在网上搜寻性能测试相关信息,大部分都是工具的使用,脚本录制。看了很多但到自己实际压测的时候,还是不知道怎么动手,这次开贴 1.为了自己记录使用 2.想要各路大佬指出压测步骤中错误的地方,让每个想做压测的人都有一个案例可以抄袭
1.压测前景是,最近迭代了一个功能,上级给到指令:进行压测。此次为第一个坑,大部分公司的产品和主管是不会给你一个目标,只会让你去压测,怎么压什么是目标结果是什么,大家都不清楚。基于这种情况自己来罗列目标:首先我通过以往活动情况在 SLB 上看到并发连击数 1.6w 左右,在秒杀活动下达到 2.6w。此次目标为 SLB 达到如此连接数下每个压测场景需要达到 90% 响应时间 2S 以下,ecs 和 rds 内存和 cpu 不超过 70%。吞吐量本人没什么经验不知道如何去估计,只能走一步看一半
2.压测方案,压测工具是用到 jmeter,压测场景以页面为维度,比如进入首页作为一个场景,那首页下的 5 个接口都作为一个场景压测。(这里我也不清楚是否对错,希望有大佬看见能够指点)。再网上了解一台 4 核 8G 的电脑正常就支持 500 个并发,所以会用到阿里云上面的压测工具,这个上面可以支持开多台机器好达到 1w 起步的并发。(公司由于压测不是很平凡,所以没有压测机器给与压测,这块想确认一下:我 slb 到达 2w 是不是一定得让线程数达到这个值)
3.压测环境搭建:这个由运维人员帮助,搭建了一个压测环境,这块不多做描述,对我而言压测环境方便在,我可以关闭接口的验签,然后自己写了一个任意手机号获取 token 的接口,方便自己造数据使用。
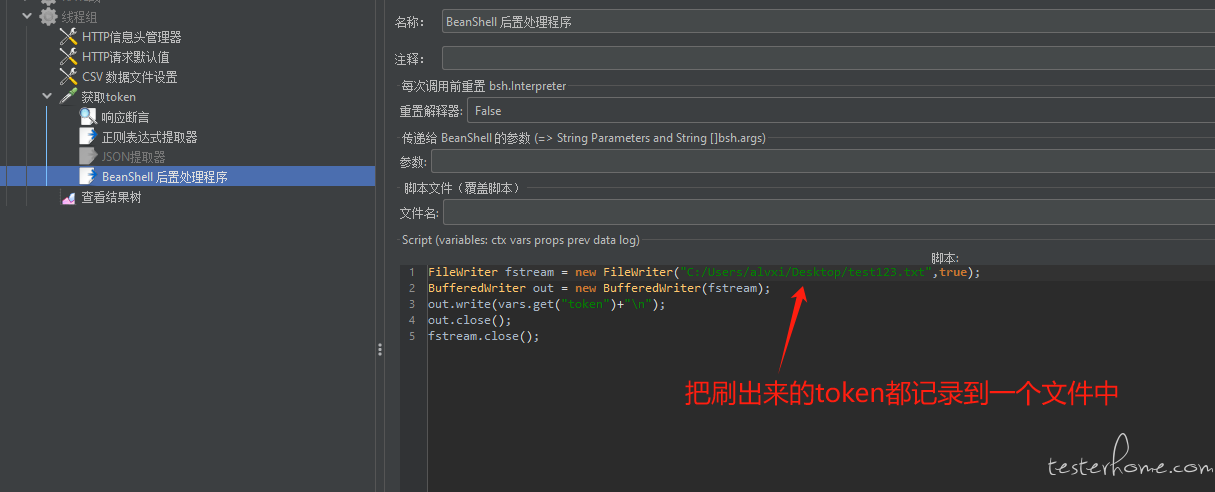
4.压测数据准备:会员数据通过准备的测试接口(传手机号返回 token,如果手机号会员不存在则自动创建会员);活动数据直接通过接口调用创建出来。为了避免获取 token 接口影响真实压测数据,先写脚本把所有 token 取出到 csv 文件中给后面压测接口使用
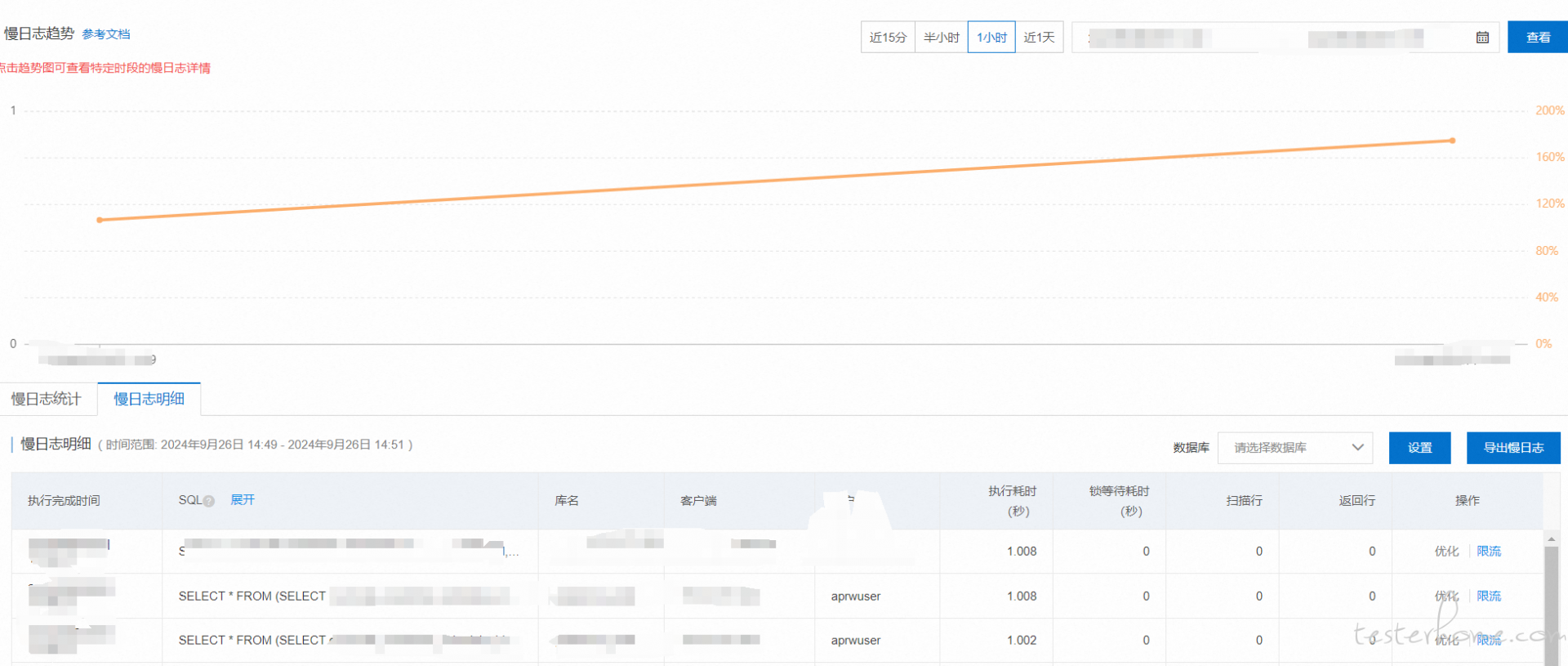
开始压测,首先本地进行压测,压测活动主页场景包含,活动信息查询,子活动列表查询,用户活动参与信息接口,订阅消息模板。本地线程 700 持续 2 分钟:压测结果:SLB 达到 700 连接数,吞吐量总体 200,响应时间 95% 为 12s,异常无。压测结果感人查看了一下,数据库压力直接 100%,应该是这个地方导致,查看了一下索引什么都已经加过了,目前还没有解决方案。等待后续

好消息,找到一个地方没走索引,先加上试试
无敌;加完之后吞吐量达到 1200,之前每个 sql 都要全表扫描 5w 条数据,改完直接一条。感谢索引