测试覆盖率 Java 系语言测试覆盖率的半个解决方案
1 个多月前在社区开源了自己的一个 JVM 测试工具,然后看大家可能比较关注与其相关的测试覆盖率功能,所以我决定花点时间把这块功能单独拿出来详细分享给大家。
先把之前的帖子和工具链接贴一下,可以先看链接,也可以直奔下文
之前的帖子:JVM 的测试工具
开源工具:remote-debug-agent,wiki 中也有对测试覆盖率的详细说明。
首先要做一些限定说明
- 仅限 Java 或其它 JVM 系语言。因为测试覆盖率跟具体的编程语言密切相关,我也只对 JVM 系的语言有研究,如果您想看别的语言的解决方案,还得另寻高明。
- 只讨论后端程序的覆盖率。
- 适用集成测试。关于单元测试的覆盖率请直奔Jacoco。
- 适用增量开发,增量测试的系统。
为什么不用 Jacoco
其实是对上面 3、4 两点做一些说明。不是说 Jacoco 不能用于集成测试,只是每个工具有每个工具的特点和局限性。从我自身的实际经验来看,集成测试有一个问题是我比较关心的,那就是 一般集成环境只有 1 个,多个需求会同时放上去测,可能每个测试人员也就负责 1、2 个需求,我如何知道具体某一个需求的覆盖率? 仅靠原生的 Jacoco 似乎难以解决这个问题,因为它默认只为整个系统的代码生成一个覆盖率报告。
单元测试和 Jacoco 的思路是一个质量保障的理想方向。一个系统一次 build 确实应该把所有的功能测试一遍。但理想很丰满现实却很骨感,也许真的有利害的团队能做到这点,但就我自身的实际情况来看,我们离那种境界还差得很远很远。
我们大部分时间是对一个已上线系统进行优化/补丁开发,然后系统整体很庞大,功能很多,别说集成阶段的手工测试了,就算是用上自动化测试,也不可能把所有功能都跑一遍。为某个需求写的单测案例,也顶多在该需求开发的时间点附近可以跑起来,远达不到长期反复测试使用的需要。
近年来的系统微服务化确实可以在一定程度上缓解单一系统臃肿问题,但服务数量的增加,也会让服务关联变得复杂,有时在单测环节想把以前的案例都跑一遍,却发现写 mock 都要写断手。
此外集成环境还要面对稳定性问题,比如频繁的发布重启。我的需求发布后,我才测了 30%,系统就因发布重启了,一重启 Jacoco 就生成了一份覆盖率数据,那么我测试整个需求所覆盖的代码就会存在于多个 exec 文件中,如何整合整个需求测试时覆盖了哪些代码也是一个难题。
OK,说了那么多,这里先坦言一下,我的工具也不能解决上述所有问题,但 1、至少解决了部分问题;2、给剩下的问题也提供了解决它们的 “接口”。这也是标题所写 半个解决方案 的原因。
最终的解决方案是完全可行的,因为我目前正在自己的实际工作中,依靠本方案为团队提供单一需求级的测试覆盖率报告。
正文
关于我的工具本身的介绍请看前面的帖子,或者看 Github 的 wiki,帖子里是简介,wiki 上我写得很详细。这里我只介绍与测试覆盖率相关的内容。
部署
下载或编译工具后可以得到一组 jar 包,remote-debug-agent.jar 就是工具本体,其它是关联 jar 包。首先将所有 jar 包放到服务器的任意目录中,然后工具是作为 javaagent 运行的,所以要修改被测应用的启动命令(如果不想修改启动脚本也可以使用热部署的方式,详见 wiki),需要将-javaagent 参数添加到 JAVA_OPTS 中。
举个例子,假如你的被测系统中的代码(你想要关注覆盖率的代码)都在 com.foo.bar 这个包底下(或其子包底下),那么就添加-javaagent:${你的目录}/remote-debug-agent.jar=includes=com.foo.bar,apiport=8098到 JAVA_OPTS 中,之后就可以正常启动应用了。
应用启动后 agent 就默认处于工作状态了,本工具有 2 种工作模式:线程隔离模式和非线程隔离模式。
线程隔离模式
这是工具默认的工作模式,它会将 JVM 内的线程与请求调用者的身份进行绑定,之后再记录覆盖率。举个例子,A 测试员测试需求甲,B 测试员测试需求乙,他们同时在一个集成环境上做手工测试。A 点了一个按钮,运行了后端的代码 com.foo.bar.Class1.method1(),B 点了另外一个按钮,运行了代码 com.foo.bar.Class2.method2(),那么 agent 的记录就是 A 覆盖了 method1 的某几行,B 覆盖了 method2 的某几行。一般情况下也就可以认为测试需求甲和需求乙时分别覆盖了哪些代码。
这里要说明两个问题
- 对于工具来说,A 和 B 的身份是什么?本工具的设计理念是尽量减少对测试人员的影响,因此测试人员只需要正常的执行测试即可。他们发送到服务器后端的请求是未经过任何装饰的,所以工具默认使用客户端 IP 作为身份标识,在我的工作环境中,大部分系统的集成环境都部署在公司内网环境中,而测试人员的办公电脑 IP 都是固定的,这样 IP 地址就是人的身份标识。当然也有一些系统可能部署在互联网环境,或者有的人的办公 IP 不是固定的,我提供的解决思路是从请求中提取其它可标识身份的信息,比如 HTTP header 中的一些信息。因为这就是非常定制化的操作了,所以对于这种情况工具并未直接支持,只是提供了很方便的定制化开发接口,允许使用者可以在一定程度上改变 agent 从 HTTP 请求中提取身份标识的行为。
- 身份标识与线程的绑定是怎么做的?这跟开发使用的具体架构和技术有关,但不管什么技术,我们都可以把一个请求从发起到回送响应的整个过程看成是一段旅途,从 A 点旅行到 B 点可能有多条路线,但只要确定了旅行方针(web 架构技术),就总能确定一些必经之路。比如使用 Servlet 架构的应用,那么请求肯定会走 HttpServlet.service() 方法(或其子类重写的同名方法),那么探针就是在该方法的进入和退出时,进行身份标识与线程的绑定和解绑。工具默认支持了一些架构,对于 Java 用得较多的 Servlet 架构也提供了一些定制化支持的接口。当然如果这些不能满足你的要求,也可以留言给我,有空我可以扩展工具支持的架构。
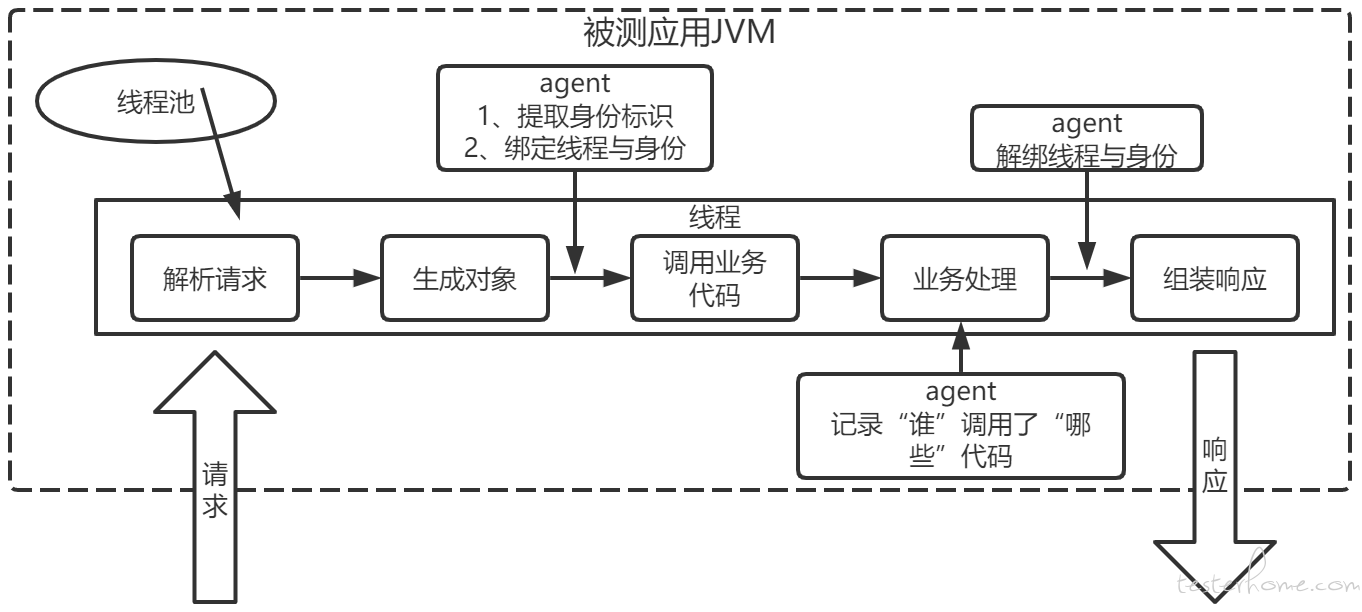
这种工作模式适用于我目前所处工作环境的大多数情况,当然也可能不可避免的漏掉一些代码,比如位于 servlet“前端” 的 filter 中的代码,因为在执行 filter 中的代码时,线程还未与任何身份标识绑定,agent 就不记录这里的覆盖率。如果你统计时不想漏掉这些代码,也可以使用非线程隔离模式。
非线程隔离模式
在-javaagent 的参数中增加dependIP=false即可让 agent 工作在该模式。该模式下 agent 就会无视线程绑定这个条件,完全记录 includes 指定范围内所有代码的运行。缺点就是无法区分某一行代码是谁执行的。对于我来说这在某些情况下依然适用,比如某个时间段,某个系统只有 1 个人测试的时候。
数据
以上说的是 agent 如何将覆盖率数据保存在其内存中,下面说明一下我们如何得到这些数据(文件)。
与 Jacoco 类似,工具在启动后会给 jvm 虚拟机注册一个关闭钩子,当 jvm 正常关闭时,会将覆盖率数据写入 1 个元文件中。该文件默认位于 agent jar 包所在目录,可通过 outputdir 参数指定输出目录,例如outputdir=data则会在 agent jar 包所在目录中新建 data 目录,将元文件存放在其中。如果指定的值以 / 开头,工具会将其视为绝对路径。
注意 jvm 关闭钩子仅在虚拟机正常关闭时起效,因此不要使用 kill -9(linux 系统中)或点击窗口关闭按钮(windows 系统中)来停止应用,应使用 kill/kill -15(linux 系统中)或 Ctrl+C(windows 系统中)来关闭 jvm。
另外也可以发送http://ip:8098/manage/dump请求来主动落盘覆盖率数据。发送http://ip:8098/manage/clean则可以清空已记录的覆盖率数据(释放内存)
元文件保存了什么
工具使用了 3 个 Map 对象来记录覆盖率数据
-
调用方法表:
Map<String, Set<String>> methodMapKey 为调用者身份,Value 为该调用者执行到的方法签名。当启用dependIP=false参数时,该表只有一个元素,Key 值为 999.999.999.999
-
方法行号表:
Map<String, ArrayList<Integer>> methodsLine,Key 为方法签名,Value 为该方法的行号表。
-
覆盖率表:
Map<String, boolean[]> methodCoverKey 为 IP&Method,即调用者身份和 Method 签名用 & 符号连接组成的字符串,Value 为该方法每行被执行的情况。
举个例子,假设一个方法如下:java public double getNumber() { double r = Math.random(); System.out.println(r); if(largeThanHalf(r)) { System.out.println("It's a big number"); } return r; }该方法编译后会形成 5 个代码行,那么它对应的 methodCover 的 value 将是一个 boolean[10] 的数组。每 2 个元素表示 1 个代码行的行首与行尾是否被执行到了,假设该数组的值为[true, true, true, true, true, true, false, false, true, true],则表示第 1、2、3、5 行被执行到了,而 if 分支内的第 4 行未被执行到。如果此方法的 methodsLine 表记录为[10, 11, 12, 13, 14],则实际覆盖的代码行就是 [10, 11, 12, 14]
探针通过类似如下的程序,将覆盖率数据写入元文件,因此用对应的 java.io.ObjectInputStream 按顺序读取,即可得到 3 个 Map 的数据。
ObjectOutputStream bos = new ObjectOutputStream(new FileOutputStream(f));
bos.writeObject(methodMap);
bos.writeObject(methodCover);
bos.writeObject(methodsLine);
以上便是我的工具提供的半个解决方案,下面该谈谈另外一半了。覆盖率这个东西,说白了就是一个分式,上文所述便是该式的分子,即我的测试操作覆盖了哪些代码。我们只需要把 “分母”(我们关心哪些范围的代码)以及 “除法”(生成覆盖率报告的算法)再实现了,就能得到最终的覆盖率了。而我的实际经验告诉我,在前文的限定条件下,分母和算法是非常定制化的东西,几乎没有可能给出通用的解决方案,因此后面我会以自己的思路和经验为核心,将实现这另一半解决方案的办法告诉大家。
分母
如果你们做的是全量测试覆盖,那是不用太关心覆盖率的分母的,但如果是像我一样需要的是某个需求的测试覆盖率的话,就可以通过一些手段来精确化测试覆盖率报告的范围。
一个比较常见的做法是,根据需求的改动来划定分母,这在需求改动的代码边界比较清晰时适用。这块程序的实现,与具体的测试计划管理、代码库管理、配置发布管理有关,你的目标效果应该是:给出任意时间点,都可以定位到集成环境中的某行代码,对应代码仓库中的哪个源文件的哪一行上。为此你需要:
- 规范代码仓库的日志。应能够从提交、合并等操作的日志中关联到具体的需求。要能从开发流上分析出某个需求改动的代码,也要能跟踪到这些代码在集成流上的具体位置。
- 做好发布管理。找地方记录每次发布的代码在仓库中的版本号,以便未来给出任意时间点,都可以知道集成环境中的代码是哪个版本的。
- 版本合并算法。这应该是集成测试与单元测试最大的不同之处。试想一个需求,你测了 50% 结果发现了一个阻断性的缺陷,开发大改后,原来已测试通过的功能对应的代码也变了样,那么这些功能还得再测一遍吗?不回归的话报告里是把这部分代码标红还是标绿呢?这恐怕不是一个简单的 Yes 或 No 的问题,我也没有标准答案。目前我的做法是通过一些算法,尽量去找目标代码在一个文件多个版本中的位置。比如一个需求在开发流上改了某文件的 1 段代码,测试执行持续了 2 天,这 2 天该文件在集成流上的版本变了一次,记为两个版本 A 和 A'。如果这段改动,在 A 中能找到,但在 A'中只找到了部分的话,那么就把能找到的这部分视为分母,未找到的部分则忽略掉(视同开发未修改这一部分)。
这个做法不能说是个很好的办法,仅供各位参考吧。当然这种情况的出现概率应该不是很高,大家也不要把它单纯的视为算法问题,也可以从管理、开发计划方面降低这种问题的影响。
你可能已经注意到了,我的做法简单来说就是改哪测哪,很明显这不是一个充分的测试策略,但我们可以将这种策略下的覆盖率数据视为一个兜底条款。实际工作中,你肯定会给覆盖率设定指标,那么标准可以相对设高一些。当然我没法给出具体的推荐值,我个人认为 60%~90% 区间内的任何值都是合理的,这跟很多因素有关,除了测试质量外,可能还有业务重视度、开发代码规范(保护性代码、自动生成代码等)等多个因素影响。具体数值还请大家自己摸索。
除法
计算问题
分母和分子都有了之后,就可以将两者进行比对了。先举个例子:某需求修改了某 1 个文件的 11,12,15 行,从覆盖率元数据中分析出,该文件对应的类执行了 10,11,12,13 行,那么最终报告里,你可以将 11,12 行标绿色,15 行标红色,其余不染色(不关心),整个需求覆盖率为 2/3。
这一步是纯粹的算法问题,你的目标应该是:以代码的行号为核心,看分子的行号记录中,有没有分母的行号。为此你可能需要:
- 上一步分析出来的分母的行号,还需要与 methodsLine 做交集,才是最终应覆盖的行号。因为并不是每一个源代码的行都会被编译为 class 文件 code 属性中的一行。
- 注意分子中的数据是以方法为单位的,你需要先将一个类里的所有方法都找出来合在一起,再跟分母进行比对。
- 覆盖率元文件中的 methodsLine 可能不是顺序的,需要整理后再比对。这与 class 文件的指令结构有关,需要对 class 文件结构,或至少对行号表有所掌握再处理。
- Java 源文件与 class 可能不是一对一的关系,小心处理内部类(包括匿名类)。
- 与分母类似,多个 class 版本依然涉及合并算法,但这里只需要累加比对结果即可,相对比较简单。举个例子:某文件测试期间有 2 个版本,分母分析结果为,A 版本需求改动行为 11,12,15。A'版本改动行为 18,19,22。分子中,A 版本的 class 执行到的行为 11,12。A'版本执行到的行为 22。那么最终报告里你可以将 A'版文件的 18,19,22 行均标绿(一般最终报告以最新版本的文件为展示基准)。
这一块理论上来说我可以像分子部分一样,直接给出解决方案(程序代码或工具),但因为 1、这部分与我开源工具的本来的功能是完全解耦的;2、有一些算法说实话我也不是很确定正确性,比如循环语句的代码行号如何处理(你可以用 javap 命令反编译一个有循环语句的 class 研究一下行号表看看)。所以最终还是决定仅提供思路。
报告展示
最后就是像 Jacoco 一样,生成可视化的染色代码报告就行了。
这里我自己仿照 Jacoco 的风格,用 freemarker 写了一个模板。
<html>
<head>
<META http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>测试覆盖率报告</title>
<style>
body {
margin: 5px 15px 5px 15px;
padding: 0;
border: 0;
}
h3 {
text-align: center;
}
span.cover{
background-color: #ccffcc;
}
span.part{
background-color: #ffff80;
}
span.uncover{
background-color: #ffaaaa;
}
#footer {
margin: 0;
padding: 0;
width: 100%;
height: 20px;
}
div#optPanel{
border: 1px solid #ccc;
border-radius: 16px;
padding: 4px 8px 4px 8px;
float: right;
cursor:pointer;
}
div#optPanel:hover{
border: 1px solid #ccc;
border-radius: 16px;
padding: 4px 8px 4px 8px;
float: right;
cursor:pointer;
background-color:#87CEFA;
}
div#code{
margin-left:25px;
margin-right:25px;
border: 1px #bbb solid;
height:600px;
overflow:auto;">
}
</style>
<script type="text/javascript">
var locations = [];
function next(){
var div = document.getElementById('code');
if(locations.length==0){
analyseCode();
}
var i;
for(i=0;i<locations.length;i++){
if((locations[i]-5)*20>div.scrollTop+600){
break;
}
}
if(i==locations.length){
i=0;
}
var jumpStep = (locations[i]-5)*20;
div.scrollTop = jumpStep < 0 ? 0 : jumpStep;
}
function analyseCode(){
var div = document.getElementById('code');
var codeNode = div.getElementsByTagName('code')[0];
var strArray = codeNode.innerHTML.split('\n');
var i, sindex;
for(i=0;i<strArray.length;i++){
if((sindex=strArray[i].search('<span class='))>0){
var lineNumber = strArray[i].substring(0, sindex-2);
locations.push(lineNumber);
i++;
for(;i<strArray.length;i++){
if(strArray[i].search('<span class=')==-1){
break;
}
}
}
}
}
</script>
</head>
<body>
<h3>文件: ${javaFile}, 版本: ${revision}</h3>
<h3>覆盖率:${coverRate}%</h3>
<br/>
<h4> <a style="display:${display}" href="../CoverageReport.html?req=${reqNo}">返回</a></h4>
<div id="optPanel" onclick="next()" href="javascript:void(0)"><span>下一处</span></div>
<h4>Coverage</h4>
<div id="code">
<code style="white-space:pre;line-height:10px;font-size:13px;">
${code}
</code>
</div>
<h4> <a style="display:${display}" href="../CoverageReport.html?req=${reqNo}">返回</a></h4>
<div id="footer">
</div>
</body>
</html>
code 变量就是个字符串,内容就是一个 java 文件的源代码,只是需要给已覆盖的行套上标签<span class="cover">,部分覆盖的行套上标签<span class="part">,未覆盖的行套上标签<span class="uncover">即可。关于 freemarker 的具体用法,还请自行搜索。
效果展示
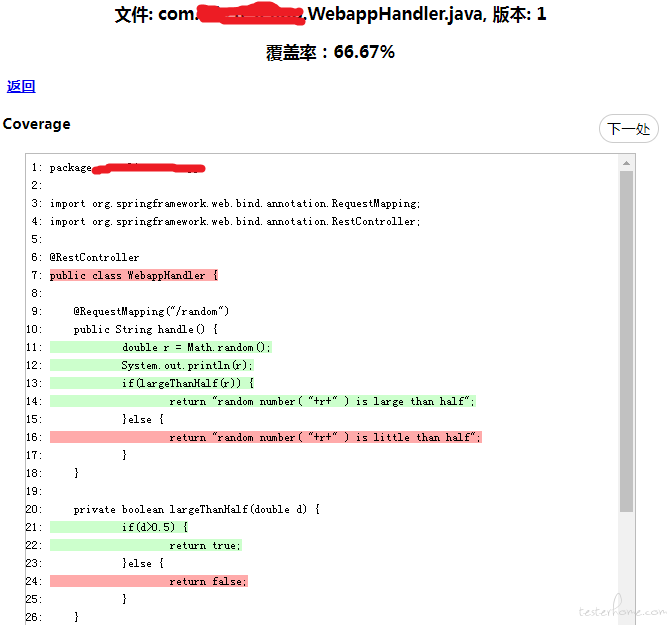
一个需求肯定有多个文件嘛,返回链接就是回到需求的整体覆盖率页面。我就简单的用个表格,把需求改的每一个文件罗列在一个页面中,这里就不贴了。下一处按钮可滚动 code 区域到下一段 “分母” 处,方便在很长的文件中查看报告。另外我在 code 变量中生成了行号。
总结
本文介绍了关于 JVM 语言的 web 应用,集成测试阶段,单一需求的覆盖率统计方法。对分子部分给出了解决方案,分母与除法部分给出了思路和经验、
一个完整流程应该是:
- 部署 remote-debug-agent 工具到被测系统。
- 用虚拟机关闭钩子或 api 接口,保存覆盖率元数据到磁盘。
- 在服务器上的程序版本没有变化的前提下,如果产生了多个覆盖率文件可根据 3 个 Map 的定义进行合并,可以节省不少的磁盘空间。
- 需求代码发布集成环境,下发测试任务后,正常开展测试直到测试结束。
- 根据测试开始与结束时间,分析开发流上的修改,在集成流上的情况。确定要关注的代码的版本与行号。
- 对于开发流上的一段改动在集成流多个版本中不能都找到完全一致样本的情况,我选择用忽略不一致的部分来处理。你也可以用你自己的方法处理这个问题。
- 根据各版本的发布时间,将对应的覆盖率元文件下载到本地。
- 针对每一个版本,用分母分析结果的行号,与覆盖率元文件中的行号表做交集,确定每个版本应覆盖的行号。
- 从每一个覆盖率元文件中,找到需求测试人员执行的代码,看分母的行号是否被执行到。
- 可能需要合并多个版本的覆盖情况。
- 以测试期间最新的 1 个文件版本作为基准,绘制覆盖率报告。
从本文到实际的效果落地,确实还有非常多的路要走,如果你做好了投入的准备,那么不妨试一试,最终的效果一定成为提高团队测试质量的助力。
当然最后还有一个最直接的实现方法,那就是雇佣我帮您来完成整体的解决方案 空间中有联系方式,欢迎邮件联系(优先接受远程工作机会)。
空间中有联系方式,欢迎邮件联系(优先接受远程工作机会)。