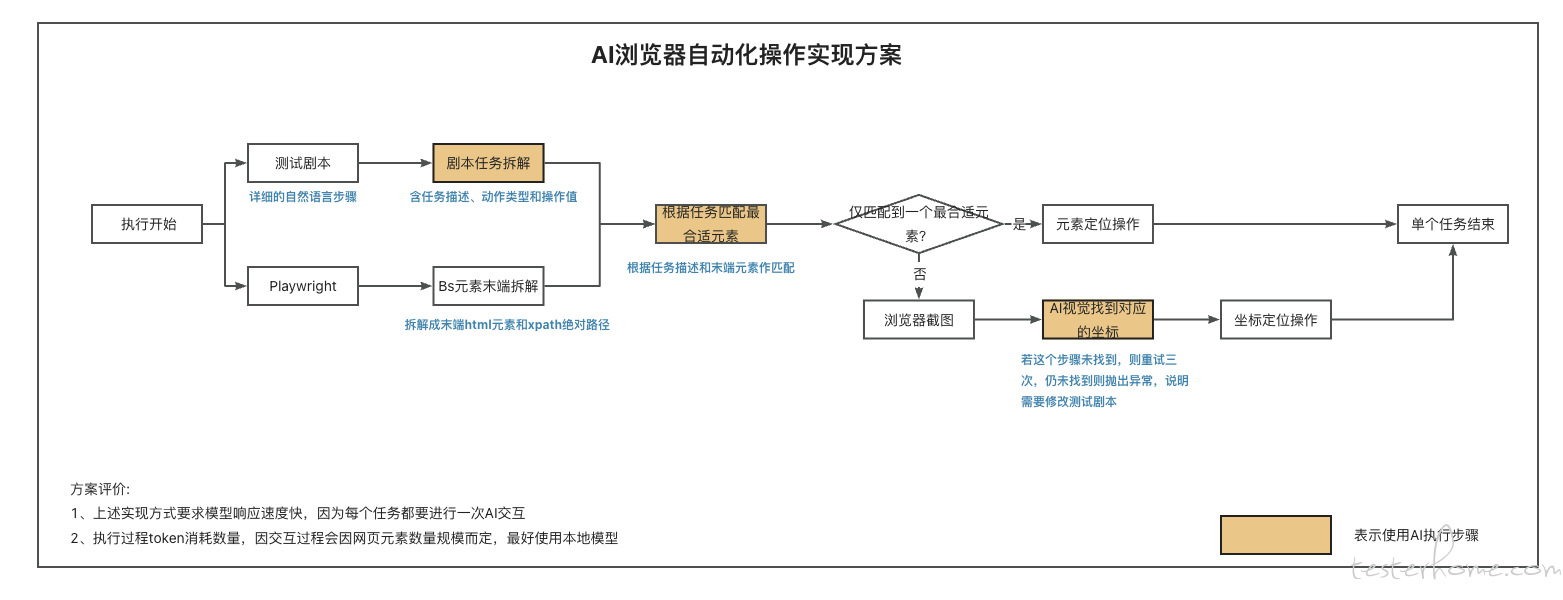
因为 deepseek 的发布,公司火急火燎的提出,要让我们把 AI 结合到测试当中,人麻了,然后自己绘制了这个方案图,目前已经写了一部分代码,自己使用的是 Gemini 模型,主打一个响应速度快,有没有大佬帮看看方案是否可行???
不现实,你可以看我发过的一篇调研。1.在线模型,token 很贵,拿来跑自动化耗不起。2.本地模型,对显卡要求太高,小公司负担不起。
总结,没钱别玩
可以看看 Langchain 与 Playwright 那一套方案
建议直接给领导大耳刮子
不现实,你可以看我发过的一篇调研。1.在线模型,token 很贵,拿来跑自动化耗不起。2.本地模型,对显卡要求太高,小公司负担不起。
总结,没钱别玩
是的,自动化太费 token 了,交互频率很高,在线模型的话就是烧钱,完全不值得,最近公司准备采购机器离线部署 deepseek,但是具体用哪个参数的模型暂不清楚,感觉小参数的模型意义也不大
上面使用的是元素匹配 + 图像识别两种方式,当 AI 无法在 html 末端元素数组中匹配到合适的元素,或者匹配到多个元素,就切换到图像识别上,让 AI 找到对应的位置返回坐标,playwright 根据坐标来做操作
deepseek 请问下如何在不花钱的情况下使用大语言模型做出个辅助测试的 demo,从而进一步做出高端大气上档次的 PPT 方便领导吹牛逼?
如果打算本地部署,不要用 deepseek,考虑用微软这个https://github.com/microsoft/OmniParser 加上找一个自然语言开源模型。DeepSeek 的小模型很蠢,大一点的对配置要求非常非常高。
如果只是想简单吹牛逼而不考虑后续,建议直接注册个 DeepSeek,然后用 web 自动化开个无头模式挂后台网页跑。直接调 API 都要钱
没多的显卡资源可以靠时间怼,最核心的问题还是没有大量人工标记好的数据源。如果能找到开源的标记数据源,训练一个专项模型(例如专门识别图标的)其实没有想象中那么难
看看字节的新项目:https://github.com/bytedance/UI-TARS-desktop,对机器资源要求挺高的。
大佬,OmniParser 有两个问题请教
1、图像识别区域的时候,用的是大模型的能力还是 OmniParser 本地的能力?
2、我看网上都是使用 web-ui 界面去操作,可以直接通过代码去交互吗?
总感觉 deepseek 火了之后,很多不了解的人都以为 AI 飞升了一样,人家是省成本强(chatglm 刚出的时候 6B 就打满 24G 显存),生成能力还是对标 o1 啊🤣
顺便放两个楼上没怎么提到的东西:
https://github.com/browser-use/browser-use(基座)
https://github.com/browser-use/web-uibrowser-use 的封装)(对
对资源要求高的一律没啥好看的,大公司的玩具。什么时候能做到单靠 CPU 就能跑起来的 自然语言测试驱动才有真正具有普适性。
现在有 ktransformers 在做这方面的优化了,很多内存足够大的人复现 24G 显存部署 R1 671B Q4 量化版本了,只是跟全显存比速度还是有差距
可以试试 broswer_use
可以站内搜索下,有同学分享的,也可以看看这个官方 api
https://python.langchain.com/docs/integrations/tools/playwright/
这是页面对比嘛,还是自动化操作捏
BrowserUse 最近也在悬赏评估其与 OmniParser 2.0 的能力差异,也许未来可以混合使用
可以关注下:https://github.com/browser-use/browser-use/issues/732