框架结构
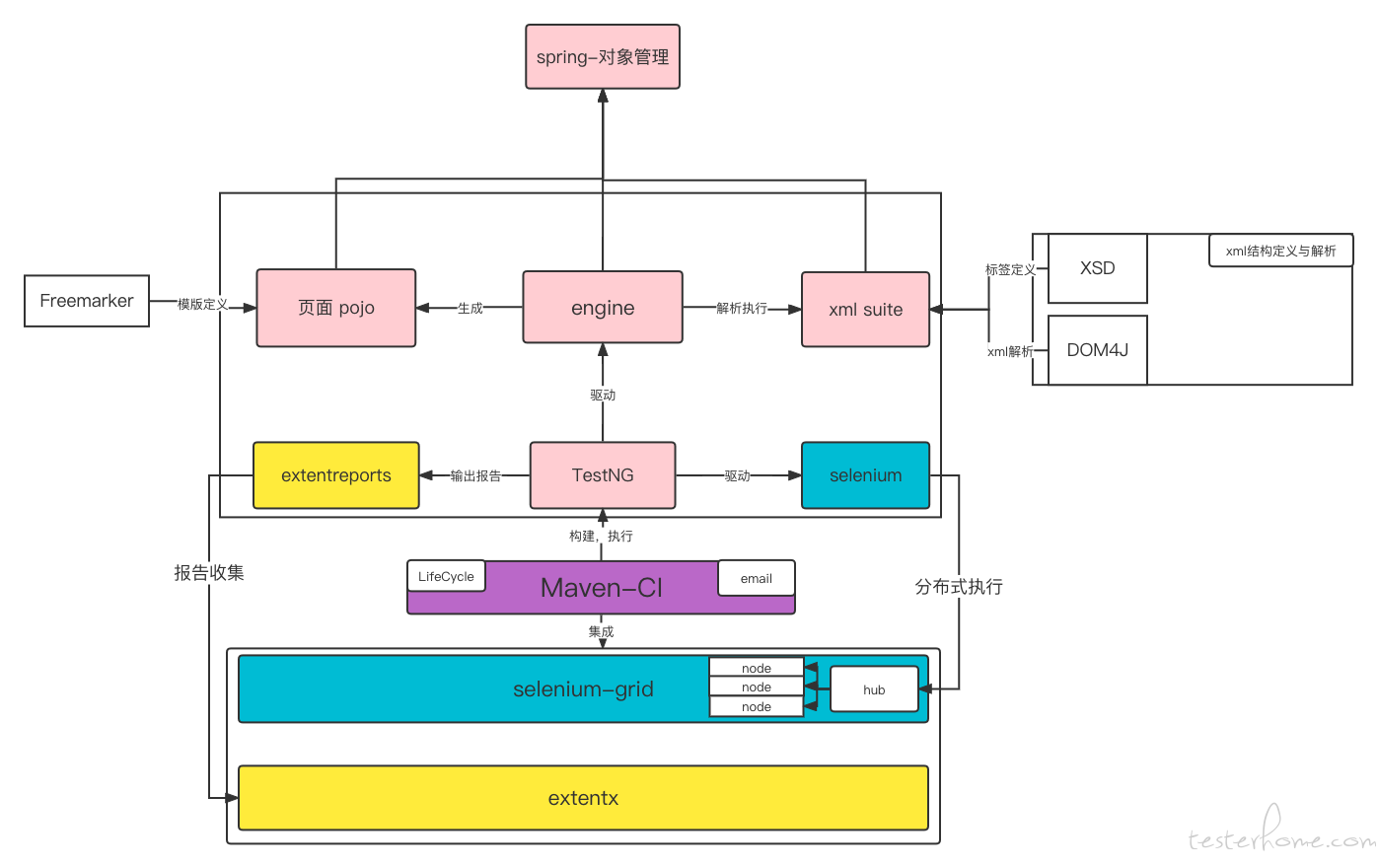
框架基于 PO 模型进行设计,将页面元素与操作进行拆分,减少页面改动时的维护成本;同时使用 xsd 自定义 xml 标签,通过解析 xml 来驱动 selenium 进行执行,减少了一定的语言学习成本。
主要功能
- 基于 selenium-grid 做并发执行
- 可基于 xml 编写脚本
- 执行步骤可插入自定义函数
- 基础操作 (点击、hover、输入、值比较、切换 iframe、切换页面、关闭页面、模板匹配等)
- 测试报告收集
设计思路
- webUI 自动化大部分都基于 selenium 来进行
- PO 模型是 webUI 自动化中应用最广的设计模式
- selenium 执行时,可以通过 DataProvider 提供测试数据
- 常见的测试数据管理方式无外乎存在 db / 存在本地文件,并且都是结构化数据
- Java 有 DOM4J 库,能够很方便的解析 DOM 文档,同时 DOM 中的 XML 可以灵活定义,描述性也比较强,因此选用 XML 作为测试数据管理这样就有了一个框架大致的运行流程
- 初始化流程数据以及基础配置
- 初始化 webDriver
- 遍历解析后的流程数据进行执行
- 输出测试报告
- 关闭 webDriver
设计初期的明显问题
Q1:如果只能调用内置方法的话,灵活性不够
A:因此引入了 Spring 作为实例管理,这样就只需要在流程数据中使用指定标签 +beanName 就可以实现自定义方法的执行了
Q2:webUI 自动化通常执行时间过长,如何缩短?
A:引入 selenium-grid 做分布式执行,并且可以隔离数据
Q3:元素定位有没有更为准确和快捷的方式?
A:引入特征识别、模板匹配、OCR 等图像算法
基本功能
XML 描述
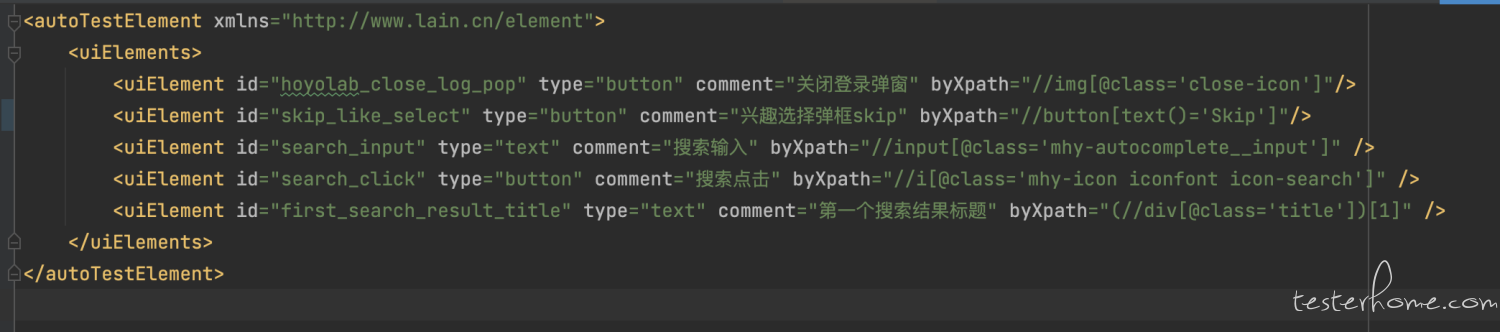
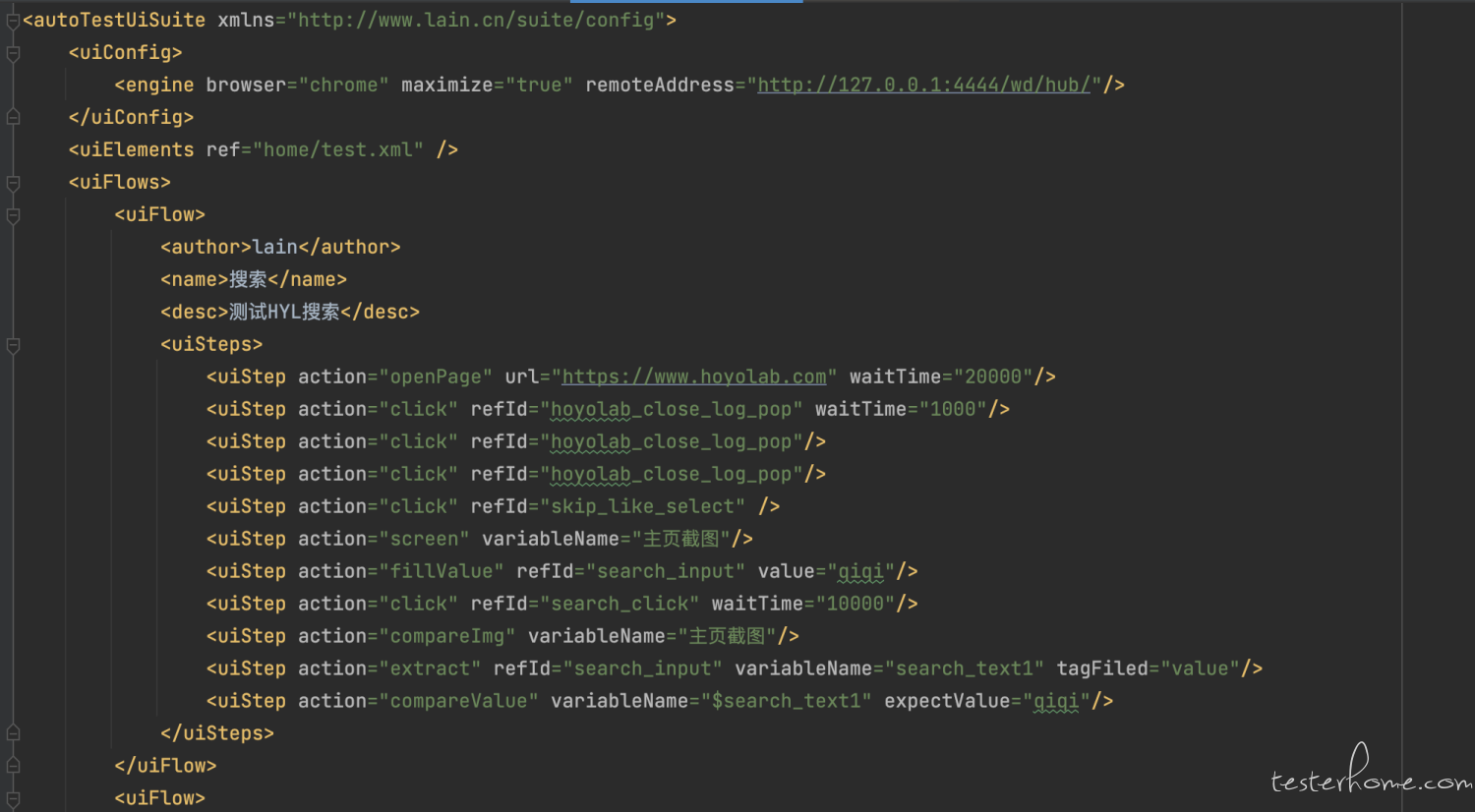
使用具备自描述性的 XML 进行脚本编写,降低门槛
如果想要新增标签/属性,在 XSD 中定义和对应的 entity 增加字段后,在 AutoTestSuiteParser 类中增加赋值即可
元素复用
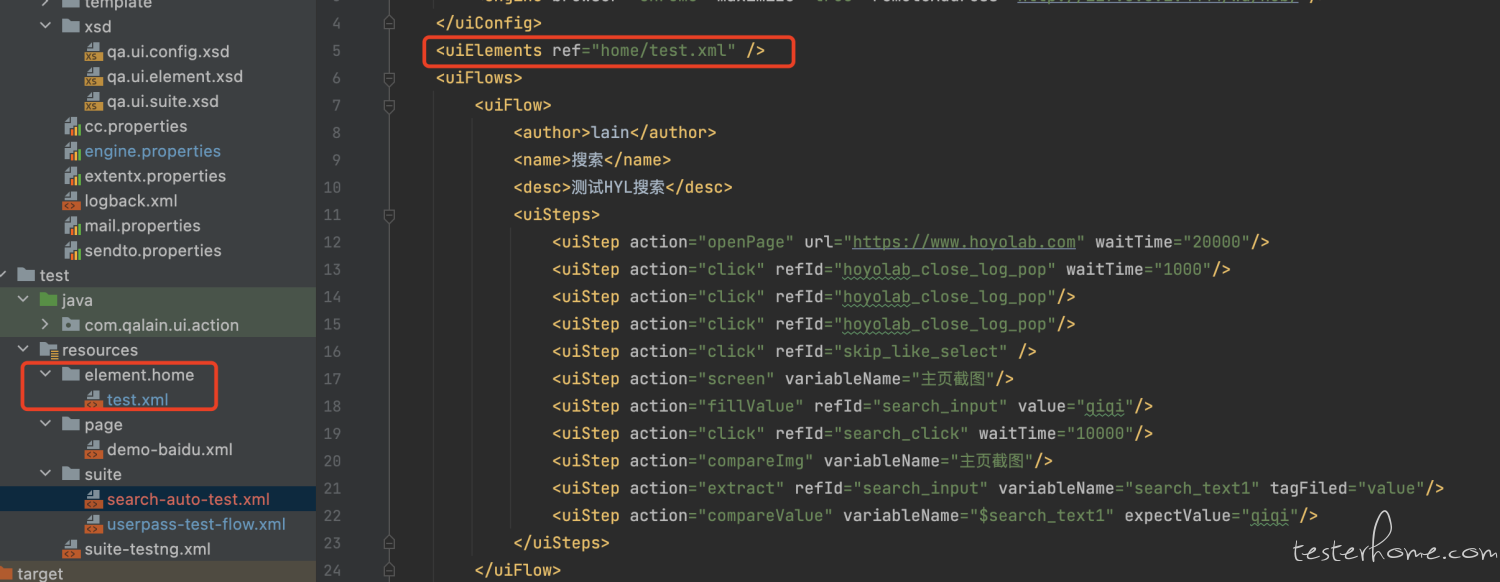
通过 ref 标签引用 element 文件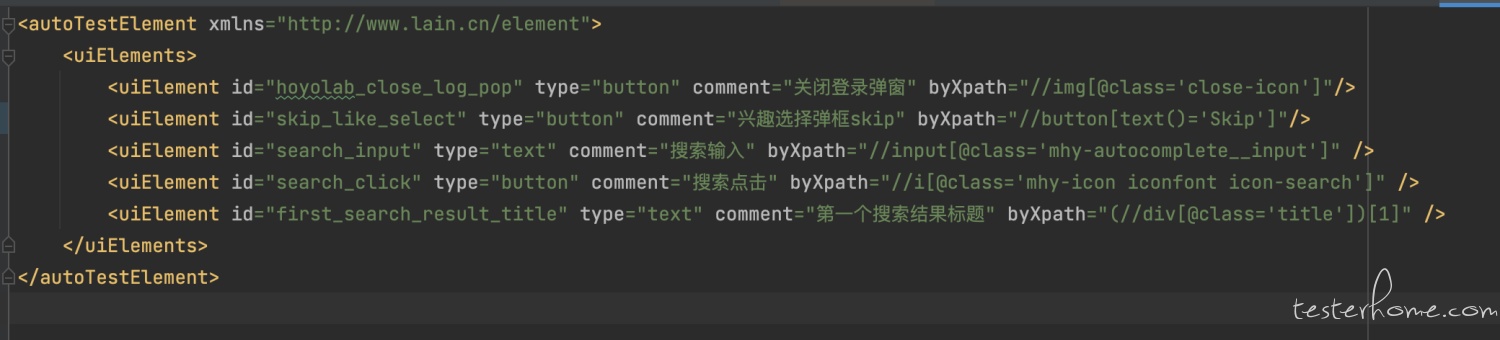
即可使用,重复引用可实现复用
提取与比较
example: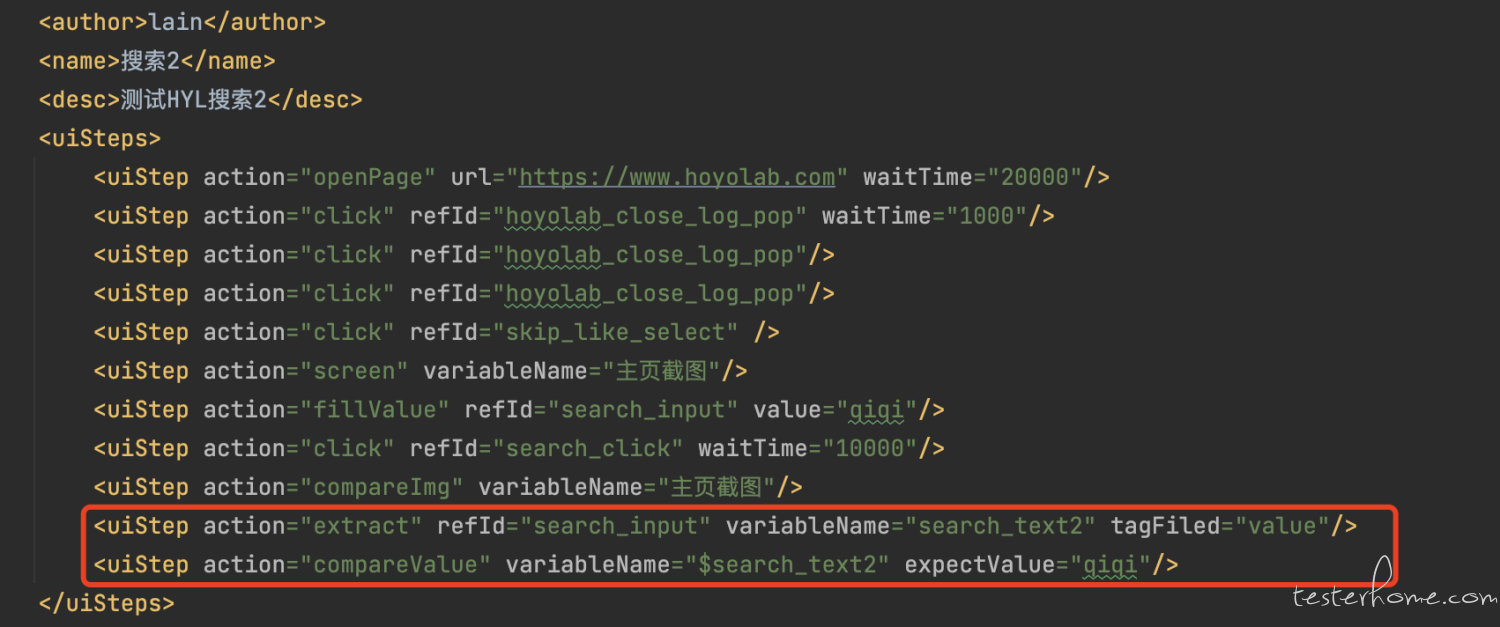
通过指定 html 标签的属性获取对应值,和 variableName 以 kv 的形式存储在 threadLocal 的 Map 中,从而在同一 testFlow 的后续流程中以 $variableName 进行提取,与期望值比较
模板匹配点击
使用 JavaCV 进行模板匹配并点击的操作
eg:
使用属性 templateImgName 即可
模板图片存放于 src/test/template_img 下,源图片则是当前浏览器窗口截图
tips:使用模板匹配时,不建议在本地执行,会大概率失败,因为本地操作可能会干扰鼠标原始定位
并发与分布式执行
通过反射读取 engine.properties 文件中的配置,可动态配置并发执行用例数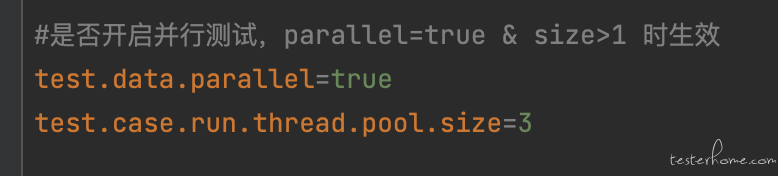
并发执行时将会 send task 到 selenium-hub,并进行分发,加快执行速度
执行自定义方法
使用 custom 标签时,指定 customFunction 指定类的的 bean 名称,并且该类应该实现 ICustomAction 的 execute 方法
方法 bean 名称为@Service() 中的 beanName
常用操作封装
环境部署
selenium-grid
m1 (arm64)
version: "3"
services:
selenium-hub:
image: seleniarm/hub:4.0.0-beta-1-20210215
container_name: selenium-hub-arm
ports:
- "4444:4444"
environment:
- GRID_MAX_SESSION=50
- GRID_TIMEOUT=200
- START_XVFB=false
- GRID_CLEAN_UP_CYCLE=200
chrome:
image: seleniarm/node-chromium:4.0.0-beta-1-20210215
volumes:
- /dev/shm:/dev/shm
depends_on:
- selenium-hub
environment:
- SE_EVENT_BUS_PUBLISH_PORT=4444
- SE_EVENT_BUS_HOST=selenium-hub
- SE_EVENT_BUS_SUBSCRIBE_PORT=4443
- NODE_MAX_INSTANCES=5
- NODE_MAX_SESSION=5
- GRID_CLEAN_UP_CYCLE=200
intel(x86)
version: "3"
services:
selenium-hub:
image: selenium/hub
container_name: selenium-hub
ports:
- "4444:4444"
environment:
- GRID_MAX_SESSION=50
- GRID_TIMEOUT=900
- START_XVFB=false
chrome:
image: selenium/node-chrome
volumes:
- /dev/shm:/dev/shm
depends_on:
- selenium-hub
environment:
- SE_EVENT_BUS_PUBLISH_PORT=4444
- SE_EVENT_BUS_HOST=selenium-hub
- SE_EVENT_BUS_SUBSCRIBE_PORT=4443
- NODE_MAX_INSTANCES=5
- NODE_MAX_SESSION=5
- GRID_CLEAN_UP_CYCLE=200
start.sh
#! /bin/sh
docker-compose up -d --scale chrome=2
chrome=2 表示 selenium-grid 集群的节点数量,chrome 为 docker-compose 中的 service name
启动 shell 脚本,docker ps 查看是否启动成功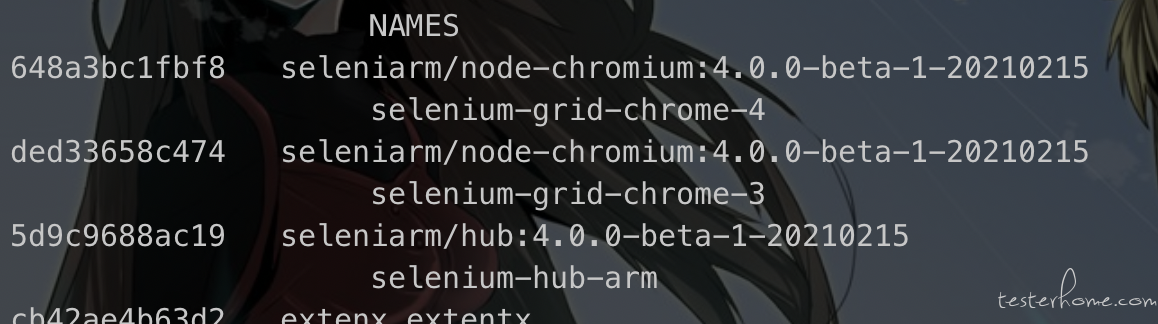
访问 localhost:4444 / 虚拟机 ip:4444
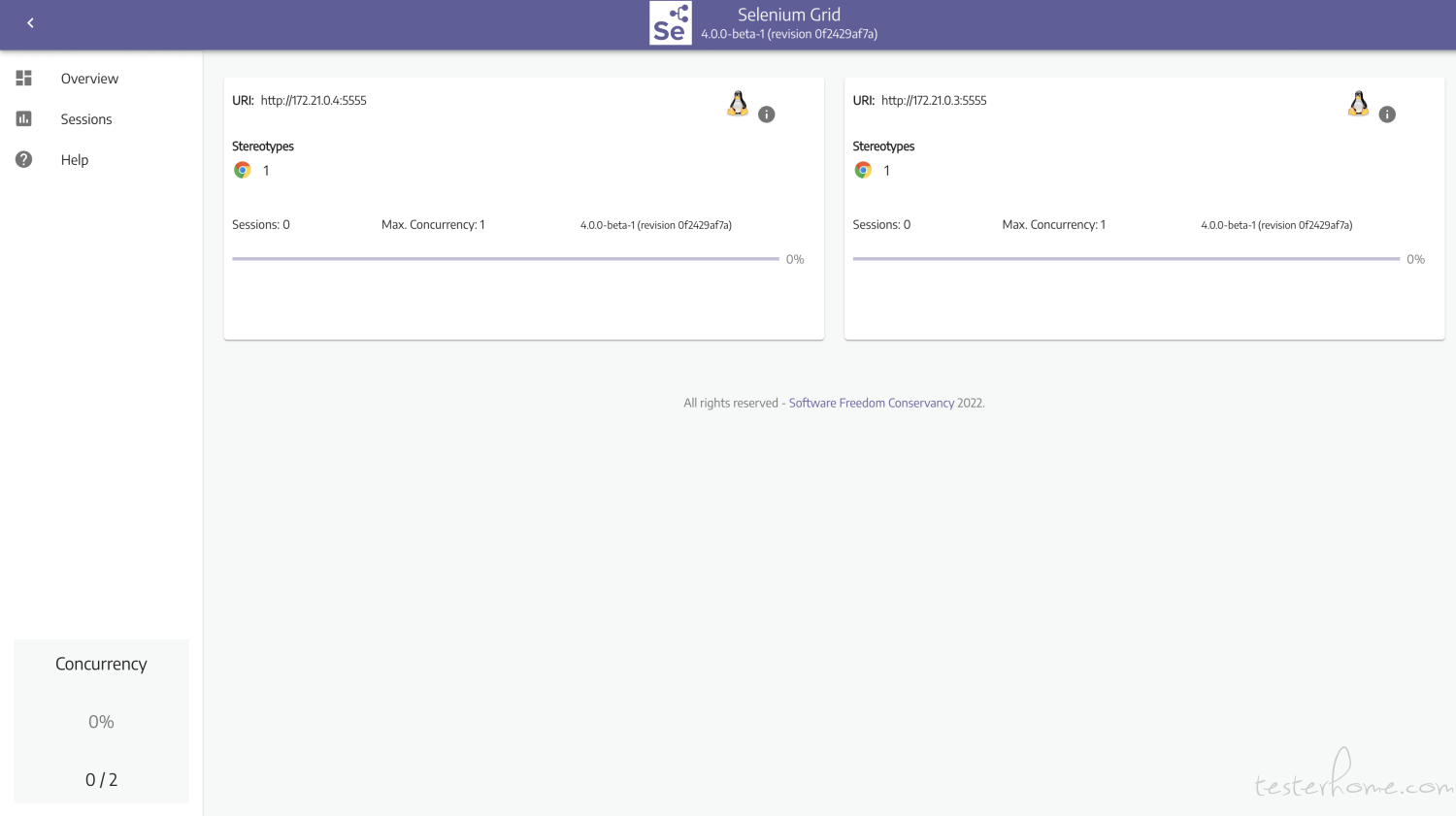
Extentx
创建 Dockerfile 文件
FROM node:alpine
LABEL maintainer="lain"
RUN mkdir -p ./app
WORKDIR ./app
RUN apk add --no-cache git
RUN git clone https://gist.github.com/3c4f35a41c58a55a0ffd00c3e64142c8.git tmpChange
RUN git clone https://github.com/anshooarora/extentx.git
RUN mv tmpChange/connections.js extentx/config/connections.js
RUN rm -rf tmpChange
WORKDIR ./extentx
EXPOSE 1337
RUN npm set registry https://registry.npm.taobao.org
RUN npm config set registry https://registry.npm.taobao.org
RUN npm config set disturl https://npm.taobao.org/dist
RUN npm install
CMD ["./node_modules/.bin/sails", "lift"]
构建镜像docker build -t extentx .
创建 docker-compose.yml 文件
version: '3.6'
services:
extentx:
build: .
environment:
- MONGODB_PORT_27017_TCP_ADDR=mongo
links:
- mongo:mongo
ports:
- 1337:1337
mongo:
image: mongo:3.4
ports:
- 27010:27017
docker-compose up -d启动
访问 localhost:1337 即可
打包到本地仓库
下载附在项目中的 extentsReport-1.0-SNAPSHOT.jar ,提取出 jar 包中的 pom 文件,和 jar 放在同一级目录下,执行命令mvn install:install-file -Dfile=extentsReport-1.0-SNAPSHOT.jar -DartifactId=extentsReport -DgroupId=com.antigenmhc -Dversion=1.0-SNAPSHOT -Dpackaging=jar -DpomFile=pom.xml
即可
JavaCV (以 arm64 为例)
mac m1 (arm64)
前置环境为已下载 arm64 版本的 JDK
- 安装并设置环境变量
# 升级 brew
brew update
# 安装 cmake
brew install cmake
# 安装 ant
brew install ant
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_331.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
export JAVA_AWT_INCLUDE_PATH=$JAVA_HOME
export JAVA_AWT_LIBRARY=$JAVA_HOME
export JAVA_INCLUDE_PATH=$JAVA_HOME/indclude
export JAVA_INCLUDE_PATH2=$JAVA_HOME/include/darwin
export JAVA_JVM_LIBRARY=$JAVA_HOME
- 打开 Java build
brew edit opencv
找到-DBUILD_opencv_java=OFF 修改为-DBUILD_opencv_java=ON
在上面的参数之后添加参数:-DOPENCV_JAVA_TARGET_VERSION=1.8,防止使用高版本 JDK 进行编译
- 编译
brew install --build-from-source opencv
生成 jar 和 dylib:成功后在 /opt/homebrew/Cellar/opencv/4.7.0/share/java/opencv4 这里会生成 libopencv_java470.dylib 和 opencv-470.jar
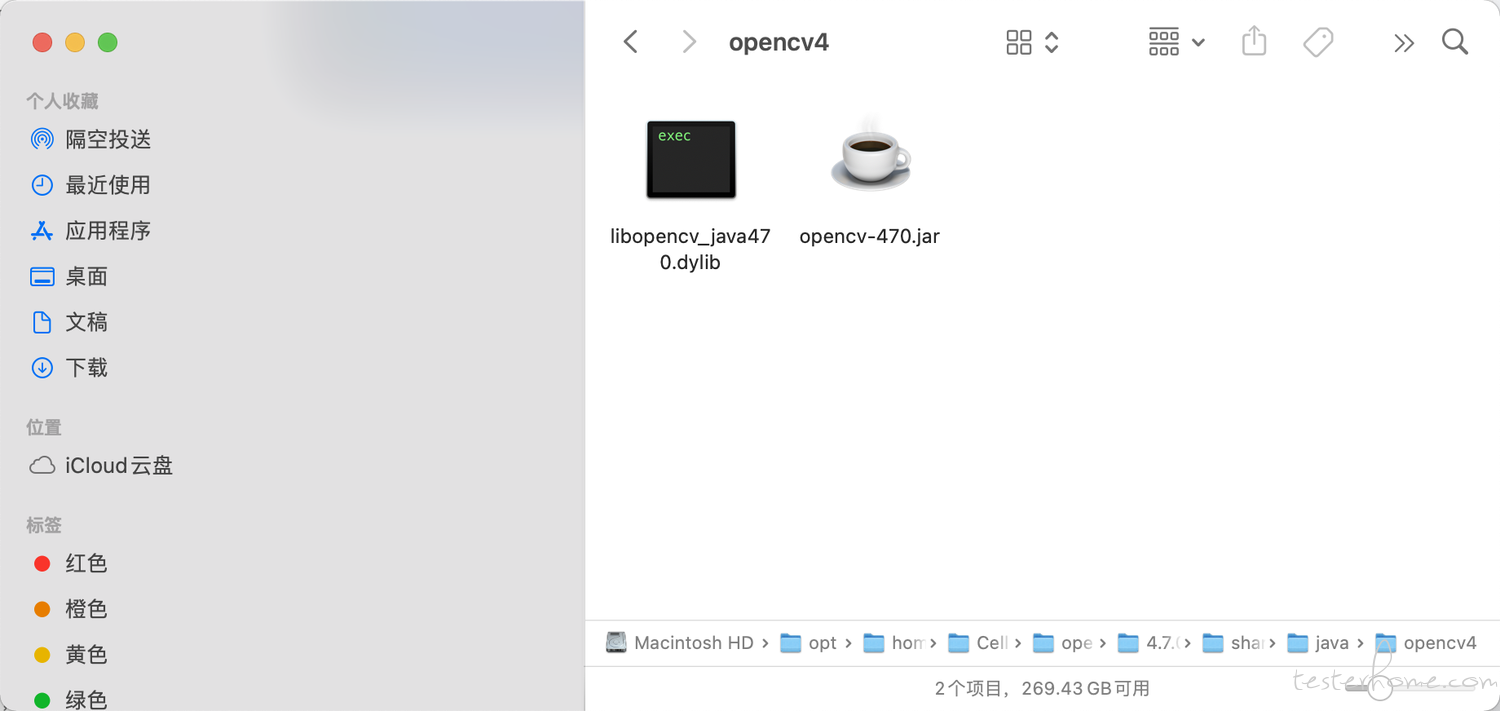
将 jar 和 dylib 加入项目
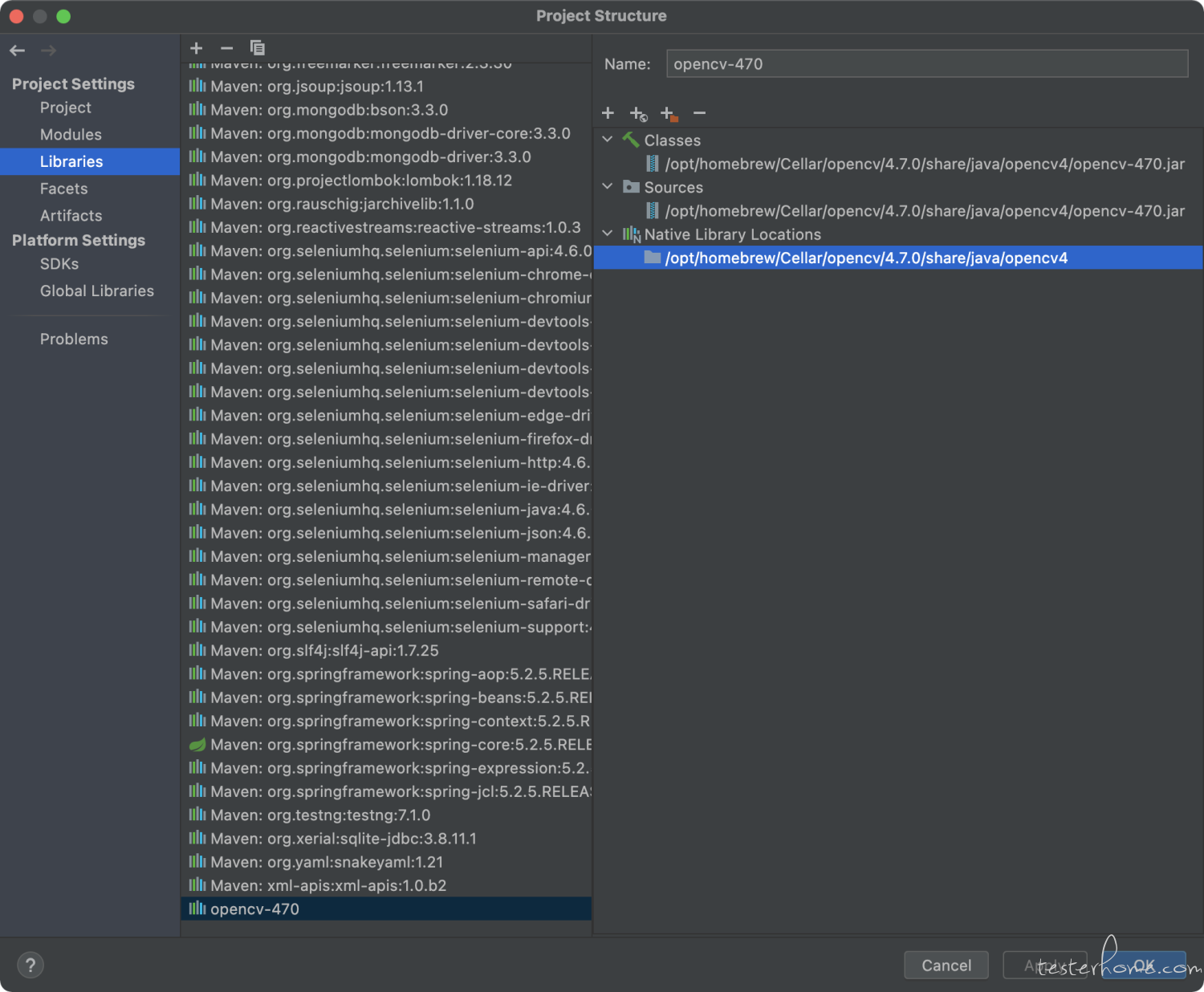
设置项目 JDK 为刚才用来编辑 (即 JAVA_HOME ) 的 JDK引入依赖
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>javacv-platform</artifactId>
<version>1.5.7</version>
</dependency>
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>javacpp</artifactId>
<version>1.5.7</version>
</dependency>
- 运行 demo
//待匹配图片
Mat src = imread("filePath",Imgcodecs.IMREAD_GRAYSCALE);
Mat mInput=src.clone();
// 获取匹配模板
Mat mTemplate = imread("filePath",Imgcodecs.IMREAD_GRAYSCALE);
/**
* TM_SQDIFF = 0, 平方差匹配法,最好的匹配为0,值越大匹配越差
* TM_SQDIFF_NORMED = 1,归一化平方差匹配法
* TM_CCORR = 2,相关匹配法,采用乘法操作,数值越大表明匹配越好
* TM_CCORR_NORMED = 3,归一化相关匹配法
* TM_CCOEFF = 4,相关系数匹配法,最好的匹配为1,-1表示最差的匹配
* TM_CCOEFF_NORMED = 5;归一化相关系数匹配法
*/
int resultRows = mInput.rows() - mTemplate.rows() + 1;
int resultCols = mInput.cols() - mTemplate.cols() + 1;
Mat gResult = new Mat(resultRows, resultCols, CvType.CV_32FC1);
Imgproc.matchTemplate(mInput, mTemplate, gResult, Imgproc.TM_CCORR_NORMED);
Core.normalize(gResult, gResult, 0, 1, Core.NORM_MINMAX, -1, new Mat());
Core.MinMaxLocResult mmlr = Core.minMaxLoc(gResult);
Point matchLocation = mmlr.maxLoc;
double x = matchLocation.x + (mTemplate.cols() / 2);
double y = matchLocation.y + (mTemplate.rows() / 2);
System.out.println(new Point(x, y));
运行项目
项目结构及说明
项目的大致结构如下
qa-ui-test-demo
├─ screen:截图
├─ src
│ ├─ main
│ │ └─ resources
│ │ ├─ css
│ │ ├─ driver:浏览器驱动
│ │ │ ├─ chromedriver
│ │ │ └─ geckodriver
│ │ ├─ cc.properties:邮件发送方邮箱
│ │ ├─ extentx.properties:连接 extentx 平台配置
│ │ ├─ engine.properties:测试报告以及核心配置
│ │ ├─ mail.properties:邮件配置
│ │ └─ sendto.properties:邮件接收方邮箱
│ └─ test
│ ├─ java
│ │ └─ com
│ │ └─ qalain
│ │ └─ ui
│ │ └─ action:java 脚本
│ └─ resources
│ ├─ page:page xml,用来转为 page pojo 的
│ │ └─ demo-baidu.xml
│ ├─ suiteflow:自动化测试流程文件
│ │ └─ demo-flow.xml
│ └─ suite-testng.xml
├─ pom.xml
└─ README.md
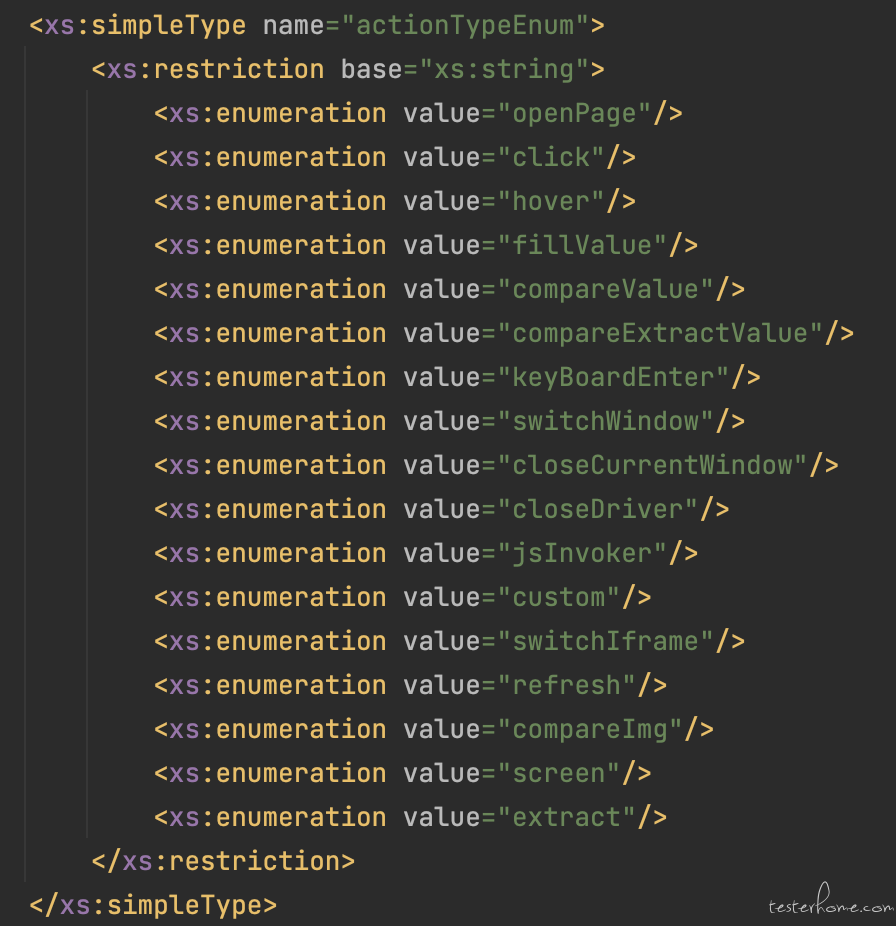
因为经过 xml 二次封装了,所以需要了解常见标签
- action 为 openPage 时,需要设置的属性为 url;
- action 为 click 时,需要设置的属性为 refId;
- action 为 fillvalue 时,需要设置的属性为 elementId 和 value;
- action 为 compareValue 时,需要设置的属性为 refId 和 expectValue;
- action 为 keyBoardEnter 时,无需设置其他属性;
- action 为 swithWindow 时,无需设置其他属性;
- action 为 closeCurrentWindow 时,无需设置其他属性;
- action 为 closeDrive 时,无需设置其他属性;
- action 为 jsInvoker 时,需要设置的属性为 jsCode;
- action 为 custom 时,需要设置的属性为 customFunction;
- action 为 hover 时,无需设置其他属性
直接运行
- 拉取项目:https://github.com/iwakura-lain/UITestCore.git
- 在 idea 中打开项目
- 默认拉下来的项目使用的是 remote 模式执行测试,如需改为本地进行,则需要将下图中 engine 的属性给去掉
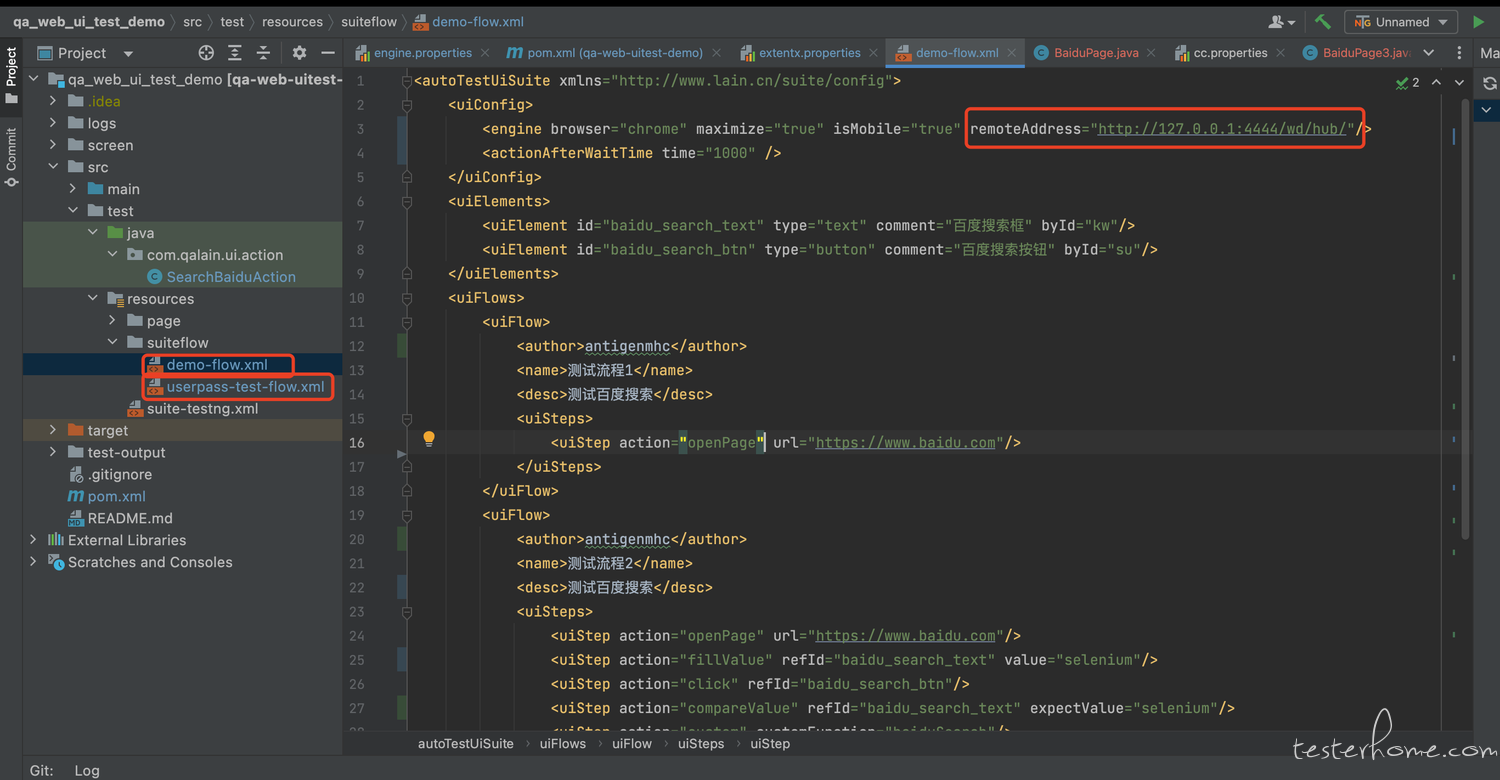
- 运行 testng 的 xml 文件
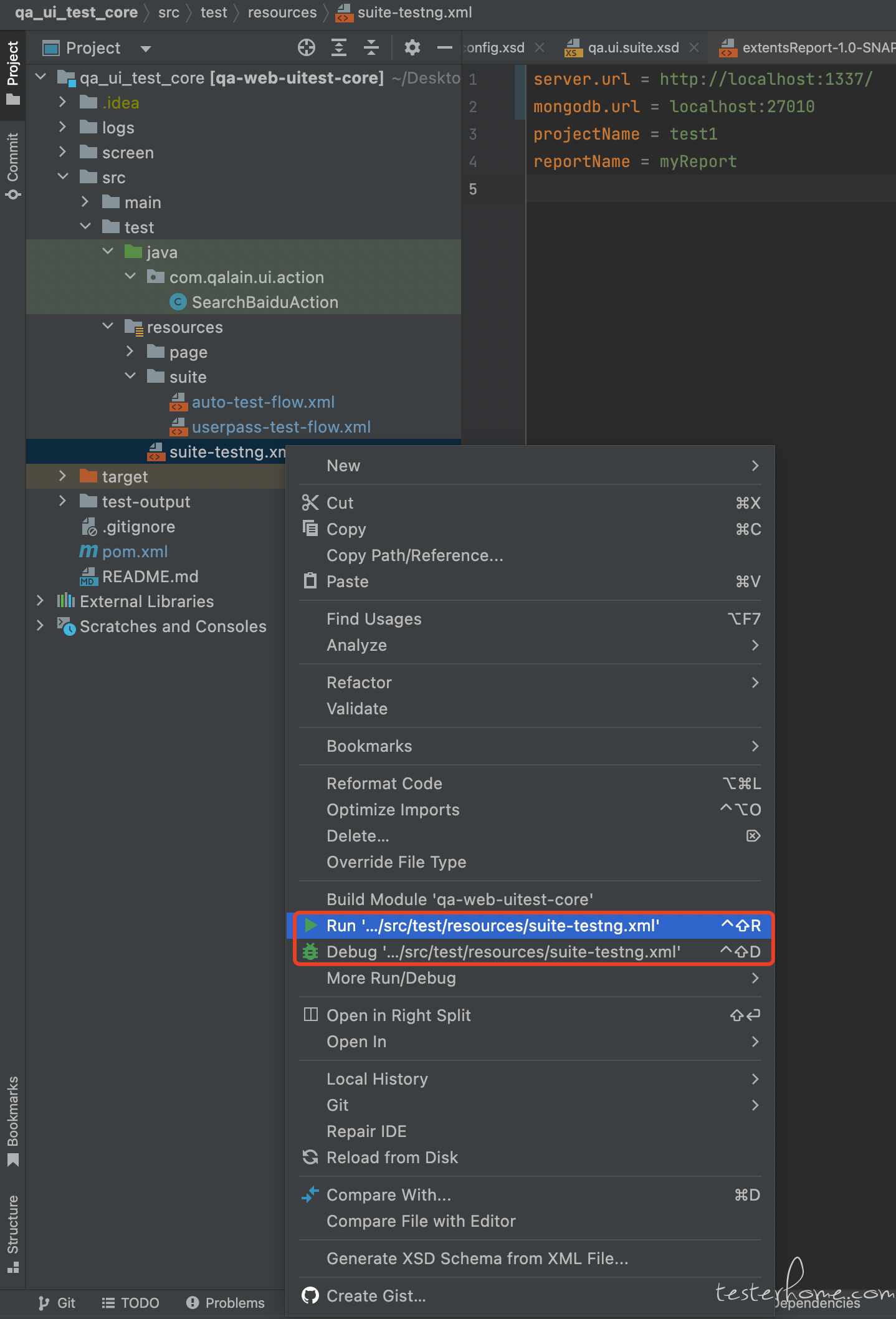
- 或者在右侧 maven test
- 如果是 remote 模式,则可以在 selenium-grid 的 session 页面查看执行;如果是本地执行,则会启动本地浏览器 (注意,驱动和浏览器版本需要对应)
脚手架运行(暂不推荐,没有稳定的 Nexus)
- 拉取项目:https://github.com/iwakura-lain/UITestCore.git 和 https://github.com/iwakura-lain/UITestScaffold.git
- 同直接运行,修改配置文件,远程模式等
- 打开 UITestCore 项目,在右侧 maven-Lifecycle 中执行 package
- 然后会在项目目录/target 目录下生成 jar 包,执行命令 mvn install:install-file -Dfile=qa-web-uitest-core-1.1.0-RELEASE.jar -DgroupId=com.lain. qatest -DartifactId=qa-web-uitest-core -Dversion=1.1.0-RELEASE -Dpackaging=jar -DpomFile=../pom.xml
测试报告&报告收集
在执行完测试后,项目的 test-output 文件夹下会出现测试报告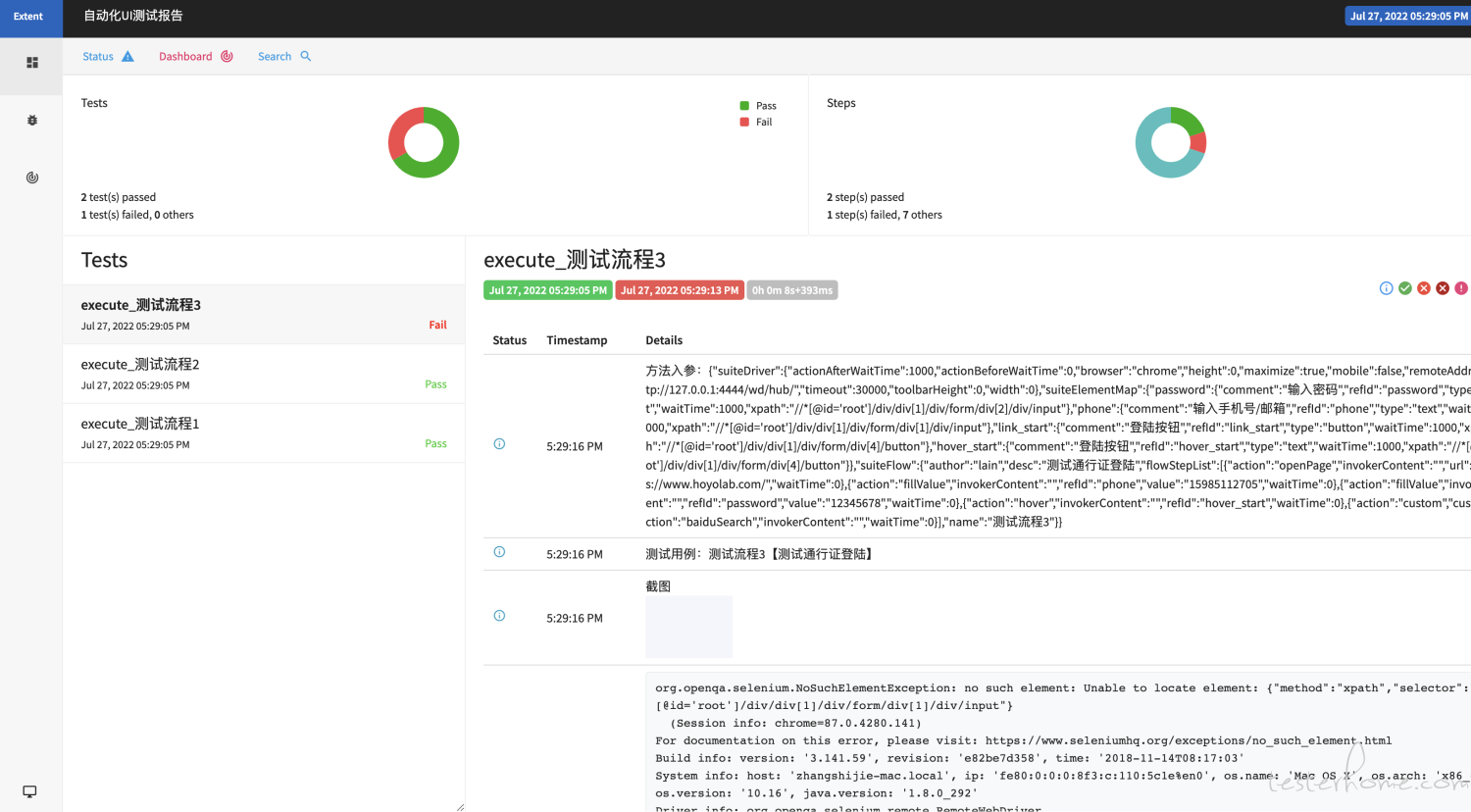
同时也会把测试结果统计到 extentx 上
总结
框架的设计借鉴了许多其它自动化框架,仍然有许多可以完善的地方。由于我是去年校招刚入行半年的新手,所以可能有很多痛点感受不到,导致现在做的功能可能有用也可能是鸡肋。希望大佬们能够多多提一些意见,感谢~