问答 封装 playwright,写了一个 UI 自动化平台,有一些问题想问问大家怎么处理
首先介绍一下我的平台
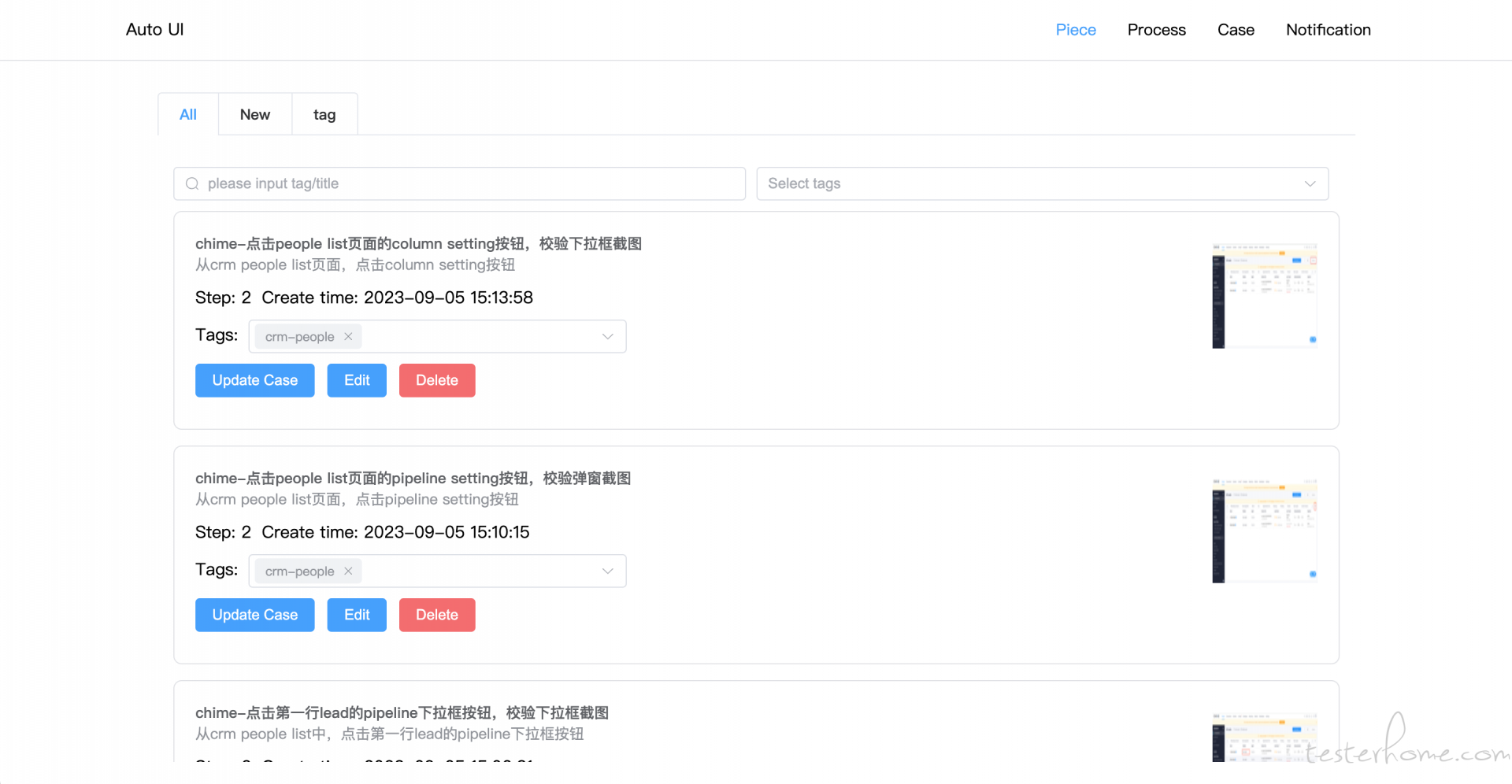
如图,平台分为了 3 层:
piece 层:一个点击(输入、keyword)操作 + 一个等待某元素加载(或等待一个固定时间)+ 一个对元素截图(获取文案)校验=一个 piece
我称之为一个最小操作单元,不可被分割
process 层:多个 piece 合成一个 process;对一个 process 添加数据集,可生成 N 个 case
case 层:对案例执行的管理,并可查看执行结果
结果校验:文案直接做比对,图片用的 AI 做图片比对
技术栈:python+django+playwright+tensorflow+docker+gitlab CI/CD
问题:
1、执行时使用的线程池开 8 个线程跑,现在案例有 200+ 条,执行的很慢;现在在做分微服务和代码重构,以前都是一个镜像搞定,现在要把平台分为三个微服务,一个调用接口处理数据库数据,一个执行案例(跑 playwright),一个 AI 图片比对;
我想问,在多线程执行案例时,playwright 异步执行会不会比同步执行效率更高?这样分微服务是否能提高一点性能,是否还有更好的做法?是否还有其他的方法提高性能?
2、接口请求 100+ 张图片时,部分图片接口报错 502 加载不出来,图片已经是压缩图片了(一个图 5KB 左右),感觉不是网络 IO 的问题,不知道从哪里下手解决。
3、被测系统,部分页面会有通过接口做的控制蒙层、loading 状态、toast 提示,这个时候做截图校验总是会不准确;想等待蒙层、loading 状态、toast 提示结束再做截图,但是这些瞬时的元素又很难捕捉,不知道怎么处理,想请教大家有什么好的办法?
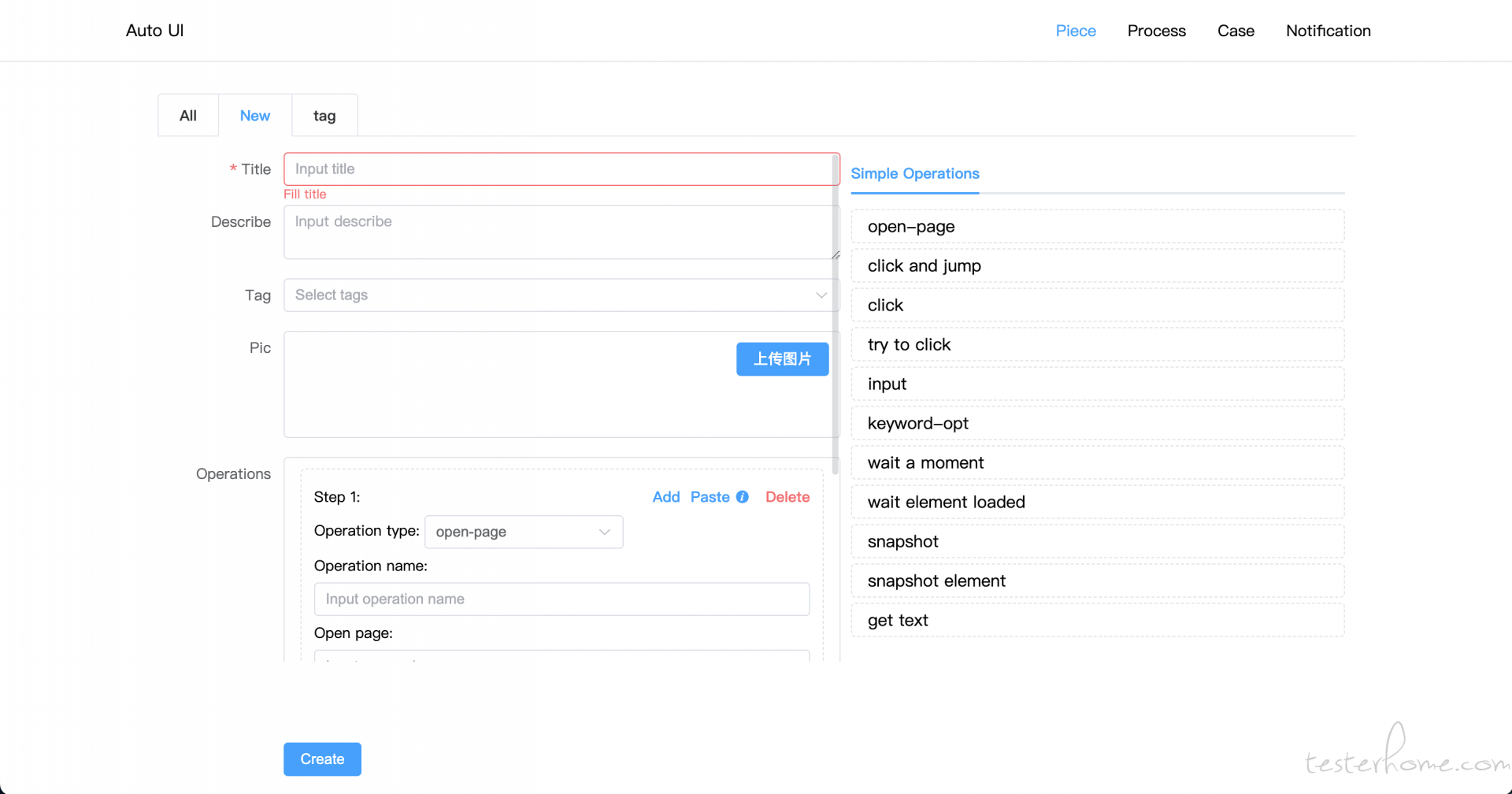
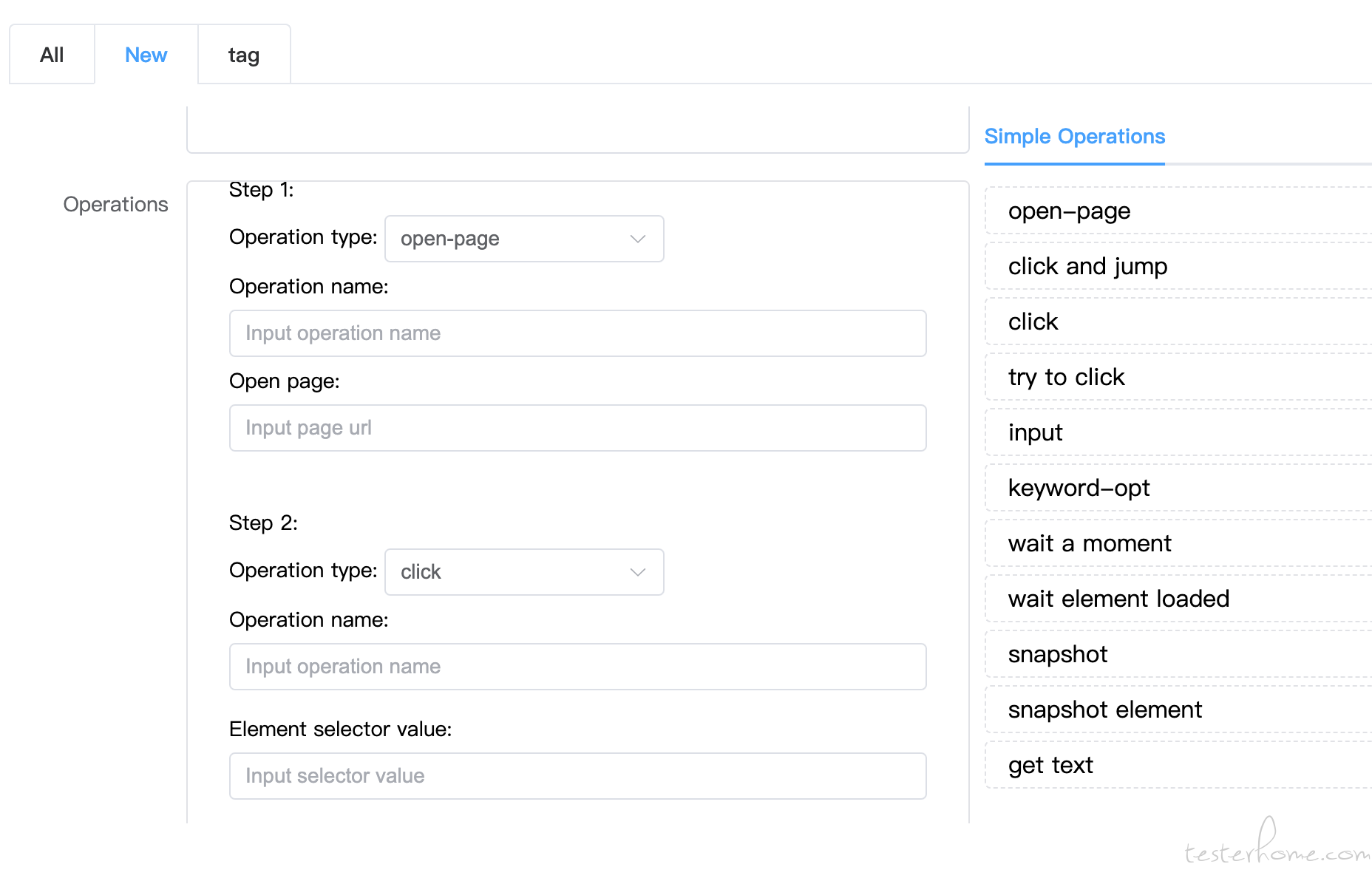
4、如图,我生成 piece 的方式,是用这样点击添加组建的方式。我现在想,可以直接写一个长串的文案,后端读取文案的关键字的方式,来自动生成案例;但是不确定那种方式会更好;后者的话我没发现明显的优势,但后期我感觉以后可以做到,直接通过 chatgpt 读取 prd 输出特定格式的文案来生成 piece。
 我想帮忙写页面,虽然前端技术也很烂
我想帮忙写页面,虽然前端技术也很烂