研发效能 干货分享 | 质量度模型助力风险决策水平提升
背景
无论是测试任务的执行风险的决策还是流程的流转都依赖于人工经验然后会影响质效,这个课题主要分享的就是我们正在探索和实践的一条路径,基于机器学习的方式,去让计算机自己学习辅助和替代人工决策。
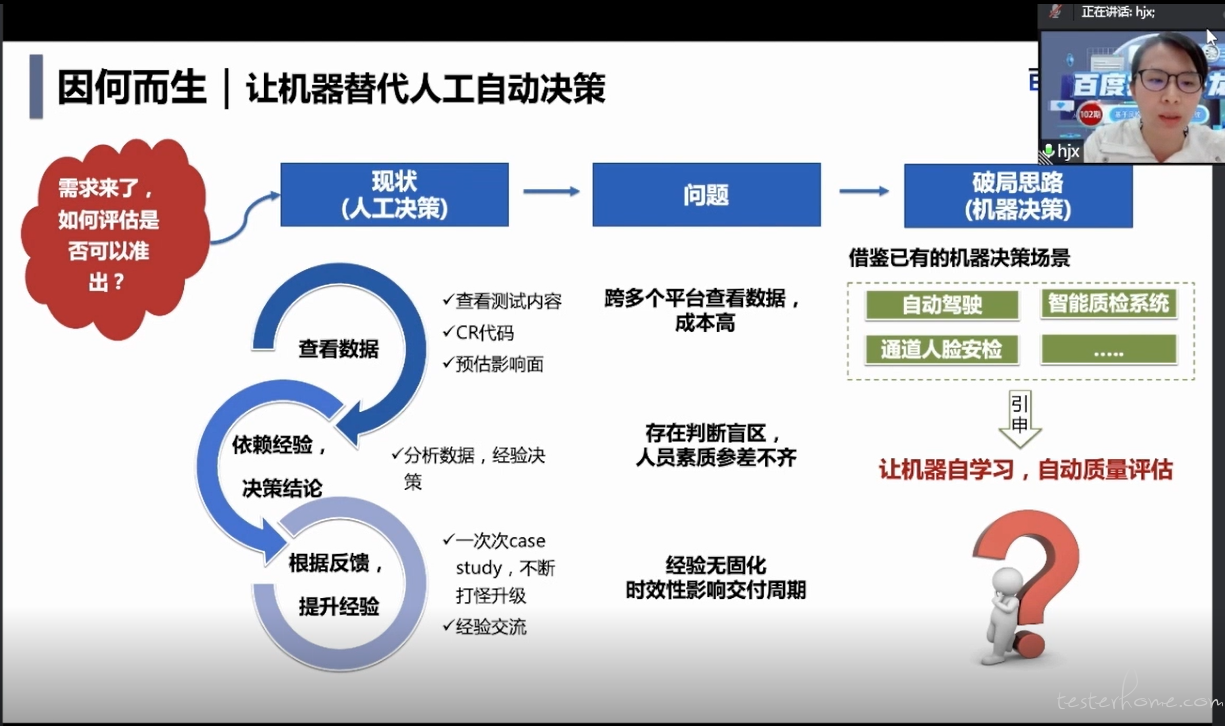
一个需求,如何评估是否可以准出的,如果是以人工决策的方式,一般是分为 3 个步骤:
- 1、查看交付过程涉及到的所有数据。包括查看测试内容、代码以及人工平均应该去预估影响面
- 2、依赖经验,结合这些数据去给出决策的结论。包括决策可以进入下一个流程流转,或者是需要 qa 再去补充测试
- 3、跟进这个卡片,在后续环节是否有 bug 漏出,如果有 bug 漏出会去做一些 case 打底。
经过一次次这种 case study 的学习,以及一些经验的交流,QA 不断的去提升自己的测试认知,从而在下一次的需求,提升这个质量保障的一个质量。基于这种人工决策的方式,他其实在也是有一些弊端的:
- 1、查看数据,一个人的话,需要跨多个平台,查看各种测试活动的数据,整个查看数据的重复性比较大,而且成本其实是比较高的
- 2、依赖于人工经验去给出决策结论的话, 人员素质其实是参差不齐的,特别是新员工跟老员工的测试经验的差距还是比较大的。完全基于人工经验去评价的话,也会存在着判断的盲区
- 3、如果测试人员流失的话,会导致测试经验的流失。并且测试人员的精力有限,当自主测试的项目比较多的话,会比较大的影响整个这种低风险、无需 qa 跟进的测试项目的一个交付周期。
机器学习其实在现在很多实际的业务场景当中遍遍地开花,其实落地场景也非常多,
比如说:
- 原先基于人工进行决策,现在都是通过机器自己去决策的场景:
- 自动驾驶
- 智能的自检系统
- 通道人脸安检之类的
他们都是能够让机器自己去做决策,我们是否能够也让引入一些机器学习的算法,在质量场景里面让计算机自自己去做这种风险的决策呢?
以自动驾驶为例的话,自动驾驶的其实分为从 L0 到 L5,一共有六个等级,随着等级的提升,自动化程度也是同步提升的,人工需要参与的程度就会不断的降低。
- L0 的阶段是属于纯人工驾驶的这样一个阶段,是需要驾驶员完全去做所有的操作以及环境监控的
- 到 L2 阶段的时候,是一个辅助驾驶的阶段,汽车可以做部分的驾驶,比如说做一些加速减速或制动,但是驾驶员还需要随时保证能够控制这个车辆,以及做一些全部的环境监测
- 到 L3 跟 L4 的时候,就是条件自动化跟高度自动化的阶段,汽车大部分的时候都能够自动做这些,加速减速自动的操作,只在偶尔的时候我需要去关注一下,部分的环境监测
- 到 L5 的时候其实就是完全全智能的自动化,人相当于旅客。
以自动化驾驶为例的话,其实是很契合我们期望的,基于机器进行风险决策的这样一个程度的
整体方案
业务场景中也可以这样用,那我们是不是也可以把机器学习的算法用到质量评估里面,比如说:传统的完全依赖于 qa 做风险决策的,到现在我们能够基于质量度模型,去辅助 qa 做决策。未来,当能力不断的提升之后,可以达到条件自动化,或者是高度自动化的这种决策能力,甚至是完全自动化的这种能力。
实现这种自动化的风险决策,我们当前整体的方案是提出了一套质量评估系统,主要核心由风险识别、风险控制和风险决策 3 部分组成,基于这三部分,能够让机器自动去决策、自动去流程流转。
首先风险识别的部分它的主要作用是去识别一些动静态的风险,包括项目、人员、代码的变更和变更产生了影响的一些风险刻画,基于识别的这些风险,去做各种测试活动的控制和推荐。识别的风险并进行相应的测试之后,就可以去做一些风险的决策。
主要是包含两部分:
- 去看测试之后,风险还遗留了多少
- 以及万一这个风险发生之后,可能带来什么样的一个业务影响 从而最终给出一个风险的决策结论,去辅助或者全自动的去流转到下一个环节。
这三部分是如何建设的?
首先是风险识别阶段:
风险识别这个阶段,主要是解决采集数据的问题,应该采集什么样的风险数据,
以及如何采集这些数据,采集完这些不同平台的零星的风险数据之后,怎么把这些数据串联起来。
我们当前共梳理了 5 个维度,包括项目的、人员的、代码的、测试的和 bug 信息的 5 个维度,大概 50 几位的特征,然后并且通过提测单 ID、卡片 ID 和流水线 ID,这几个关联 key,把 5 个维度的所有数据给串起来。
是基于这样一个血缘关系的打通之后,我们能够拿到一个卡片的所有风险相关的数据,从而去做决策。并且能够支持,不同业务的一些自定义的一些特征数据,然后实时检索这一块。
风险控制阶段
其实主要解决的就是,需求来了,应该如何进行测试。传统的基于人工经验,执行的方式,一般是 rd 提测之后,会触发所有流水线的所有测试活动上面的用例,全部都执行完。执行完之后怎么去判断测试充不充分,大部分是直接看整体的代码覆盖率是否达标,以及挂载在流水线上面的这些测试用例是否执行通过。
如果覆盖率不达标,就需要人工凭经验去补充 case 来提升代码覆盖率,或者是说任务失败了,去做问题的排查。基于人工经验的方式,他的优点就是简单、粗暴、省事,所有的都跑了,不管风险咋样。
但是他缺点是什么呢?
1、从效能的角度来说,因为不区分不同需求、不区分不同风险,所有任务都跑、所有用例都跑,重复和不必要的执行,就会带来时间和资源的浪费。
2、从质量的角度来说,完全依赖于人工经验去,给出这个充分度的评估,那经验其实是有盲区的,特别是影响相关的很容易造成披露。
风险控制直接以风险驱动执行的模式大概是一个怎样的情况呢?
- 首先去在第一个步骤里面,去识别所有的风险,
- 然后针对于变更,比如说影响的接口、影响的场景去有针对性的去测试,能够覆盖这个变更的用例去做定制的执行,如果有覆盖不到的,甚至可以去做一些自动生成的执行。
经过这种有定向的执行之后,可以再去做定向的这种充分度的评估,包括:一次测试的输入的测试参数的组合是否充分?执行的覆盖情况是否充分?输出、断言、error 类型是充分?从而更加全面的去评估这次测试的充分度。
如果不充分,还可以给出是哪一块不充分,需要提升。去做相应的补充测试,这种以风险驱动执行的方式,他的优点就是从效能的角度来说:
- 基于识别的风险按需去执行的话,其实整个效率和利用率是大幅提升的
- 从质量的角度来说,能够去量化风险、能够去减少以人工经验去感觉上的风险,并且针对于这种量化的识别的风险,去针对性的测试可以去提升这个质量
但是他的一个缺点就是,对于底层的这种识别的能力是比较依赖度比较高,并且要去做这种充分度的评估,其实是有点复杂和难的
风险决策阶段
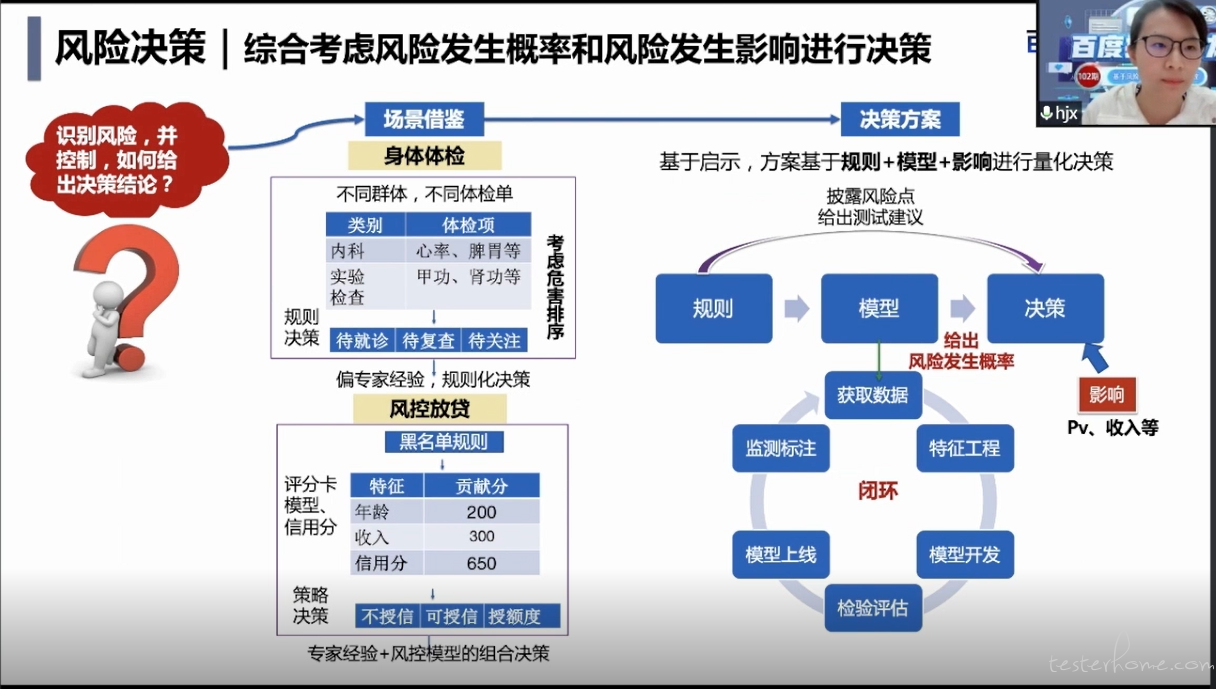
风险决策的阶段主要解决的问题是识别的风险并进行控制之后,如何给出这个决策的结论?先来看一下现实生活中的场景,感触会比较深。主要举了两个例子:一个是身体体检、一个是风控放贷。
身体体检,去做这个身体的风险的预警来看的话:
我们会针对不同的群体,有不同的体检单,比如说男生跟女生的体检单可能不太一样
然后每个不同的体检单,体检上也会有区别,针对不同体检项的结果会去根据体检项产生的危害程度,在体检报告上分类型去做这种决策的推荐。比如说这项是需要带就诊的?还是带复查的?还是带关注的?
他整体是偏专家经验的这种规则化的决策。
风控放贷,决定一个人可不可以放贷,放多少额度:
首先会去过一个黑名单的规则,来看一下这个人他的年龄没有达到 18 岁?或者年龄已经八九十岁的?可能直接通过黑名单的机制,就不会给他放贷。
那么没有命中规则的这部分呢?
就没办法再通过一些确定性的规则去给出结论,
那就依赖模型,抽取每个人的一些基础特征,或者是附属的一些特征丢给模型去训练,从而给出一个信用评分。就像蚂蚁芝麻信用分,那基于这个信用分,来去决定是否给这个人授信不授信?以及他的授信额度?那整体风控放贷的这个模式,其实是专家经验加分控模型的这种组合决策的方式。
基于两个实际场景,我们当前质量评估上面的方案,主要就是基于规则、加模型、加影响进行量化决策。首先是规则加模型,会去给出风险发生的概率,然后再结合这个该风险发生之后可能会产生的影响损失,共同做最终的一个决策结论。
这个风险决策过程,主要涉及到两个重要的部分
1、风险发生的概率的一个评估
2、已经知道了风险发生概率
也知道问题发生可能造成的影响,那怎么给出这样一个决策结论?
风险概率模型是怎么建设的
一个测试任务,是否有风险以及风险概率的大小本质上是一个二分类的算法
比如说分类的算法
就像现实场景,给你一批西瓜,去提取西瓜的各种特征,然后再来一个西瓜能够通过模型去验证,预测说这个西瓜是好瓜或者是坏瓜。大概是这样一种算法
分类的算法的话,算法类别有很多,就像第一个实验一里面列举的,
具体选哪一种算法?主要是从三个角度,
- 首先是从实际到我们业务测试数据的效果来看他效果是怎么样的。
- 然后就是这个模型需要可解释。因为如果是给出决策结论的时候,qa 或者 rd 能够知道,为什么给出他是可自测或者可无人值守的这样一个结论的,或者给他拦截了之后,需要去给他披露说为什么你拦截了。所以对于模型的可解释性要求比较高的。
- 第三块是因为我们质量的数据量其实是比较少的,然后对速度又要求比较高,然后模型是不能太复杂的。如果数据量少、模型太复杂就会很容易出现拟合。
基于上面的三个考虑,最终选择逻辑回归作为分类的模型。

θ表示权重
x 表示选择的特征
比如说:x1 是一个开发时长,X2 是一个变更函数类似这样的一些特征。
给模型输入的特征就是风险引入跟风险移除的各种维度的一些特征灌给模型去学习,模型效果的一个评估,因为是一个分类算法,所以典型的评估结论就是正确率啊、准召率这些指标。
风险决策给出决策结论
要在有限的时间去发现高风险的 BUG,所以测试的本质其实就是在于规避的风险,减少风险发生的概率和发生问题所造成的影响。
风险矩阵是统计学上很经典的一种综合两者的风险评估分析的方法,y 轴是风险发生的问题的一个概率,x 轴是问题发生产生的危害,交叉的区间里面,就是有不同的结论了:
- 红色这一块是代表他的伤害事件发生是可能性极大,并且任何情况都会出现,这种肯定是要拦截的
- 针对于会发生少量的伤害事件但是可能性极小的、或者压根就不会发生,但是在极少特定情况下可能会发生,这种就会通过,无人值守直接就流转或者由 QA 确认之后再进行流转
风险可视化报告

有了风险识别跟控制决策之后,需要有一个统一的出口让 QA 去看整体的风险决策的内容,所以会有一个风险的可视化报告,包括:
- 风险的数据
- 决策的结论以及反馈的建议
还会有一个入口能够让 QA 进行反馈,整个反馈闭环的一个流程大概就是,人工去反馈,再结合后续的环节去看有没有 BUG 的反馈,结合这些反馈之后,我们会去提取整体的优化路径。优化路径提取完之后,会去看这个优化路径,里面有哪一些特征需要提取,提取完之后灌给模型去迭代,然后再到下一轮的模型上线落地,然后再反馈这样子。
落地效果
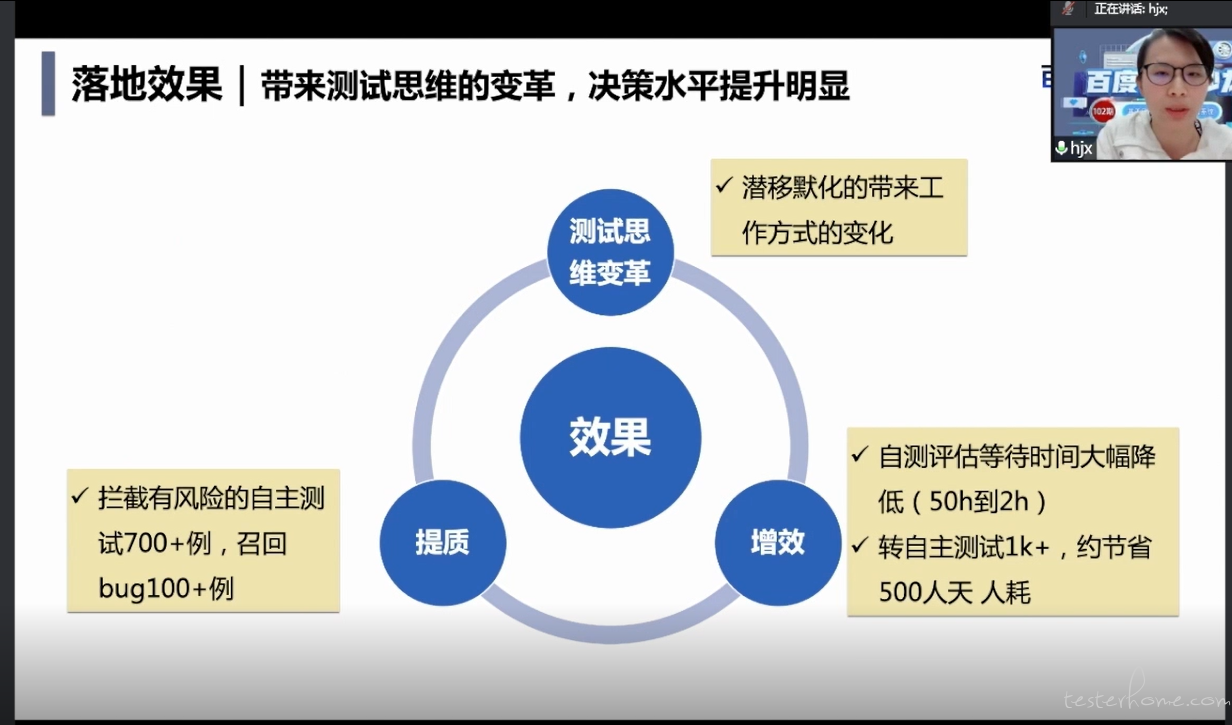
首先是提质这一块,拦截有风险的自主测试大概是 700 多例,人工可能一开始评估是可自主测试的,但是通过模型的评估,觉得是有风险的,可能会存在 bug。然后 QA 再去补充测试之后,可以召回大概 100 多个 bug。
从效能的角度的来说,整个可自测项目的评估等待时间是大幅降低的,也就是之前很多自测项目是等着 QA 去做那个评估、确认之后,才能向下一个流程流转,但是结合应用上了这种基于质量度的这种评估的方式之后,整个的等待时间从 50 个小时降到了两个小时。
之前的话人工评为是不可自测的,就是 QA 需要跟进的,但是经过模型评估之后,可能觉得风险很低,就将其转成了自主测试项目大概 1,000 个
,约节省了 500 多天的人耗。
总结
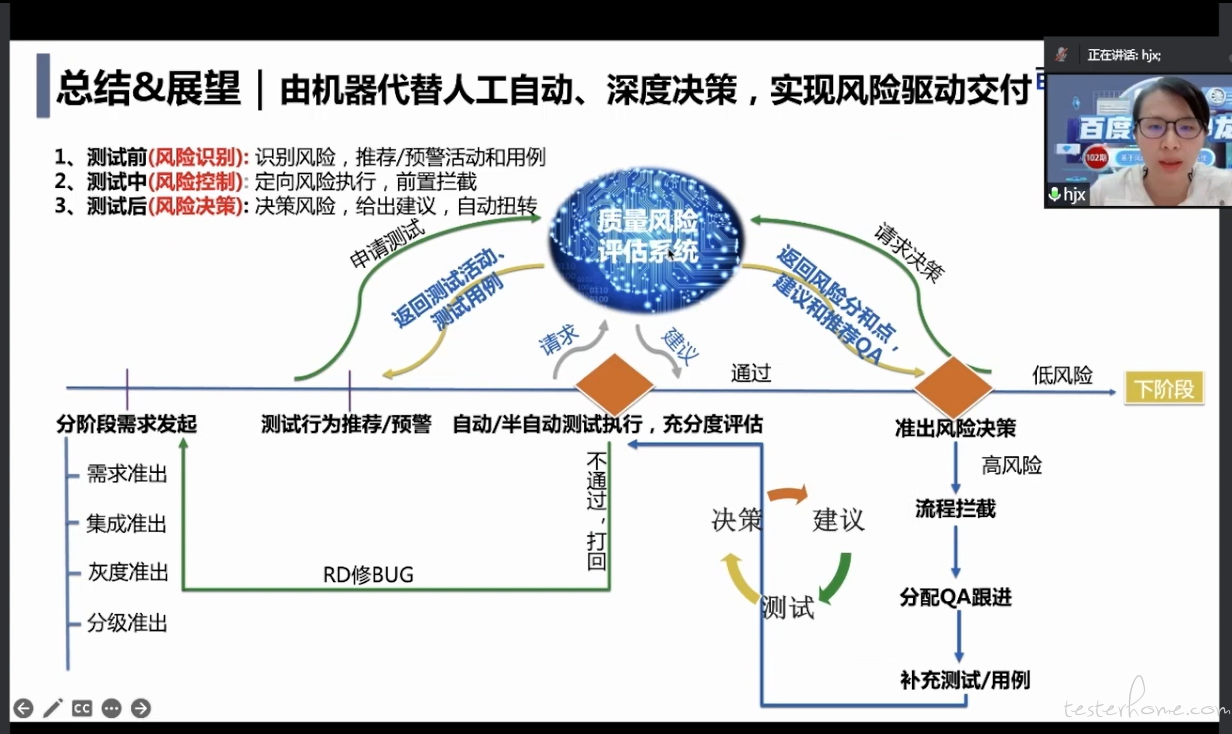
基于质量风险评估系统主要包含的风险识别、风险控制和风险决策 3 个部分。这三个部分,我们现在能力建设还有很多不足的地方还需要完善,如果是类比自动驾驶的 L0 到 L5 的层级来说,当前处在辅助决策的这一决策。后续的话,我们会去不断的完善、深耕这 3 块所需要的能力。往那个条件的自动化跟高度自动化这个靠,期望未来能够实现完全自动化决策的这种能力。
当能够实现完全自动化的这种决策能力的话,整个未来的智能交互系统,可能是这样一个的流程。
发起需求,请求质量评估系统,质量评估系统来告知应该进行什么样的测试活动、测试用例甚你应该由谁来执行这个测试。在执行的过程中会,请求质量评估系统,检查测试充不充分?有哪里还不充分,如果执行一半已经够充分的话,可以给出终止建议。那试完成之后,请求质量风险评估系统,返回是否还有遗留的风险点没有测?还需要补充哪一些测试?给出一些拦截建议,比如说高风险拦截之后去分配复位跟进然后去补充测试用例,再做测试。或者如果是觉得测试不通过的,就会打回让 RD 再去修复重新提测,如果是低风险的话,可能就自动流转为下一个集成阶段或者是分期发布阶段,减少人工参与,只有高风险的项目上才需要去拦截由 QA 去跟进。